

TL;DR
- Even the best AI models still hallucinate, producing confident but wrong answers
- Cleanlab’s trustworthiness guardrail detects and blocks inaccurate responses in real time
- When confidence is low, Cleanlab serves safe fallback messages or expert-verified answers to keep AI accurate and reliable in production
Even as foundation models improve, hallucinations remain a fundamental problem. They continue to produce confident, wrong answers, even from the newest and most capable systems. According to OpenAI’s Why Language Models Hallucinate, this behavior stems from how language models are built and trained.
The world’s knowledge is unevenly distributed, which means training data always leaves gaps. Those gaps widen during inference, when models face real-world questions that fall outside their training experience. The further your application moves into domain-specific or long-tail topics, the more likely the model is to make things up.
There is also a misalignment of incentives. Foundation model providers optimize their systems to sound confident and helpful, since “I don’t know” responses lower engagement in consumer settings. But for most enterprises, that behavior is backward. In production, it is far better for AI to admit uncertainty than to hallucinate confidently.
That is why hallucinations continue to appear, even in state-of-the-art models, and why they will likely persist. Until training incentives and real-world use cases align, teams will keep facing the same issue: wrong or unsupported answers that cannot be fully prevented at the model level.
Why production systems need guardrails
When these mistakes happen in production, the impact is more than technical. It is operational and reputational. A single incorrect answer can erode customer trust, violate compliance policies, or cause financial and brand harm.
Most monitoring tools can only flag these issues after they occur. But once a user sees an incorrect or unsafe response, the damage is already done. That is why production systems need guardrails that stop unsafe or unreliable outputs in real time.
Guardrails act as safety mechanisms that block or replace AI responses when they fail to meet trust criteria. When triggered, Cleanlab’s guardrails can:
- Deliver a fallback or neutral message
- Substitute a verified SME-provided answer
- Escalate the case to a human reviewer
The result is simple but powerful: users only see accurate, verified, and trustworthy responses.
The System That Keeps AI Reliable
At the core of Cleanlab’s reliability system is a trustworthiness guardrail designed to protect accuracy. It evaluates how confident your AI system is in each response and detects when an answer is likely to be wrong or unsupported.
This guardrail performs advanced uncertainty estimation to determine whether an output is likely to be correct. If a response appears inaccurate or fabricated, the guardrail automatically blocks it before it reaches your users.
Fallbacks
Instead of returning a potentially incorrect answer, Cleanlab lets you define a fallback message that provides a safe and consistent response, keeping the user experience professional while protecting your system’s integrity.
Here are a few examples of fallback responses that we’ve used with our customers:
| Scenario | Fallback Message Example |
|---|---|
| Customer Support Agent | “I’m not fully confident in that answer. Let me connect you with a support specialist to confirm.” |
| Internal Knowledge Assistant | “I wasn’t able to find a clear answer in the knowledge base. You may want to check the internal documentation for more details.” |
| Financial or Healthcare Advisor Bot | “I don’t have enough information to give a reliable answer right now. Please review this with a qualified advisor.” |
These fallback responses act as the AI’s safety net, acknowledging uncertainty while maintaining transparency and trust with users.
Expert Answers
When a blocked response needs to be improved rather than simply replaced, Cleanlab connects directly with Expert Answers. Subject matter experts can review the flagged case, provide the correct response, and store it for automatic reuse in the future. Over time, this creates a growing library of verified knowledge that makes the AI more accurate while keeping humans in control.
By combining guardrails with Expert Answers, Cleanlab gives teams both real-time prevention and continuous improvement, ensuring AI systems deliver only responses that are safe, accurate, and trustworthy.
The Most Effective Hallucination Detection
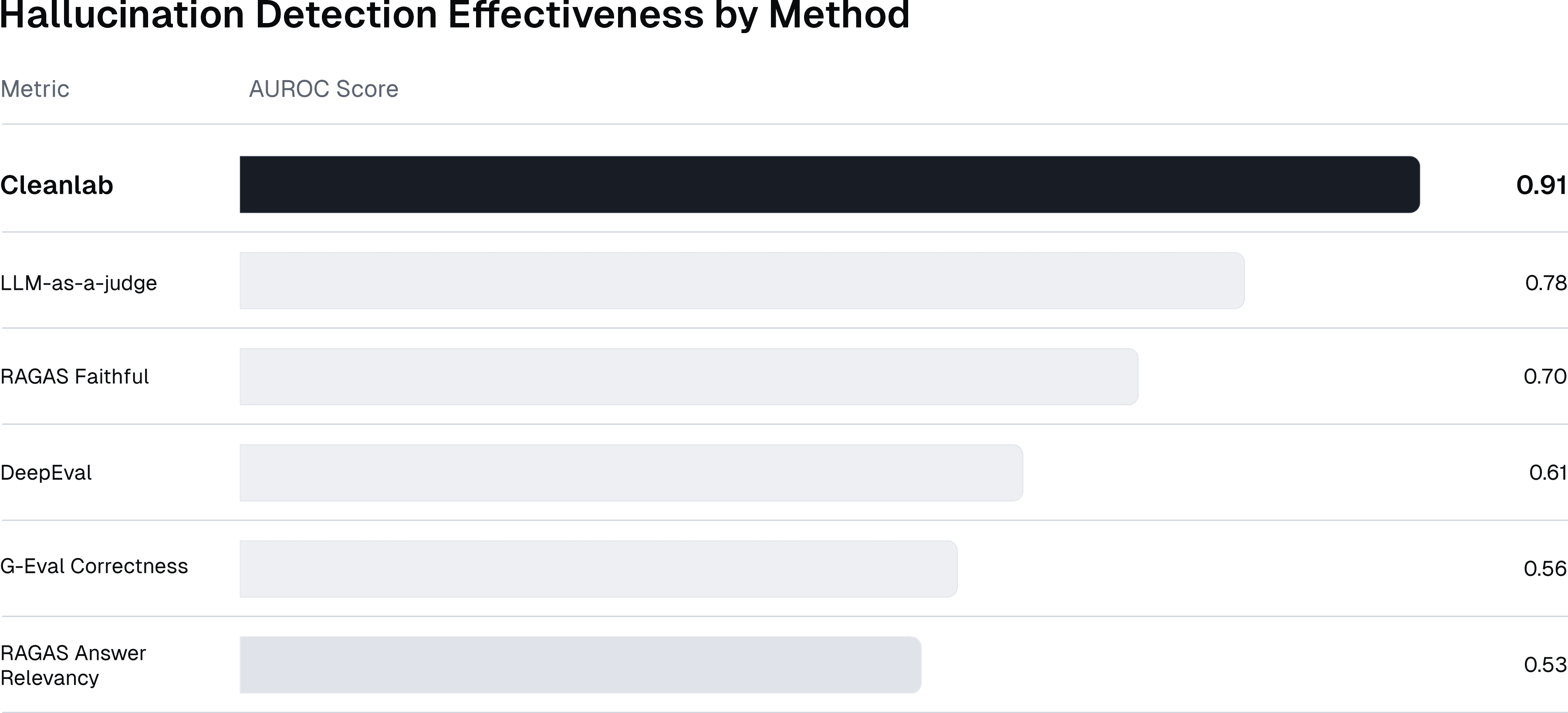
Cleanlab’s trustworthiness guardrail is powered by the Trustworthy Language Model (TLM), the leading method for detecting incorrect AI responses and measuring uncertainty in large language models.
In Cleanlab’s Benchmarking Hallucination Detection Methods in RAG study, researchers compared popular detection techniques including RAGAS, G-Eval, DeepEval’s Hallucination Metric, LLM-as-a-judge (Self-Evaluation), and TLM across four public RAG datasets in finance, biomedical, reasoning, and scientific domains.
Easy Setup: Guardrails in Minutes
Cleanlab’s guardrails are designed to be simple to deploy and immediately useful. Teams can add real-time safety controls to any AI system within minutes, without retraining models or rewriting infrastructure.
Enabling guardrails requires only a few quick steps:
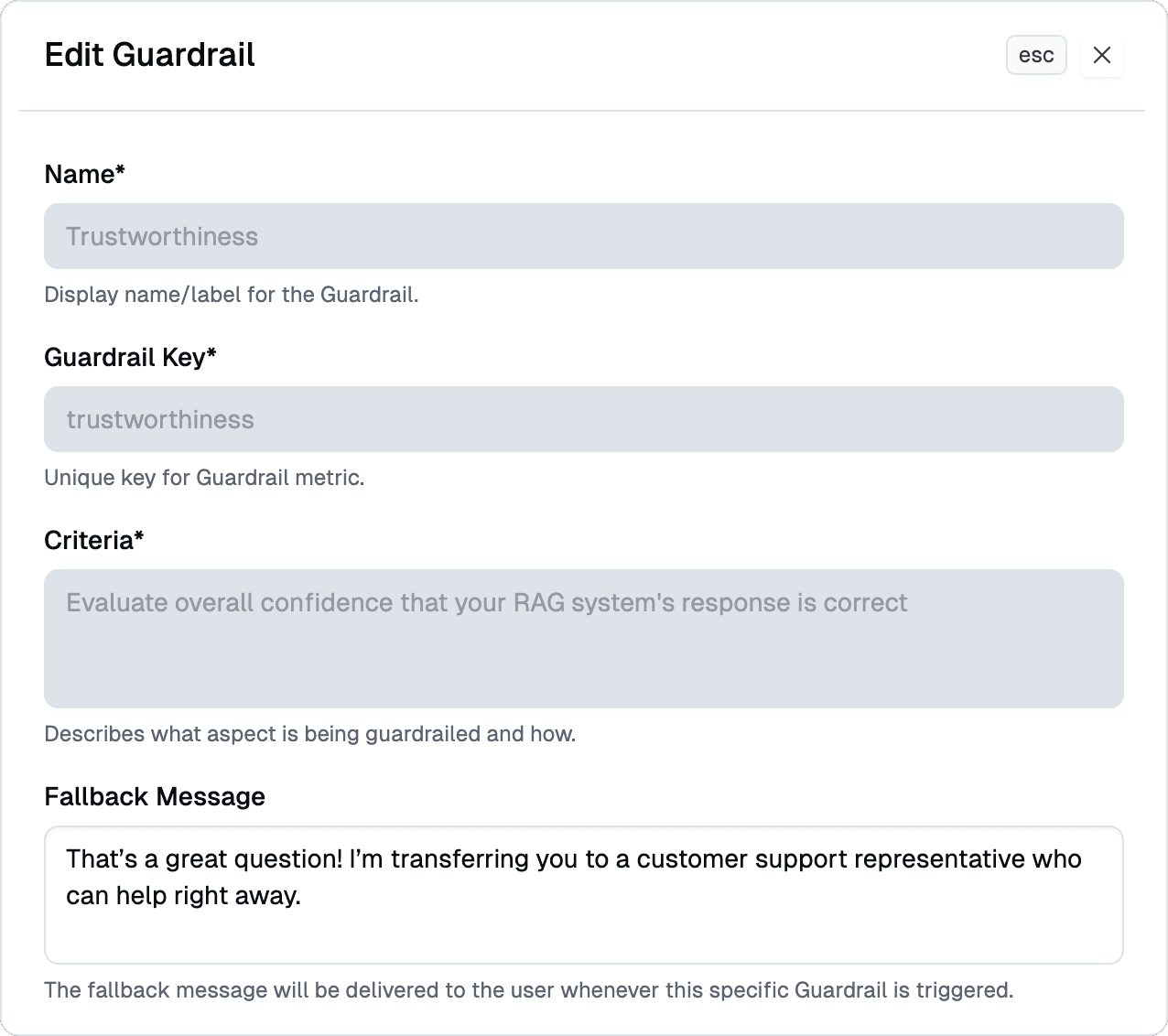
1. Enable the default trustworthiness guardrail.

2. Define a fallback message that matches your brand tone and escalation policy.
3. Start monitoring responses in the Cleanlab dashboard.
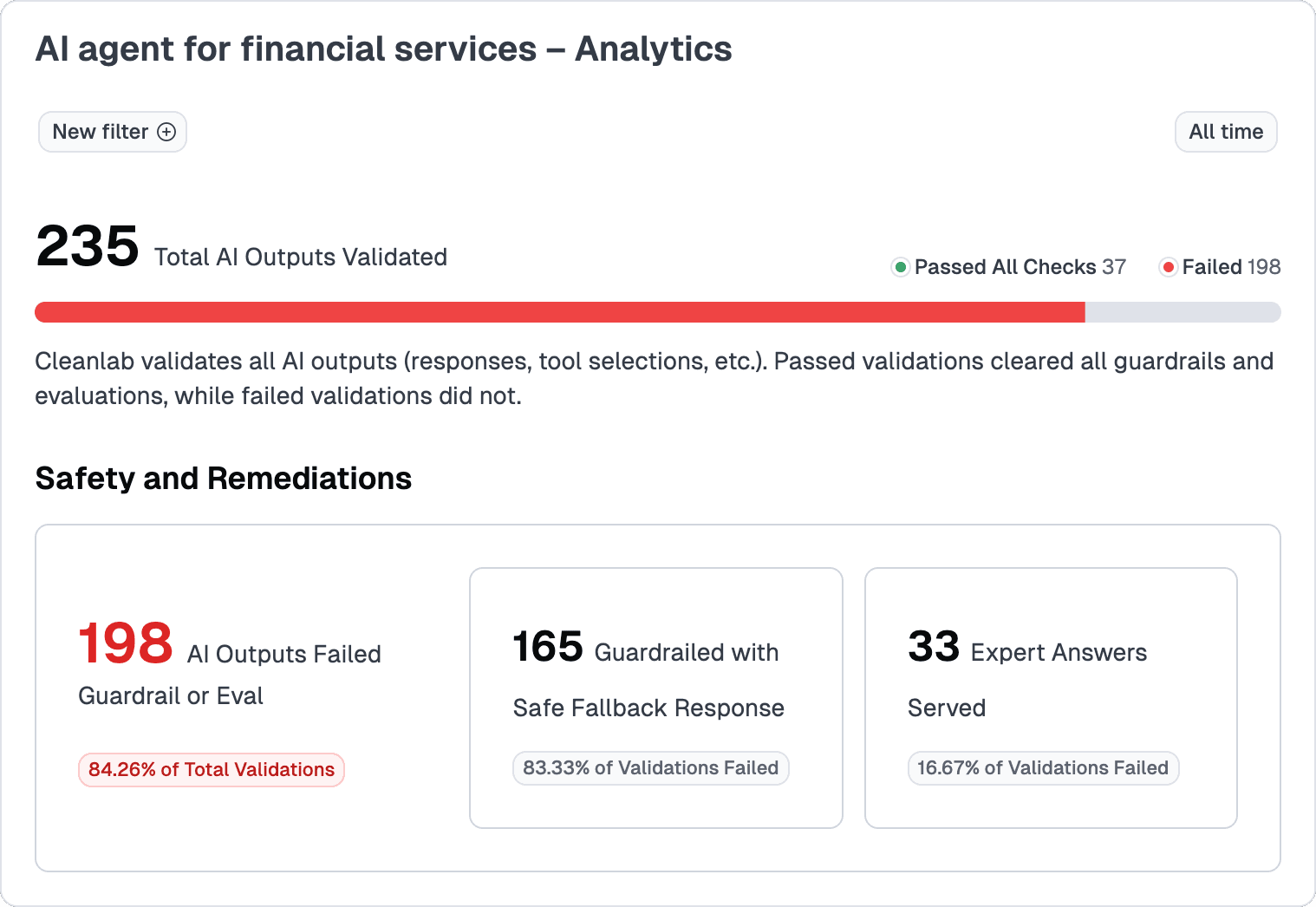
Once activated, Cleanlab automatically evaluates each response, blocks low-confidence outputs, and triggers your fallback message when needed. The process is seamless, fast, and designed for teams that want to deploy reliable AI without complexity.
Cleanlab integrates easily with existing agent frameworks and APIs, making it possible to add safety and trust to any AI workflow without additional infrastructure or model changes.
Want to go deeper? Explore our Guardrails tutorials for hands-on examples and sample configurations you can use in your own AI systems.