
 Keep AI mistakes away from your customers.
Keep AI mistakes away from your customers.
Detect and remediate incorrect responses from any AI Agent — ensuring every output meets your standards for safety, compliance, and trust.

Trusted by startups and enterprises alike





Make AI Agents production-ready with the right controls.

Detect
Catch AI mistakes in real time
Automatically identify and prevent poor responses from your AI with guardrails for hallucinations, retrieval errors, documentation gaps, policy violations, malicious use, and more.
 Learn more
Learn moreREMEDIATE
Quickly fix AI and Knowledge Base issues
Empower non-technical teams with the fastest human-in-the-loop workflow to control and improve AI responses where accuracy, safety, and trust matter most.
 Learn more
Learn moreConfidently deploy high-stakes AI applications.
Maximize AI impact, minimize brand risk.
Cleanlab helps customer support teams deploy trustworthy AI that delivers results without compromising user experience.
- Escalates smoothly from AI to human support.
- Empowers teams to refine answers, sources, and guardrails.
- Moves support team safely from static to AI-powered responses.
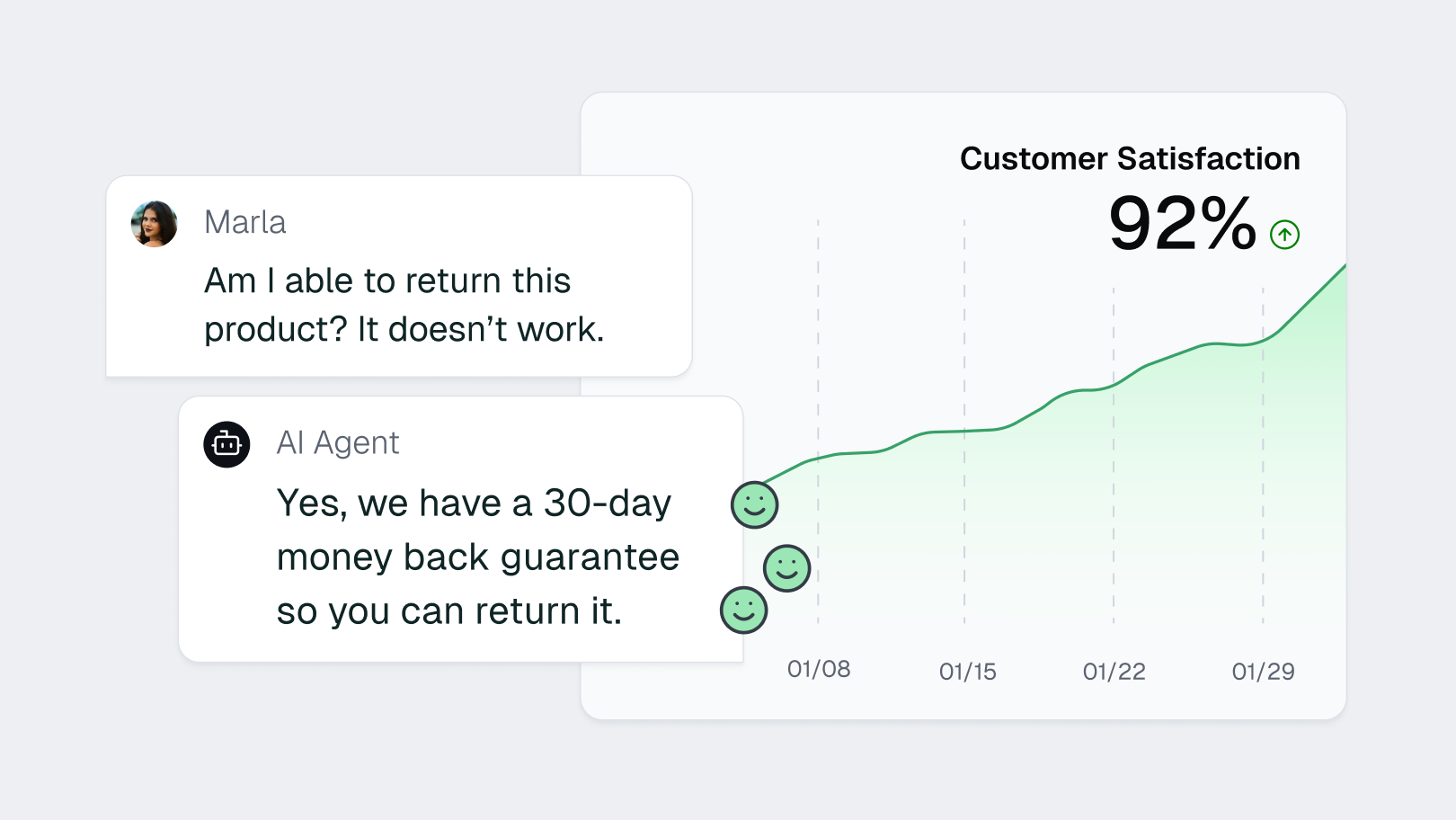
Maximize AI impact, minimize brand risk.
Cleanlab helps customer support teams deploy trustworthy AI that delivers results without compromising user experience.
- Escalates smoothly from AI to human support.
- Empowers teams to refine answers, sources, and guardrails.
- Moves support team safely from static to AI-powered responses.
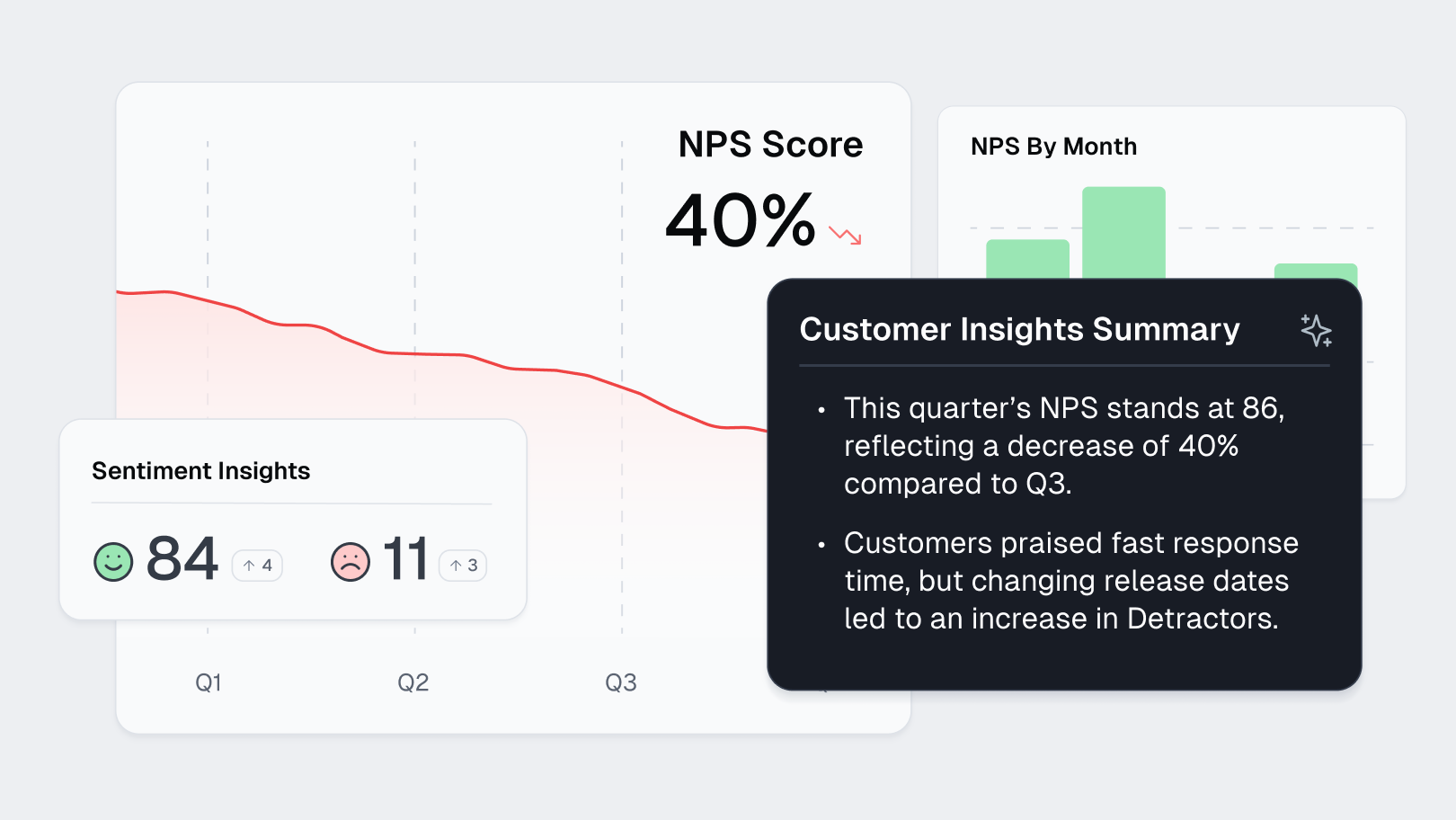
Build AI Agents that your team can trust.
Cleanlab helps you deploy reliable AI faster by reducing the time it takes to make new capabilities safe for production.
- Mitigates AI failures with real-time trust scores and guardrails.
- Empowers SMEs to improve AI apps without writing code.
- Automates safety by combining agents with human oversight.
Deployment Options
Cleanlab works with any AI system and Knowledge Base. It deploys as an independent layer that adds safety, control, and trust without requiring changes to your existing stack.

VPC
Deploy privately within your own cloud to maintain full control.

SaaS
Secure, seamless access without managing any infrastructure.








Recognized industry leaders in AI.
Cleanlab is recognized as a leading solution for reliable AI.
 2024AI 50Listed among the 50 most innovative firms driving advancements and commercial applications in AI.
2024AI 50Listed among the 50 most innovative firms driving advancements and commercial applications in AI. 2024Top AI ToolsNamed in the Top AI Hallucination Detection Tools by Analytics India Magazine.
2024Top AI ToolsNamed in the Top AI Hallucination Detection Tools by Analytics India Magazine. 2024Top AI ResearchThe IJCAI-JAIR Best Paper Prize is a top honor in AI, awarded for impactful, significant research.
2024Top AI ResearchThe IJCAI-JAIR Best Paper Prize is a top honor in AI, awarded for impactful, significant research. What are your favorite breakthroughs that will inspire the field of AI?“The Cleanlab stuff out of MIT.”Andrew Ng | Creator of Google Brain, DeepLearning.ai
What are your favorite breakthroughs that will inspire the field of AI?“The Cleanlab stuff out of MIT.”Andrew Ng | Creator of Google Brain, DeepLearning.ai