

AI agents can fail in multi-turn, tool-use tasks when some erroneous intermediate LLM output derails the agent. One way to detect such reasoning errors, hallucinations, or incorrect tool calls is to use real-time LLM trust scoring techniques. Here we find that for the leading customer service AI agent benchmark, Tau²-Bench, LLM trust scoring with straightforward fallback strategies automatically cuts agent failure rates by up to 50% (code to reproduce).

AI agents are revolutionizing customer service, but remain too unreliable for complex tasks with high-stakes actions. The underlying LLMs occasionally produce incorrect outputs, and a single such error can irrecoverably derail an agent — a major risk given how many LLM calls each agent interaction requires.
To study agent reliability, we run Tau²-Bench. This leading customer service AI benchmark spans three domains (airline, retail, telecom) with complex customer interactions that require proper use of many tools, multi-step decision-making, and dealing with unpredictable customers. For example, in the telecom domain, the AI agent might be tasked with helping a customer fix their internet connection, where it must prompt the customer to check certain settings on their phone (such as airplane mode), and must use tools to check things about the customer (such as their data plan). For a particular customer interaction to be deemed successful in Tau²-Bench, the agent must call the proper set of tools and respond to the customer with particular information (in the Tau²-Bench terminology, we only consider pass^1 here).
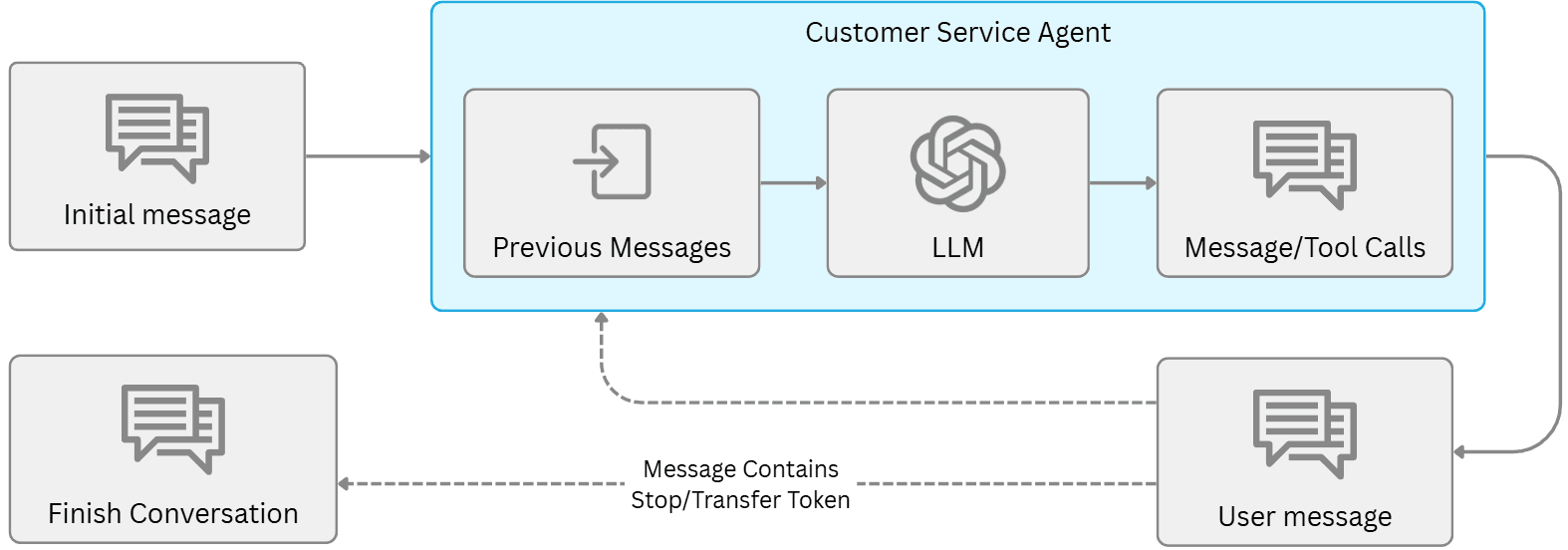
Real-Time Trust Scoring for Agents
One way to deal with LLMs’ jagged intelligence and lack of reliability is to rely on real-time trustworthiness scoring of each LLM output in an agent’s message chain. Cleanlab’s Trustworthy Language Model (TLM) provides low-latency trust scores with state-of-the-art precision for detecting incorrect outputs from any LLM, regardless whether the output is a natural language message or a tool call. TLM helps you automatically mitigate all sorts of LLM mistakes, including: reasoning errors, hallucinated facts, misunderstandings/oversights, system instruction violations, and wrong tool calls.
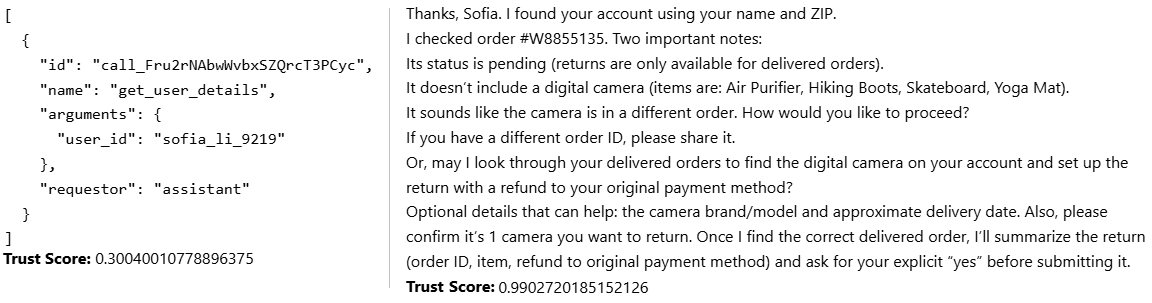
Consider the below example, where the Tau²-Bench agent for some reason runs the same tool twice (LLMs just make unpredictable mistakes like this). Because this shouldn’t happen, TLM gives the 2nd tool call output a low trustworthiness score.

This article considers two ways that trust scores can improve the original Tau²-Bench AI agent. Our approaches are easy to implement for any AI agent.
Escalating Untrustworthy Cases to Humans
For organizations seeking to provide high-quality customer support, interactions that the AI agent is likely to incorrectly handle should be escalated to a human support representative instead. One option is to equip the agent with a special escalate() tool or phrase, but LLMs remain pretty bad at knowing when to ask for help or knowing when they don’t know. TLM’s trustworthiness scores capture overall aleatoric and epistemic uncertainty in LLM outputs, enabling significantly better identification of cases where the agent makes a mistake.
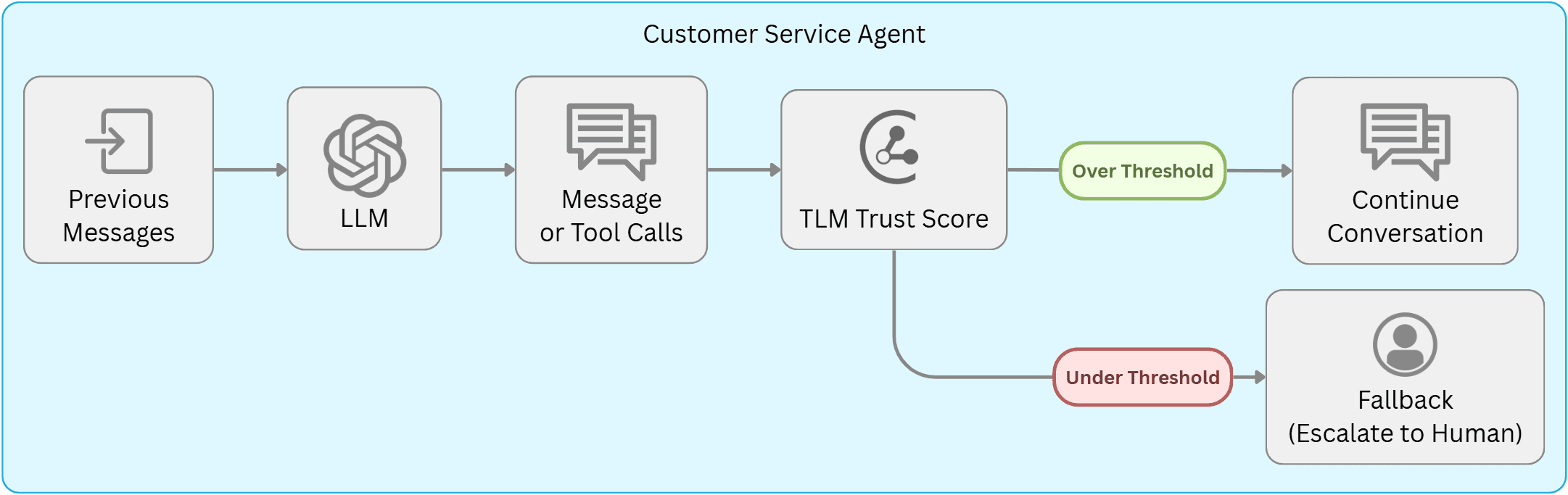
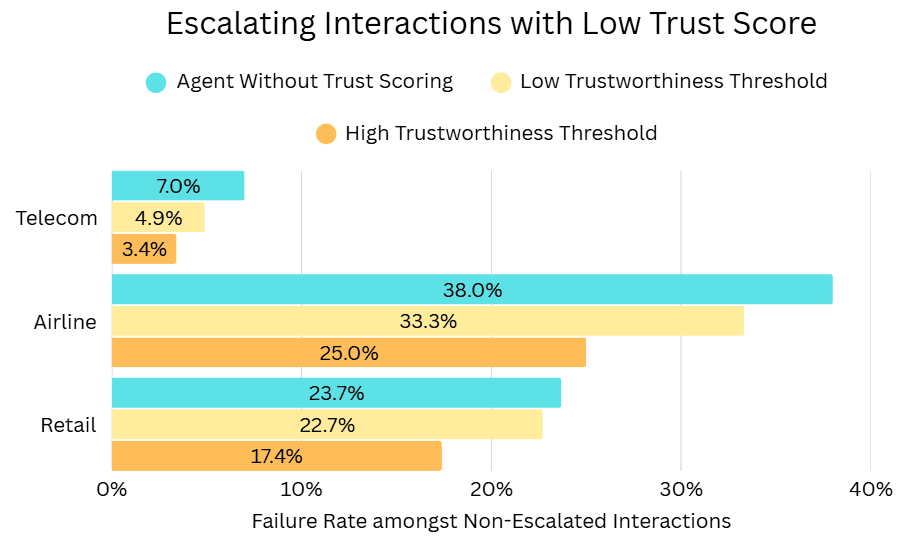
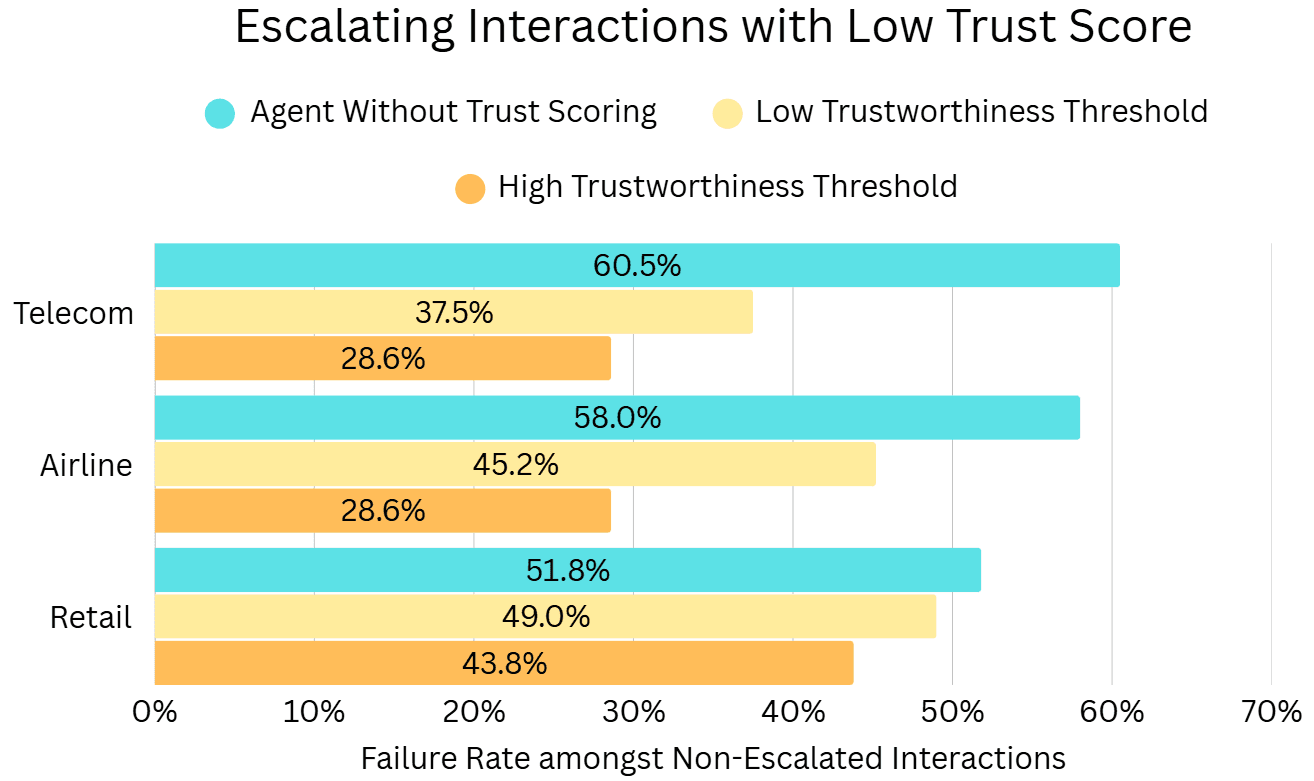
As depicted above, we can escalate customer interactions as soon as one of the agent’s LLM outputs falls below a trustworthiness score threshold. We assess the performance of this Automated Escalation pipeline via the agent’s failure rate among the remaining interactions (tasks) that were not escalated. The results below demonstrate that this approach can effectively reduce this failure rate across all Tau²-Bench domains, with lower trustworthiness thresholds providing greater failure rate reductions (as expected).
Autonomously Revising Untrustworthy LLM Messages
Curbing agent failures via escalation (or similarly via abstention fallbacks) can ensure that your agent meets enterprise failure-rate requirements, but the agent did not manage to help the customer in these scenarios. Let’s now consider how to automatically boost the success rate of the agent.
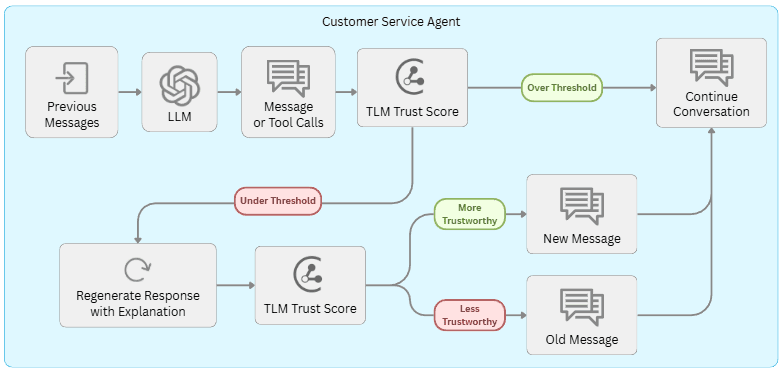
Here’s how our Automated Message Revision pipeline depicted above works: As before, we score the trustworthiness of each of the agent’s LLM messages, in real-time before any tools are actually called or this message is presented to the customer. If the trustworthiness score falls below a threshold, we automatically re-generate another LLM message to replace it before continuing to execute the agent and any tool calls. TLM also provides explanations to rationalize why a certain LLM output is untrustworthy. To automatically re-generate a better LLM message, we rely on the same input to the original LLM call, but first append to it an extra statement which reports the original LLM output and cautions that it was flagged as untrustworthy along with the explanation why. If the newly generated LLM message receives higher trustworthiness score than the original LLM message, then it replaces the original LLM message (and otherwise execution continues using the original LLM message).

The above results demonstrate that this fully autonomous approach can effectively boost the agent’s overall success rate in all Tau²-Bench domains. Below are some LLM outputs from three Tau²-Bench customer interactions, showing concrete successes thanks to automated message revision. In each example: the original Tau²-Bench agent ended up failing this interaction, but trust-score-powered automated message revision enables another copy of the same agent to succeed.


Benchmarking Agents powered by other LLMs
In the results thus far, we left Tau²-Bench configurations at provided defaults (including the Tau²-Bench customer simulator which is powered by OpenAI’s GPT-4.1 LLM). Throughout all benchmarks, TLM is run with default settings, which utilizes OpenAI’s GPT-4.1-mini LLM to ensure low latency/cost. No other model was used for trust scoring here, although TLM is capable of utilizing any LLM for trust scoring (TLM detects AI mistakes/hallucinations with even greater precision when utilizing a more powerful LLM).
Now we repeat the above benchmarks in a different setting, this time powering the customer service agents (and Tau²-Bench’s customer simulator) using a different model: OpenAI’s GPT-4.1-mini LLM. In this alternative setting, both the customer support agent and users are more prone to mistakes (details in Appendix). Below are the corresponding results for this alternative benchmark setting.

A Reliability Layer for your AI Agents
Beyond the Tau²-Bench gains presented here, Cleanlab is similarly improving customer-facing AI agents across enterprises, from financial institutions to government agencies. These teams also utilize trust scoring in offline evaluations to quickly spot an agent’s failure modes.
Reasoning, planning, tool use, and multi-step agentic execution expand AI capabilities, as well as the surface of possible mistakes. For any AI agent, Cleanlab’s trust scoring provides an additional layer of defense: don’t say/do it if you can’t trust it.
Try Cleanlab’s TLM API, and add real-time trust scores to any LLM/agentic application in minutes.
Appendix
Code to reproduce all of our results is available here.