
LLM evaluation is crucial for ensuring the quality and safety of AI systems, but it’s challenging to perform evaluations efficiently at scale while maintaining accuracy. This article describes how you can use our open-source CROWDLAB software to improve the accuracy and cost-effectiveness of your LLM evaluations, while also surfacing difficult evaluation cases, and highlighting which reviewers may need additional training. As a concrete example, we provide the end-to-end code to apply CROWDLAB to the famous MT-Bench LLM Evaluation dataset.
If your LLM Eval process takes too long, is too expensive, or you’re not confident in the results, then read on! CROWDLAB can help increase accuracy and efficiency in your LLM Eval process:
The Problem: Slow, Expensive, Unreliable Evaluations
One common impediment to enterprise LLM deployment is a scalable yet trustworthy evaluation system. This process, also known as LLM Evals, is critical to ensuring that your LLM System’s responses cover intended use cases, are factually accurate, and don’t contain offensive, harmful, or misleading responses. LLM Evals should be performed prior to launch as well as before deploying major changes to the system, for example, altering the vectorization, chunking or document retrieval configurations of a RAG system, altering the LLM’s system or user prompts, or changing the underlying foundational LLM.
Since comprehensive evals can include hundreds of example questions, the most scalable way to conduct human-based LLM evals is to have teams of multiple human labelers. Unfortunately, research shows that even highly-skilled humans often disagree on evaluations, and the need to quickly and economically label a large number of evaluations means that non-experts are often required, further degrading the quality of the LLM Evals process.
The Solution: CROWDLAB for LLM Evals
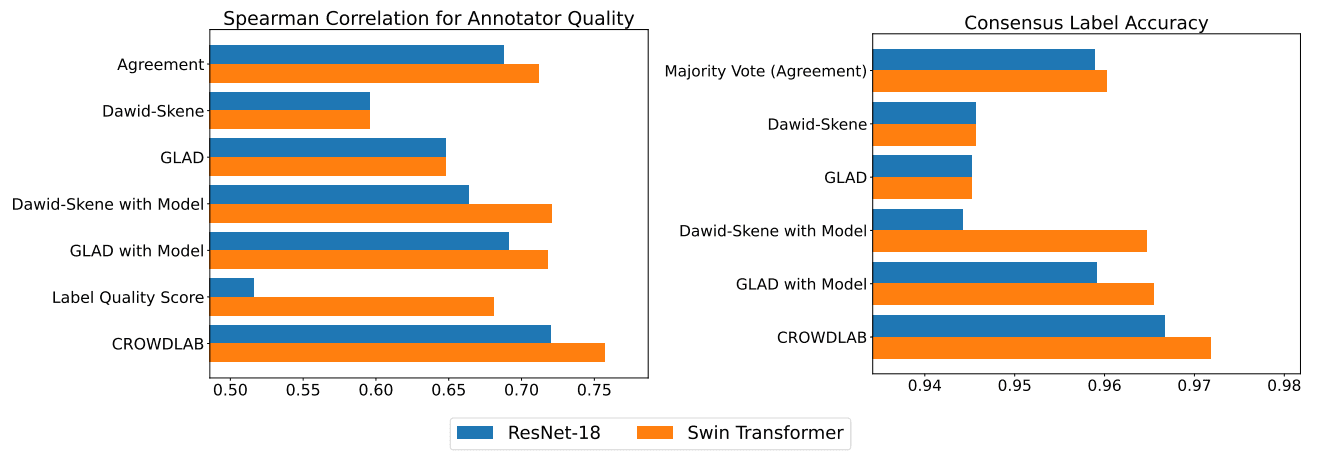
Researchers at Cleanlab developed CROWDLAB (Classifier Refinement Of croWDsourced LABels) as a cutting-edge algorithm for quickly and easily improving labels. CROWDLAB uses principled statistical techniques to optimally combine human and AI annotators/reviewers, and has been observed to outperform other methods of inferring consensus labels:
While useful for typical data-labeling tasks, the CROWDLAB algorithm can also easily be utilized for improving LLM Evals. CROWDLAB can utilize any AI model you provide, including LLMs serving as annotators or judges and ensembles of multiple models.
How to use CROWDLAB for LLM Evals
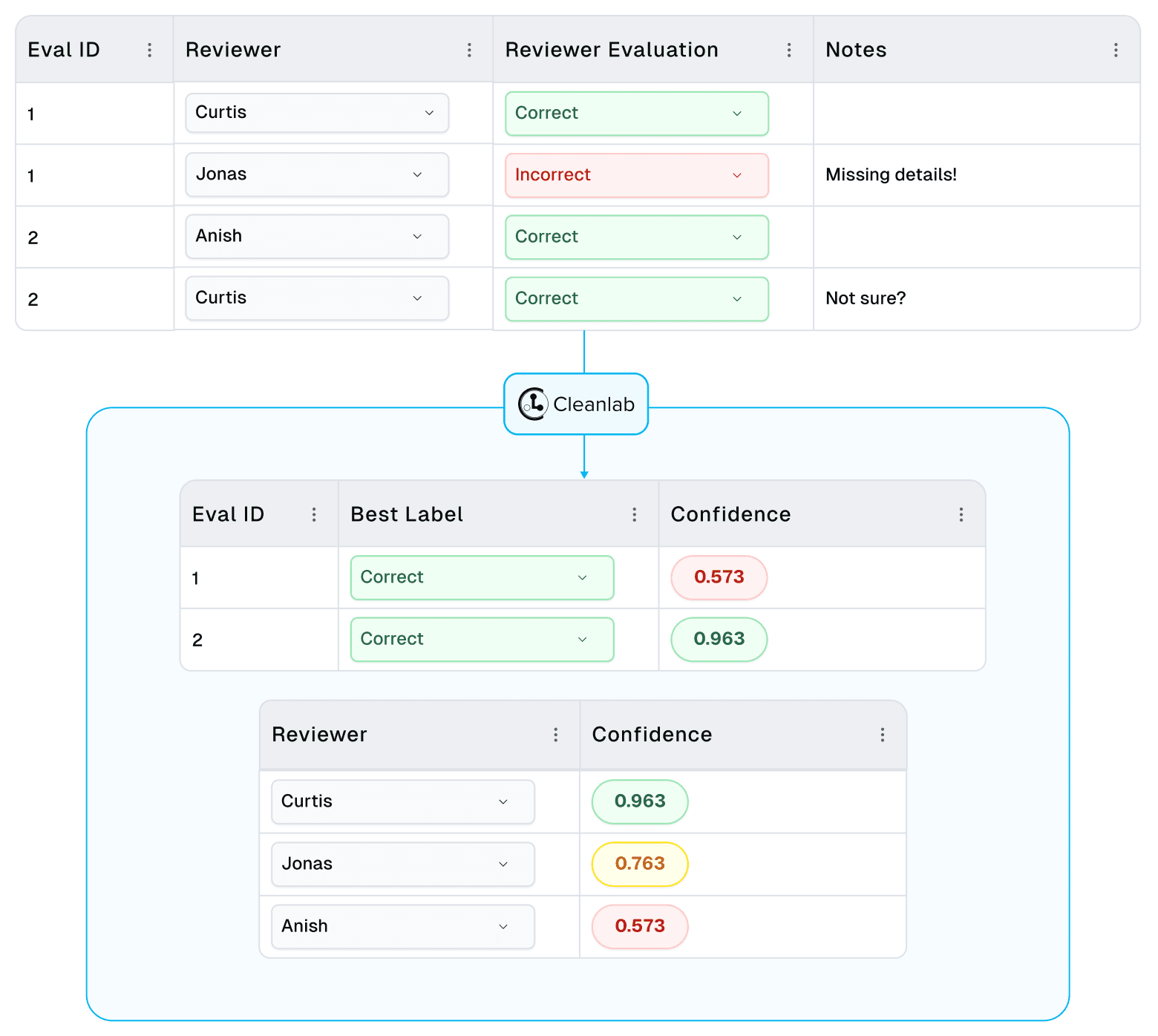
Using CROWDLAB for LLM Evals is simple: First, input your human-produced LLM Evals (e.g. correct/incorrect, or model_a/model_b). Then, add a probabilistic classification score, which can be produced using a conventional ML model or from the token probabilities available in popular LLMs like OpenAI’s GPT family or Cleanlab’s Trustworthy Language Model (We support Cleanlab Studio users with this process).
CROWDLAB will then produce a consensus rating for each example, as well as a quality score for each reviewer and each of their individual ratings. This allows you to quickly identify examples that warrant further review, and determine which labelers are providing the most/least reliable ratings.
Application to LLM Evals from MT-Bench
The overall process is demonstrated in this notebook tutorial, which implements CROWDLAB for LLM Evals on MT-Bench, a popular LLM Evals benchmark. MT-Bench compares different LLM’s responses to various prompts in multi-turn question answer settings, with multiple (between one and five) human evaluators voting for the best LLM answer in pairwise comparisons, as illustrated below:

In the notebook, we use CROWDLAB to determine the most likely consensus rating for each example, highlight which examples warrant additional scrutiny, and measure the reliability of the human evaluators.
Even easier and more trustworthy LLM applications with Cleanlab Studio and TLM
Note that CROWDLAB requires an effective ML model to produce good results. Cleanlab Studio provides the best model for your dataset, so you can gain confidence in your LLM Evaluation prior to launching.
And while CROWDLAB improves your evaluation process, Cleanlab’s Trustworthy Language Model (TLM) automatically determines which of your LLM outputs are untrustworthy, allowing you to detect and squash hallucinations and mistakes before they are shown to customers. Try it for free!
Resources to learn more
- Notebook applying CROWDLAB for LLM Evals on MT-Bench.
- CROWDLAB paper containing all the mathematical details and extensive comparisons against other methods.
- Basic tutorial to run CROWDLAB on any data labeled by multiple annotators, without having to do any Machine Learning.
Join our community of scientists/engineers to ask questions and see how other teams are tackling LLM Evals: Cleanlab Slack Community