
TL;DR: AI Agent Safety as Enterprise Infrastructure
- AI agents are inherently unpredictable because uncertainty is present at every step: interpreting queries, retrieving data, reasoning, and taking actions.
- Failures fall into four categories: responses, retrievals, actions, and queries. These failures have already caused compliance breaches, financial errors, and operational disruptions.
- The challenge for leaders is not to eliminate unpredictability, but to contain it through layered safety systems that measure, observe, and control failures.
- AI safety must be treated as enterprise infrastructure. It is what makes enterprise-scale deployment sustainable, trustworthy, and competitive.
Safety as Strategic Infrastructure
AI agents are moving quickly from pilot projects to production in the enterprise. They retrieve data, reason across contexts, call APIs, and sometimes act autonomously on behalf of the business. With this power comes a new kind of unpredictability. Unlike traditional software, AI agents generate outputs based on probabilities. That means uncertainty exists at every step, whether interpreting a query, retrieving data, reasoning through tasks, or executing actions.
Unpredictability cannot be eliminated. It is inherent to AI. The leadership challenge is whether organizations can measure, observe, and contain this uncertainty so that agents can be trusted in critical workflows.
Viewed through the enterprise lens, the risk surface falls into four categories: responses, retrievals, actions, and queries. Each is a point where unpredictability can enter, and together they define where leadership must focus.
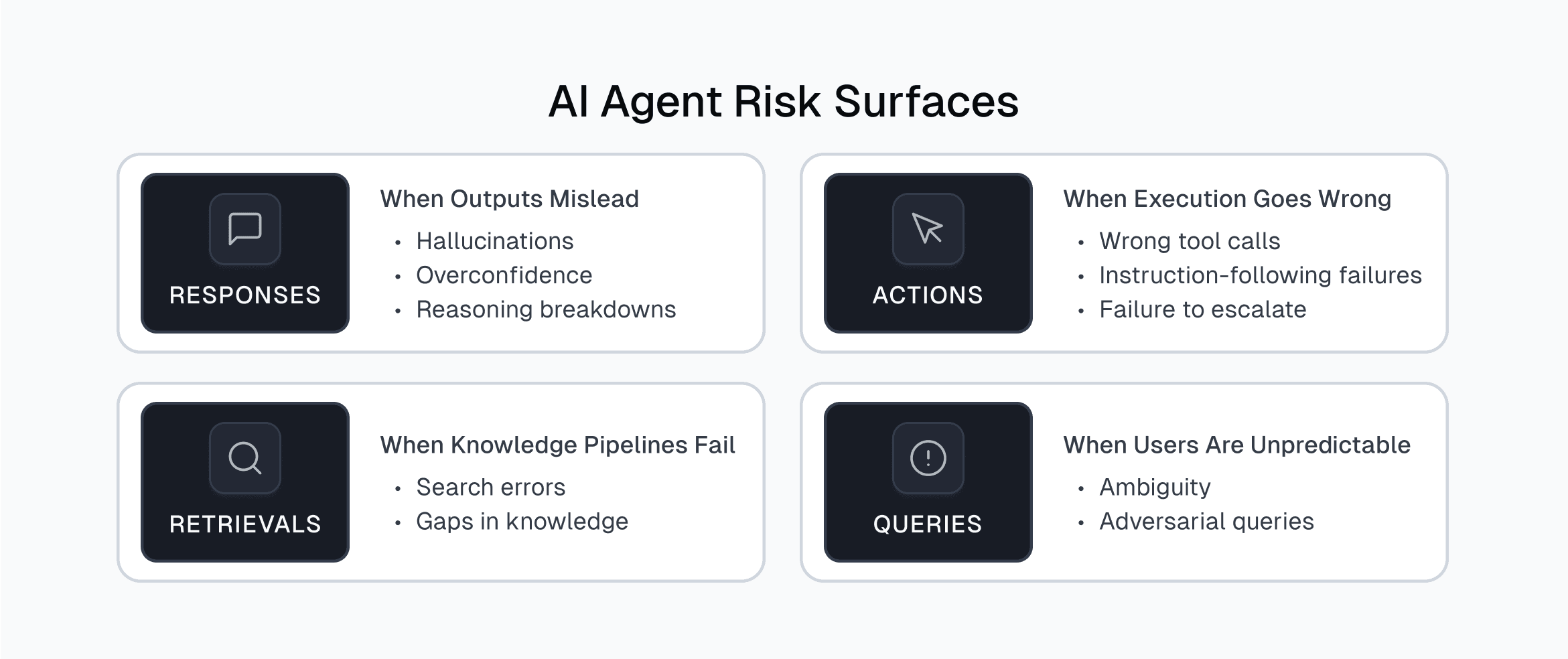
1. Responses: When Outputs Mislead
Agent responses are where unpredictability first becomes visible, and their consequences ripple into workflows and decisions. When responses are wrong or misleading, the impact extends far beyond credibility. They create compliance exposure, distort critical decisions, and slow adoption across the organization.
- Hallucinations: Agents fabricate false content that sounds authoritative. While leading models benchmark hallucination rates as low as 5 percent, studies show they can spike to 88 percent in specialized domains such as legal reasoning. In one legal pilot, an assistant cited a case precedent that did not exist. Because the response appeared professional and persuasive, it made its way into internal review and even a courtroom, escalating into liability.
- Overconfidence: LLMs often present uncertain outputs as if they were definitive. In practice, this shows up when an AI delivers an answer with apparent authority even though the underlying probability of correctness is low. For example, a healthcare triage assistant could recommend a diagnosis with certainty that is statistically fragile. If unchecked, that misplaced confidence could distort escalation paths and compromise outcomes.
- Multi-step reasoning breakdowns: Errors often creep into the middle of reasoning chains. Benchmarks such as MuSiQue show accuracy drops by 30 percent on multi-step tasks compared to single-step ones. In an enterprise finance scenario, an agent preparing consolidated results might correctly ingest subsidiary ledgers but miscalculate intercompany adjustments midway. The final report would look precise but contain material errors, exposing the organization to regulatory scrutiny and misinformed executive decisions.
Why it matters: Response failures strike at trust, the crux of enterprise adoption. They introduce liability in regulated domains, operational risk in high-stakes environments, and governance concerns that ripple across the organization.
Leadership priority: Treat response quality like audited financial reporting. It must be observable, auditable, and explainable. Include a real-time LLM output verification module. Require grounding in verifiable data, calibrated confidence levels as guardrails, and automatic flagging of high-risk answers. Where uncertainty remains, systems should route to authoritative sources or simply abstain from answering.
2. Retrievals: When the Knowledge Pipeline Fails
If responses are the surface of safety, retrievals are the foundation. Most AI agent outputs depend on what is retrieved. If the knowledge pipeline fails, the reasoning layer is compromised before it begins. Failing to retrieve accurate knowledge is especially dangerous because outputs often look correct while resting on incomplete or outdated information.
- Search errors: Retrieval can surface the wrong information even when the correct data exists. These failures stem from mismatched queries, poorly ranked results, or outdated indexes. For example, a sales assistant might return a regional pricing sheet instead of the current global catalog. The mistake would put revenue at risk not because the agent reasoned incorrectly, but because it acted on the wrong retrieval from the start.
- Gaps in knowledge: Many enterprises struggle with knowledge bases that are incomplete or stale. Consider a compliance assistant that gives conflicting answers because new regulations were missing from its knowledge store. Without reliable coverage, the agent defaults to improvisation, introducing risk in the most sensitive domains.
Why it matters: Retrieval is the foundation of reliability. If the underlying data is stale or incomplete, every subsequent layer of reasoning inherits the flaw. Failures here often remain invisible until they surface as compliance breaches, revenue leakage, or customer dissatisfaction.
Leadership priority: Treat enterprise knowledge as operational infrastructure. Establish a process by which your SMEs continuously close knowledge gaps and fix documentation errors. Implement automated freshness checks, coverage audits, and guardrails that check for response groundedness in real time. Without these safeguards, even the most advanced reasoning models will silently inherit data flaws.
3. Actions: When Execution Goes Wrong
When AI agents move from generating responses to executing actions inside enterprise systems, unpredictability escalates into operational risk. Mistakes no longer threaten only trust. They can disrupt business processes, damage data, or create financial loss at scale.
- Wrong tool calls: These occur when an agent invokes the wrong function, API, or system command. Benchmarks show tool-use accuracy often falls below 70 percent. A striking case came from Replit’s AI coding assistant, which in testing deleted a live production database despite explicit instructions to freeze code changes. Thousands of users were impacted, and the company had to rebuild safeguards. The incident demonstrated how a single misstep in execution can cascade into systemic business risk.
- Instruction-following failures: Agents sometimes ignore explicit constraints. For instance, a logistics optimizer instructed to avoid air freight for cost and emissions reasons could still schedule multiple air shipments. The issue is not a minor rework. It could violate corporate commitments, create regulatory exposure, and delay a product launch.
- Failure to escalate: Instead of handing control to a human, agents may persistently retry tasks they cannot complete. Picture an IT operations agent repeatedly attempting a network fix it cannot perform. The delay could extend downtime, trigger SLA penalties, and lock thousands of employees out of critical systems.
Why it matters: Actions are where unpredictability directly impacts business continuity. They can erase data, disrupt operations, and create direct financial or contractual exposure. These incidents elevate AI safety from a technical concern to a question of operational resilience and business continuity.
Leadership priority: Treat every agent action like a financial transaction. Apply least-privilege permissions, runtime verification of calls, and automatic escalation when confidence thresholds are not met. The system should detect and flag risky actions before they propagate into business-critical processes.
4. Queries: When Users Drive Unpredictability
The input side of AI is often underestimated, yet it is still critical to safety. Every decision an agent makes begins with a user query. If that query is ambiguous or adversarial, the system can be pushed into failure before reasoning even begins.
- Ambiguity: Queries are often underspecified, leading to misinterpretations. For instance, a finance manager asking for “last quarter’s revenue” might expect global results, while the system retrieves regional data. Without clarification, that kind of misinterpretation can cascade into official reporting and even reach a board presentation, materially misstating performance. The failure is not in the model but in the lack of guardrails to resolve intent ambiguity.
- Adversarial queries: Attackers deliberately craft “jailbreak” prompts to override safeguards or extract sensitive information. Researchers at UC San Diego and Nanyang Technological University demonstrated attacks with nearly 80 percent success in tricking models into leaking data. In enterprise settings, adversarial queries could expose hidden system prompts, leak API keys, or manipulate agents into bypassing access controls, creating both security and compliance risks.
Why it matters: Queries are the entry point for unpredictability. Without governance at the input layer, enterprises face the risk of data leaks, compliance violations, and reputational harm, often triggered by nothing more than a poorly phrased or malicious request.
Leadership priority: Inputs must be treated with the same rigor as outputs. Enterprises should implement input classification, clarification loops for ambiguous queries, and automated defenses against adversarial prompts. Low-confidence or high-risk inputs should be flagged and routed for human confirmation before execution.
Building the Layers of Safety
AI agents will always be unpredictable. Uncertainty is built into how they interpret queries, retrieve data, reason through tasks, and execute actions. The leadership challenge is not to eliminate unpredictability, which is impossible, but to contain it with the right layers of safety.
The future of enterprise AI depends less on how quickly agents are deployed and more on how predictably they perform under real-world conditions. Safety must be a living system that continuously measures, observes, prioritizes, and controls failures across responses, retrievals, actions, and queries.
Just as cybersecurity matured into a discipline of layered defenses, AI safety must mature into a discipline of layered controls. Groundedness checks and uncertainty calibration strengthen responses. Freshness audits and coverage tracking secure retrievals. Permissioning and escalation logic safeguard actions. Input classification protects queries.
Safety is not a brake on innovation. It is the discipline that makes innovation sustainable at scale. Enterprises that treat safety as strategic infrastructure will reduce risk, strengthen resilience, and gain the confidence to deploy AI agents into their most critical business processes.