

While benchmarking Structured Outputs from leading LLMs, we found major errors in the provided “ground-truth” outputs across existing popular benchmark datasets. To enable accurate benchmarking, we’ve released 4 new Structured Outputs benchmarks with verified high-quality ground-truth outputs.
Existing Benchmarks for Structured Outputs
Beyond coding and customer support, some of the highest ROI enterprise LLM applications today include: (i) intelligent decision-making embedded within larger software programs, and (ii) extracting structured data from unstructured documents. Both applications critically rely on the Structured Outputs capability of LLMs.
Given the importance of LLM Structured Outputs, many benchmarks have been released for assessing model performance. In theory, comparing models should be easy — just run them on these benchmarks. In practice, we noticed that many “errors” in our LLM’s outputs were actually mistakes in the “ground-truth” output provided in the benchmark. Turns out generating accurate Structured Outputs is also hard for human annotators!
To investigate this, we ran each dataset through Cleanlab, which can automatically detect incorrect annotations. The findings were striking: every public benchmark we examined was full of erroneous and inconsistent ground-truth outputs. While benchmarks are expected to be somewhat noisy, the error-rates in public Structured Outputs benchmarks were so high that we’d place little faith in derived model accuracy estimates.
Below are some specific example of errors we found in public benchmarks. Beyond the datasets listed here, we looked through many others as well, and also found them too noisy for reliable benchmarking.
Financial Relation Extraction (FIRE)
This benchmark contains text snippets drawn from business or financial news, reports, or announcements. The task is to identify and extract specific financial and contextual entities mentioned in the text, including: Action, BusinessUnit, Company, Date, Location, GeopoliticalEntity, FinancialEntity, Sector, etc.
We found that this dataset is full of inconsistencies, where the ground truth contains certain extractions for some examples but not for other examples that are conceptually equivalent. It also has many ambiguities where one cannot judge whether an extracted output is truly correct or not based on the given instructions. Below are some examples of issues in this benchmark.
Lease Contract Review
This benchmark contains long excerpts from legal and commercial lease agreements. The task is to extract structured contract information from each document, including key entities such as the: parties involved (lessor and lessee), lease terms, payment conditions, property details, and important contractual dates (start and end dates, renewal clauses, and payment schedules).
We found this dataset to be full of annotation errors and inconsistencies. Below are some examples of issues we found in this benchmark.
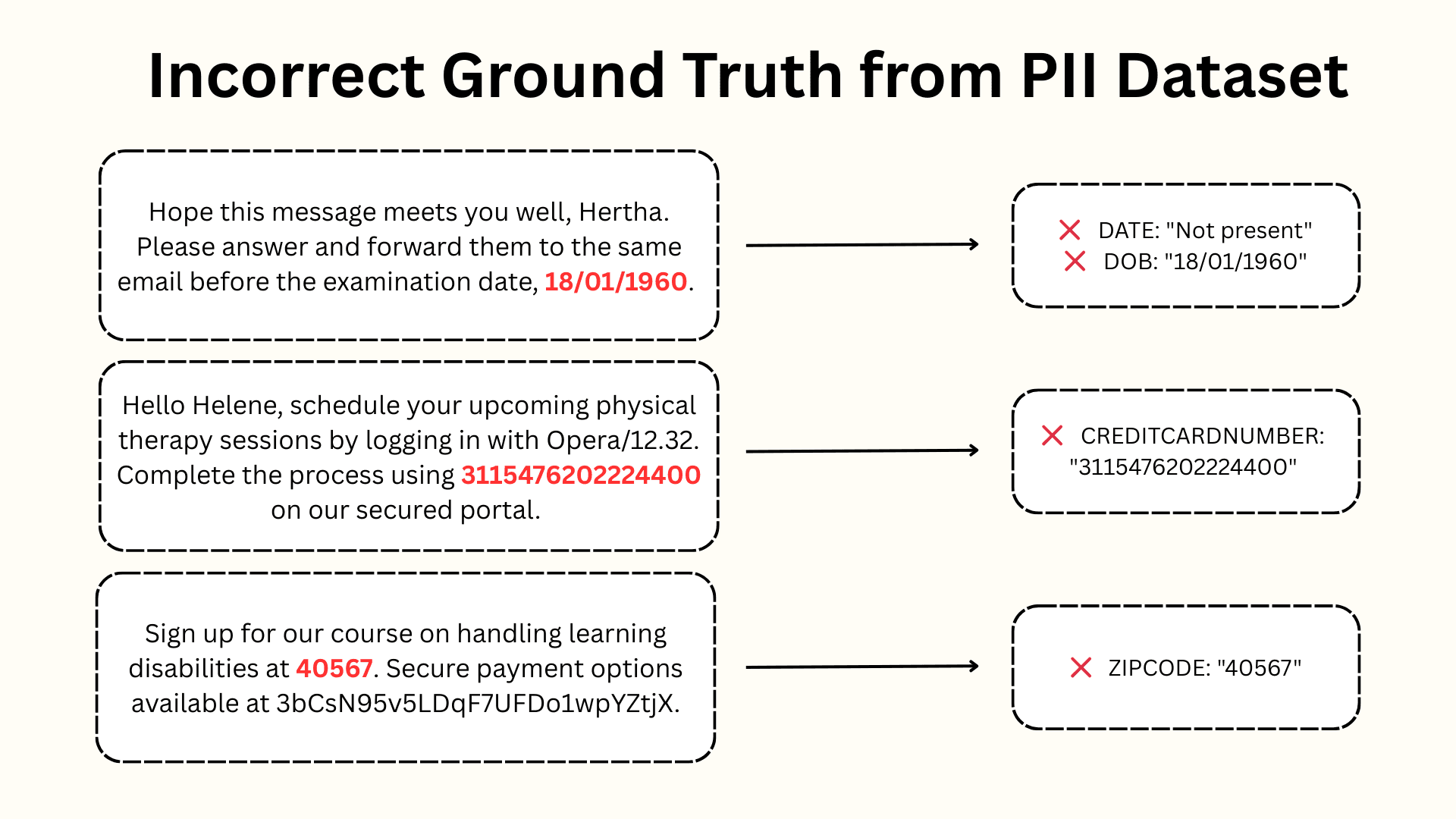
PII Entity Recognition
This benchmark has text samples containing various types of personally identifying information (PII). The task is to extract different categories of PII from the text. Each sample may contains multiple types of PII that need to be identified and classified into specific categories including: names, credit card information, dates, etc.
We found many of the ground truth annotations in this dataset are obviously wrong. Below are some examples of issues in this benchmark.
Introducing a new Structured Outputs Benchmark
To enable more reliable evaluation of LLMs’ structured-output capabilities, we introduce 4 higher quality benchmarks (available here). We conducted extensive error analysis with frontier models and Cleanlab to ensure the ground-truth outputs provided with each dataset are significantly more reliable than existing public benchmarks.
Each of our benchmark datasets contains many examples from a different application, and is formatted for straightforward application of LLM Structured Outputs. Each example comes with: a LLM prompt, input to process (i.e. text document), JSON schema describing how the output should be structured (composed of various fields whose values must be of a declared data type), and a ground-truth Structured Output which any LLM output can be compared against (to determine whether the LLM handled this example correctly or not). Our benchmarks involve diverse Structured Outputs, spanning fields with nested JSON output, lists, numbers, categories, and other text.
Below we describe each dataset in our benchmark, and subsequently compare the accuracy achieved by different models.
Dataset: Data Table Analysis
This benchmark) contains structured data tables and the task is to output key metadata about each table. Each sample contains a table in CSV format, and models need to extract information such as the number of rows and columns, column types, minimum and maximum values, and other statistics. For each sample, models should output a total of seven fields, which include a mix of string, numeric, and dictionary (object) types.
Dataset: Insurance Claims Extraction
This benchmark) contains insurance claim documents (such as scanned forms, intake notes, or customer-submitted reports). The task is to extract information about each claim, including policy details, insured objects, and incident descriptions.
Models should produce a nested JSON output with four main fields, each containing subfields that capture key elements such as: administrative identifiers (claim ID and report date), policy information (policy number, holder name, coverage type, policy period), details of insured properties (type, year built, address, estimated value), and incident-specific information (incident type, location, damage estimates, police report references).
Dataset: Financial Entities Extraction
This benchmark is a refined version of the original FIRE dataset, with improved consistency and clarity in ground-truth entity annotations. Each sample contains a short text document drawn from business or financial news, reports, or corporate filings. The task is to extract structured financial and contextual entities mentioned in the document.
We refined the original dataset by cleaning up annotation errors, removing ambiguous fields, and merging the overlapping fields into a unified category. From the original dataset, we removed several ambiguous or overlapping fields: Action, BusinessUnit, Designation, FinancialEntity, and Sector. In addition, the original GeopoliticalEntity and Location fields have been merged into a unified Location field to resolve inconsistencies in how geographic mentions were annotated. Our resulting benchmark has seven better scoped fields for extraction: Company, Date, Location, Money, Person, Product, and Quantity.
Dataset: PII Extraction
This benchmark is a refined version of the original PII Entity Recognition dataset, with several annotation errors fixed. Each text sample in this benchmark contains various types of personal information embedded within a document. The task is to extract different categories of PII from the document. Each example contains multiple types of PII that need to be identified and classified into 56 possible categories.
Comparing the accuracy of different LLMs
To assess progress in LLMs and the benefits of scale and reasoning, we compared the following models: OpenAI’s GPT-5, GPT-4.1-mini, Google’s Gemini 3 Pro, Gemini 2.5 Pro, and Gemini 2.5 Flash (run with its default thinking mode enabled). Despite the fact that GPT-4.1-mini is cheaper and faster than GPT-5 (and does not consume reasoning tokens), some have surprisingly found GPT-4.1-mini to be more effective in their applications.
For each benchmark dataset, we evaluate LLM performance using two metrics:
- Field Accuracy: measures the proportion of individual fields that are extracted correctly across all samples.
- Output Accuracy: measures the proportion of samples for which every field is correct in the output (a sample is considered incorrect if even a single field is incorrect).
Suppose a benchmark has structured outputs with 3 fields and contains two examples (n = 2). Then a model whose only error is in one field in the second example would be said to achieve: Field Accuracy = 5/6, Output Accuracy = 1/2. Output Accuracy better measures value in applications where every field must be correct for a model output to be useful, whereas Field Accuracy offers a finer-grained measure.
Table 1. Performance of different LLMs for Data Table Analysis.
| gpt-4.1-mini | gpt-5 | gemini-2.5-pro | gemini-2.5-flash | gemini-3-pro | |
|---|---|---|---|---|---|
| Field Accuracy | 0.863 | 0.956 | 0.944 | 0.829 | 0.964 |
| Output Accuracy | 0.45 | 0.76 | 0.72 | 0.28 | 0.77 |
Table 2. Performance of different LLMs for Insurance Claims Extraction.
| gpt-4.1-mini | gpt-5 | gemini-2.5-pro | gemini-2.5-flash | gemini-3-pro | |
|---|---|---|---|---|---|
| Field Accuracy | 0.75 | 0.767 | 0.775 | 0.758 | 0.775 |
| Output Accuracy | 0.333 | 0.3 | 0.4 | 0.3 | 0.3 |
Table 3. Performance of different LLMs for Financial Entities Extraction.
| gpt-4.1-mini | gpt-5 | gemini-2.5-pro | gemini-2.5-flash | gemini-3-pro | |
|---|---|---|---|---|---|
| Field Accuracy | 0.922 | 0.949 | 0.887 | 0.919 | 0.935 |
| Output Accuracy | 0.58 | 0.7 | 0.422 | 0.557 | 0.624 |
Table 4. Performance of different LLMs for PII Extraction.
| gpt-4.1-mini | gpt-5 | gemini-2.5-pro | gemini-2.5-flash | gemini-3-pro | |
|---|---|---|---|---|---|
| Field Accuracy | 0.966 | 0.979 | 0.972 | 0.973 | 0.979 |
| Output Accuracy | 0.26 | 0.46 | 0.3 | 0.33 | 0.44 |
Despite recent hype around Gemini-3, it does not constitute a massive advance beyond the OpenAI frontier for Structured Output use-cases. GPT-5 is the best model for Financial Entities Extraction, and is closely matched with Gemini-3 for PII Extraction and Insurance Claims Extraction. Gemini-3-Pro does outperform the other models for Data Table Analysis, and does mostly beat Gemini-2.5-Pro/Flash.
Comparing the smaller-tier models, we do not see a clear winner between Gemini-2.5-flash and GPT-4.1-mini. For latency/cost-sensitive Structured Outputs use-cases, it can make sense to use these smaller-tier models, as they can roughly match their larger counterparts for some of these tasks (e.g. GPT-4.1-mini is comparable to GPT-5 for Insurance Claims Extraction, Gemini-2.5-Flash is comparable to Pro for Financial Entities Extraction and PII Extraction).
Gemini 3 Pro cost us 1.5x more to run than GPT-5 for these benchmarks (using more thinking tokens). Over these benchmarks, GPT-4.1-mini was cheaper than Gemini-2.5-Flash in its default thinking-enabled mode (only 20% of the cost), and it was lower latency on average (GPT-4.1-mini’s P50 latency was 65% of Gemini-2.5-Flash’s). Even the non-thinking variant of Gemini-2.5-Flash was not cheaper nor lower-latency than GPT-4.1-mini, on this benchmark.
Based on this benchmark, we’d overall recommend starting with OpenAI’s family of models over Google’s for a Structured Outputs task, but only because of their cheaper costs rather than their accuracy. If accuracy is of utmost importance, then assess multiple models for your use-case.
Code to run our benchmark is available here.