Engineering Leaders Survey – AI Agents in Production 2025
Most AI projects never make it into production. This report examines the few enterprises that did and shares what they learned about building, scaling, and making AI agents reliable enough to drive real impact.
Introduction
Following MIT’s State of AI in Business 2025 report, we set out to build on its findings about the gap between AI experimentation and production. We surveyed engineering and AI leaders across industries to understand how many had succeeded, and what was happening inside those that did.
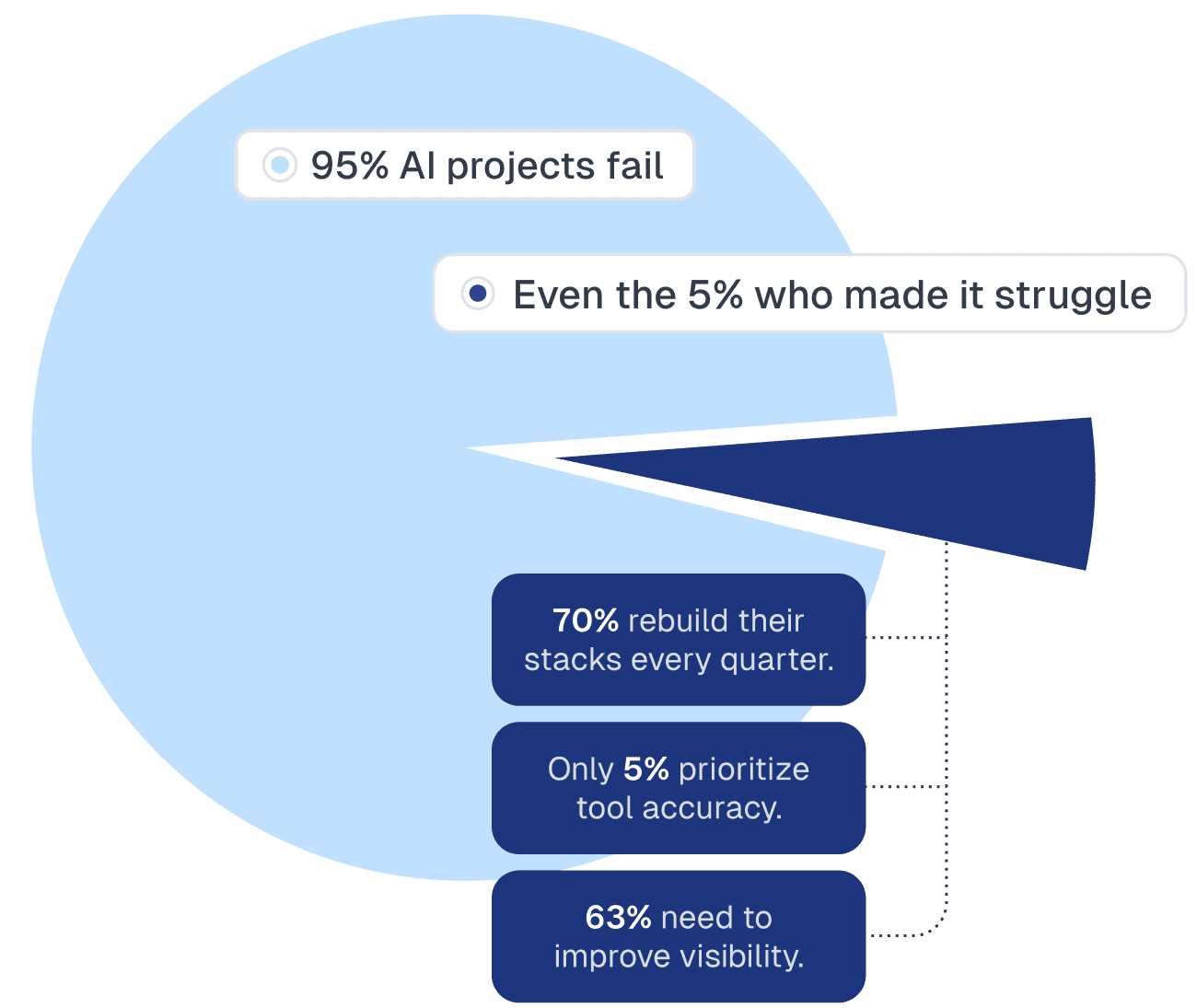
The results were more revealing than expected. The MIT estimate understated just how early the market really is. Out of 1,837 respondents, only 95 reported having AI agents live in production.
However, even within that small group, most teams are still early in capability, control, and transparency. They’re still struggling to understand when their agents are right, wrong, or uncertain.
The challenge isn’t only in the models themselves; it’s in everything around them. The AI stack keeps shifting beneath teams as new frameworks, APIs, and orchestration layers emerge faster than organizations can standardize or validate them. With every rebuild, teams lose continuity in how their systems behave, making reliability difficult to sustain.
This report focuses on those 95 leaders and what their experiences reveal about the state of AI maturity in the enterprise. It builds on MIT’s research by moving beyond adoption rates to examine what production really looks like, and what it takes to make AI work reliably at scale.
Executive Summary: Key Findings from Teams with AI in Production
The challenge is not building an agent. It is building on a surface that doesn’t stop moving.
Stacks churn quickly.
70%
of regulated enterprises rebuild their AI agent stack every three months or faster, underscoring how unstable production environments remain.
AI agents in production are still early.
Only 5%
of engineering leaders cite accurate tool calling as a top challenge, showing how little of enterprise AI is yet focused on deeper reasoning or operational reliability.
Reliability is the weakest link.
< 1 in 3
teams are satisfied with observability and guardrail solutions, making reliability the weakest link in the stack.
Visibility is the top priority.
63%
of enterprises plan to improve observability and evaluation in the next year, making visibility the top investment priority.
Governance is growing.
42%
of regulated enterprises plan to add oversight features such as approvals and review controls, compared to only 16% of unregulated enterprises.
What Production Teams Are Doing
Plan for iteration, not stability
70% of regulated enterprises update their AI agent stack every three months or faster, compared to 41% of unregulated enterprises. This churn reflects how quickly models, frameworks, and infrastructure evolve. What works in a pilot often breaks or becomes obsolete in production within a quarter. For engineering leaders, this means designing with modularity, not lock-in. One respondent described moving from LangChain to Azure in two months, only to consider moving back again. This is the new normal.
MIT found that internal AI tools fail twice as often as external partnerships. Our data helps explain why: stacks churn so quickly that in-house teams struggle to sustain them, while partnerships reduce some overhead. Yet even production teams with vendor support must rebuild frequently, showing that iteration is the norm across both approaches.

Use cases begin with documents and support
Document processing and customer support augmentation are the most common production deployments. These areas are high volume, repetitive, and ROI positive, but they also expose errors directly to users, prompting teams to start with constrained, measurable workflows before expanding to more autonomous use cases. Production teams focus on predictable tasks where impact can be tracked and iteration cycles are short. We see engineering leaders prioritize repeatable tasks before pursuing greater autonomy.
MIT’s State of AI in Business 2025 found that hidden ROI often emerges in back-office and compliance-heavy functions. Our data shows compliance use cases are less common overall, but beginning to appear more frequently in regulated industries where oversight is a priority.

Evaluation stays in-house, but gaps remain
Most enterprises rely on custom built methods to check accuracy and reliability, while fewer use third party tools. This reflects the importance of control and transparency, especially in regulated industries where leaders want visibility into how systems are judged, not just vendor assurances. But in-house methods often lack real time coverage and scalability, leaving blind spots that become more serious as agents take on more user facing responsibility.
While MIT notes the high failure rate of internally built AI tools, our data shows why many enterprises still rely on in-house evaluation: it provides control. Yet, these same teams acknowledge evaluation gaps that prevent reliability at scale.

AI agents in production are still early
Even among enterprises with AI agents live in production, most remain early in capability, control, and automation. Only 5% of engineering leaders cited accurate tool calling as a top technical challenge, one of the most surprising findings in the study.
This finding builds on MIT’s key findings, which showed that 95% of organizations are still struggling to get meaningful value from AI. Our data reveals that even the 5% that reach production remain early in maturity. Teams are still focused on surface-level response quality rather than the deeper reasoning and precision control needed for mature agents.

Hybrid approaches dominate
Few organizations rely entirely on vendors. Most combine in-house infrastructure with external tools, while regulated enterprises are more likely to fine tune open source models. The rapid evolution of the ecosystem makes vendor-only or in-house-only approaches risky. Hybrid stacks provide flexibility and resilience against changing frameworks, models, and infrastructure.
MIT emphasized that vendor partnerships increase success rates. Our findings suggest enterprises agree, since most adopt hybrid stacks that blend in-house systems with vendor tooling rather than relying on either approach alone.


Where Teams Are Struggling
Reliability is the weakest layer
Observability and evaluations are the lowest-rated parts of the stack, with fewer than one in three teams satisfied and nearly half evaluating alternatives. In-house checks give control but cannot close reliability gaps at scale. Without stronger reliability layers, production agents remain untrustworthy.

Scale changes the challenge
For smaller deployments, cost is the top concern. For high-traffic agents, latency and reliability dominate. What matters most changes as usage grows. Successful AI projects need to plan for new bottlenecks that emerge only at scale.

What They Plan to Improve
Observability leads the roadmap
62% of production teams plan to improve observability in the next year, making it the most urgent investment area. Teams increasingly recognize that visibility, feedback, and control mechanisms are central to scaling agents safely and accurately. More teams are building workflows where humans review, approve, and reinforce correct responses, a key step toward controllable and transparent AI.
Accuracy and trust are next priorities
More than half of teams plan to fine-tune or customize models and focus on reducing hallucinations. These improvements address reliability directly, since inaccurate or fabricated responses are the most visible failure modes for users. AI teams know that accuracy and trust are inseparable, and both must improve before agents can carry more responsibility.

Regulated industries add oversight
42% of regulated enterprises plan to introduce manager features such as approvals and review controls, compared to only 16% of unregulated enterprises. Governance is emerging as a hard requirement in high-risk environments.
Human controls play a similar role for AI systems as they do for people. They provide feedback, correction, and accountability. When a human employee makes a mistake, the response is to review, explain, and guide, not to remove oversight. The same logic applies to AI agents. Structured human feedback helps these systems learn what is right and wrong while preventing small errors from becoming systemic failures.

What This Means: Lessons for Engineering Leaders
1. Plan for change, not perfection
Production success is not about getting the stack right once, it is about designing for continuous change. Teams that succeed standardize on vendor partnerships for stability while keeping their architectures modular, so components can be rebuilt or swapped as models and frameworks evolve. Progress compounds when systems are designed to adapt without starting over each time.
2. Invest early in reliability layers
Weak observability and immature guardrails are the most common pain points in production. Enterprises cannot scale agents without trust, and trust comes from visibility. Prioritizing evaluation, monitoring, and safeguards is the foundation for closing what MIT calls the “learning gap.”
3. Build human governance into how agents operate
As early agents take on more responsibility, human oversight matters as much as infrastructure. Regulated enterprises are leading by adding manager features such as approvals and review controls, embedding governance directly into workflows rather than treating it as an afterthought. This shift reinforces MIT’s conclusion that organizational design, not budget, remains the biggest barrier to crossing the GenAI Divide.
Why This Isn’t the Year of the Agent
1. The industry is building on unstable foundations
Massive investment is flowing into AI infrastructure, but most enterprises struggle to integrate it before the next generation arrives. Stacks evolve faster than organizations can standardize, keeping progress fragile and fragmented.
“Billions are being poured into AI infrastructure, yet most enterprises can’t integrate it fast enough. Stacks keep shifting, and progress resets every quarter.”
— Curtis Northcutt, CEO and Co-Founder of Cleanlab
2. The way forward is human feedback
Technology alone cannot close the gap between experimentation and dependable operation. As AI agents move into production, they require the same guidance people do: feedback, correction, and accountability.
“The way to make AI agents better is the same way you develop people: through feedback. You show them what’s right and wrong, not by retraining them from scratch every few months.”
— Curtis Northcutt, CEO and Co-Founder of Cleanlab
Human oversight is becoming a key enabler for enterprises that want to manage change, not just react to it. The next wave of AI maturity will come from teams that treat feedback and oversight as part of the production process, not a safety net.
3. Most production agents are still early
Even among companies with agents in production, maturity remains low. Only five percent of engineering leaders cited accurate tool calling as a major challenge, a sign that most production systems are still focused on surface-level behavior rather than deeper reasoning or control.
“Only five percent of the five percent of companies with agents in production even worry about accurate tool calling. That tells you how early we still are; most so-called AI agents can’t reliably do what they claim.”
— Curtis Northcutt, CEO and Co-Founder of Cleanlab
This gap between perception and capability shows how much of enterprise AI remains experimental beneath the marketing. Real progress will come when production agents can perform accurately, controllably, and transparently under real-world conditions.
Methodology
This report is based on a survey of 95 professionals across industries and company sizes. Participation was limited to leaders already operating AI agents in production with live user interactions. Respondents were screened carefully to ensure their agents were not in pilot or proof-of-concept stages but were actively deployed in workflows handling thousands of real interactions. The result is a focused view into the practices and challenges of the small minority of organizations that have crossed the threshold from experimentation to real deployments.
Industries: Regulated and unregulated sectors, including financial services, healthcare, technology, and consumer markets.

Data was collected in August 2025. The results represent practitioner-level insights from teams already operating AI agents at scale, not projections or pilots.