

Most real-world supervised learning datasets are noisily labeled1. While manually reviewing each example is the gold standard to eliminate label errors from a dataset, this is time-consuming and costly.
Now, data annotation teams can more quickly ensure accurate data via automated quality assurance provided by the Cleanlab Studio platform. Cleanlab Studio determines which data you do not need to review because our AI has already verified its label accuracy with high confidence. This saves you a significant amount of time when reviewing datasets to ensure annotation quality. Additionally, this feature allows you to instantly compare the quality of different datasets (based on their fraction of high-confidence examples) and gain a better understanding of a dataset through its most confidently labeled examples, which typically serve as excellent representations of the labeled concepts.

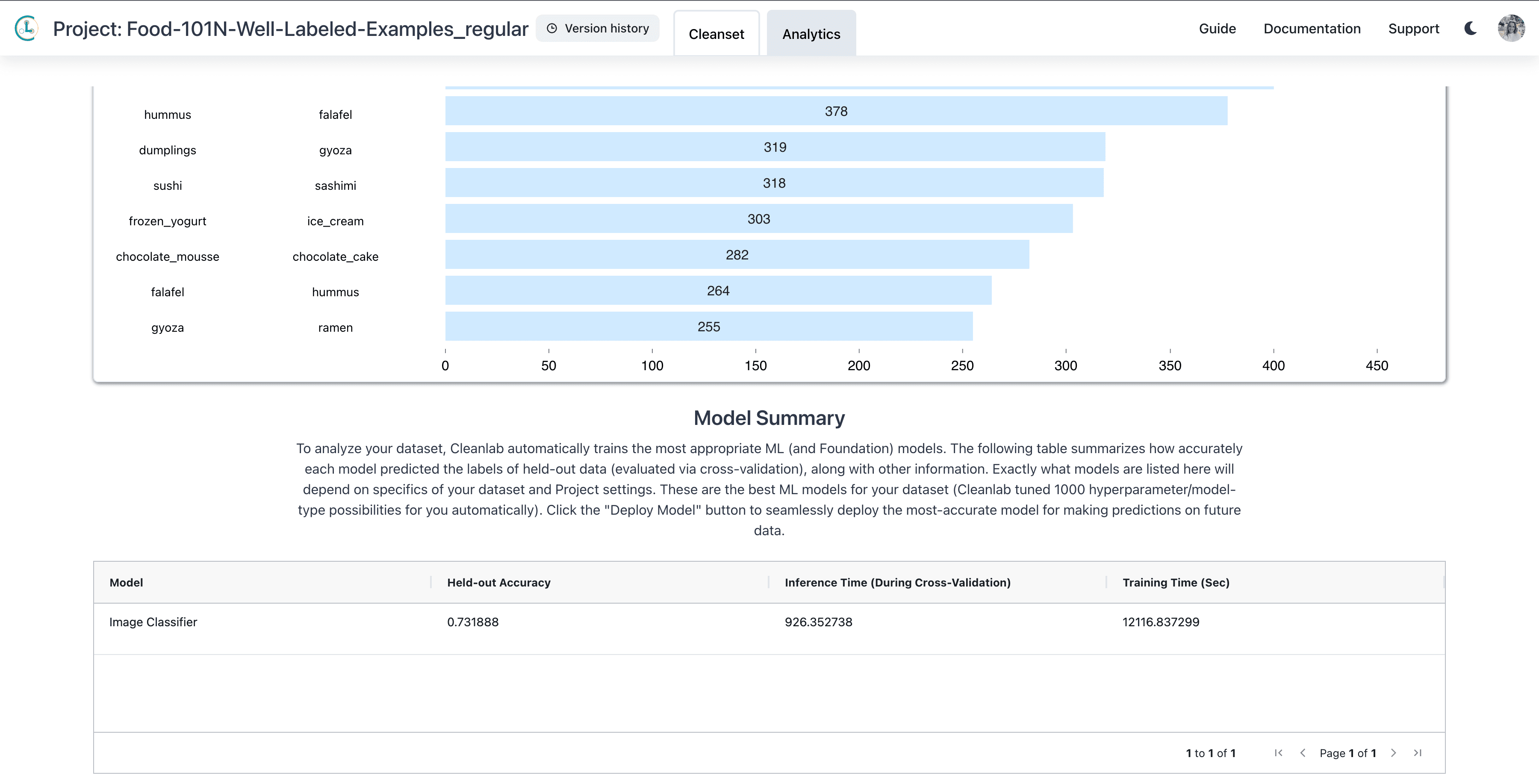
Analyzing the Well Labeled Examples in the Food101N dataset
The Food101N dataset2 contains 310,000 images of 101 different classes of food, which have been noisily annotated. When run on this dataset (which only takes a few clicks), Cleanlab Studio automatically designates over 100,000 of the images as Well Labeled, indicating that quality assurance teams can trust the labels of this subset and skip asking other annotators to review them again.

Upon visually scanning the Well Labeled example set, we observe that each image provides a clear representation of its assigned class label.
Blindly trusting one-third of the dataset can seem like a lot for a dataset known to have noisy annotators (as is the case for Food101N). In Cleanlab Studio’s “Analytics” tab, we observe that its automatically-trained classifier achieves a held-out accuracy of 0.735 and is thus fairly good at predicting the labels of many examples. It appears reasonable to trust this ML model’s predictions in the top 1/3 of the data where these predictions most confidently corroborate the given labels.
Why should you trust Well Labeled Examples?
The Cleanlab Studio platform automatically fits a ML model (more precisely an effective combination of models based on fine-tuned AutoML and pretrained Foundation models) to your dataset and uses them with novel algorithms invented by our scientists to estimate labeling quality and other data issues.
To determine which examples we can be confident are Well Labeled, Cleanlab Studio considers both: the model-estimated trustworthiness of each label, measured via label quality score which numerous research papers have been extensively benchmarked as an effective measure to detect label errors13 and predictive performance of its model across this specific dataset (i.e. how trustworthy the model is overall for this dataset). The adaptive process to determine Well Labeled examples is tailored specifically to your dataset and annotations to ensure reliability across all sorts of datasets. We’ve tested the Well Labeled tag on numerous real and synthetic datasets to ensure our automated quality control remains performant across diverse data characteristics. For each dataset in our benchmark, we know the underlying ground-truth labels (collected and verified by a gold-set of annotators) and can thus assess how many annotation errors in the original given (noisy) labels were incorrectly included in the Well Labeled subset.
For each dataset in our benchmark, the table below shows the:
- fraction of data identified as Well Labeled (i.e. how much time you can save in the data review process)
- fraction of data identified as Well Labeled where the given label is actually wrong (i.e. a mistake in the automated quality control)
- fraction of data where the given label is actually wrong (i.e. how difficult it is to avoid mistakes in automated quality control)
- how good the ML model automatically-trained inside Cleanlab Studio is
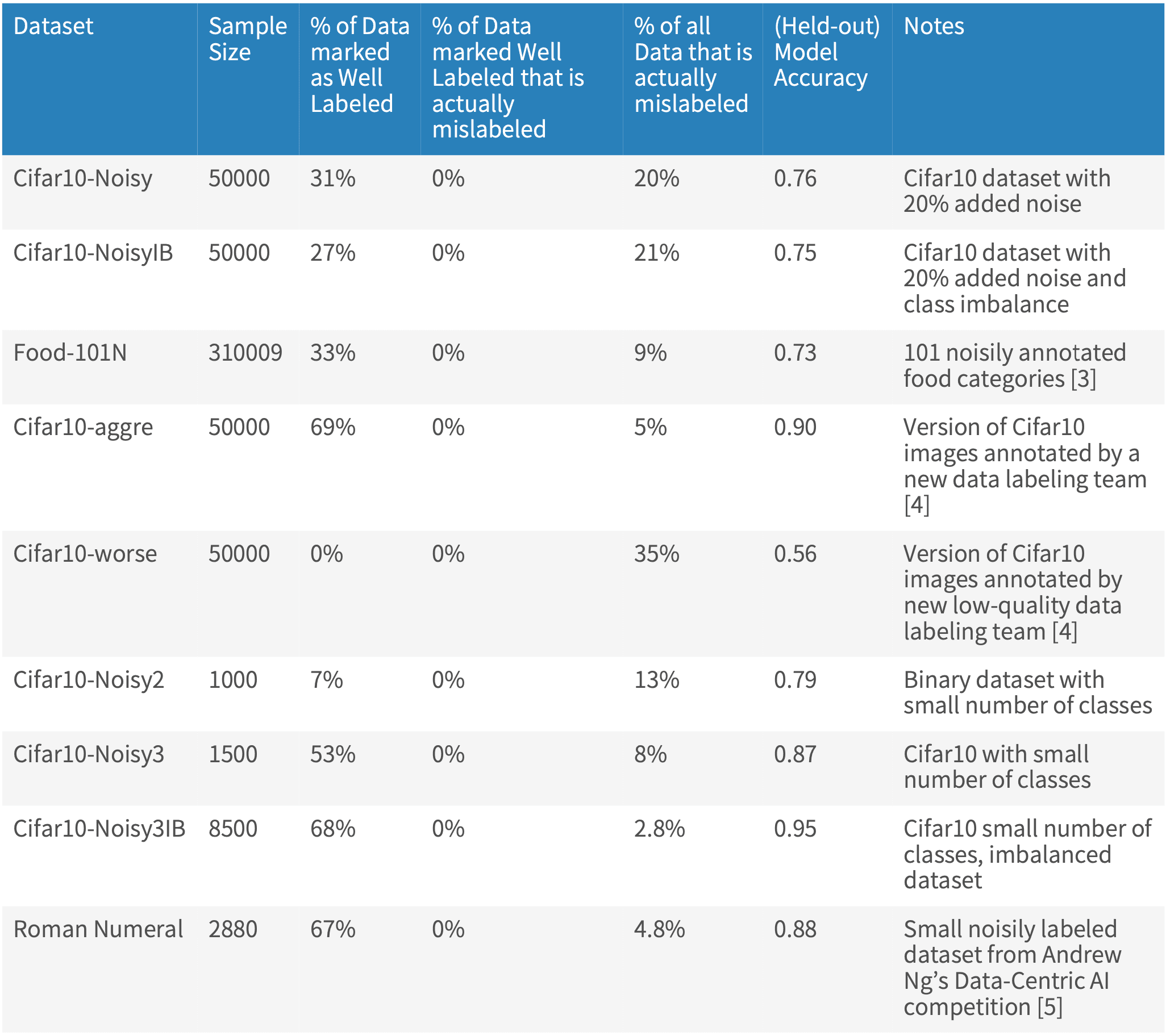
This table shows that Cleanlab Studio’s Well Labeled tag can help you ensure high-quality datasets while saving immense data reviewing time. In many datasets, over half the examples receive this tag, meaning your team would not have to worry about them! As you can see, 0% of the mislabeled examples in each dataset were found in the Well Labeled set. While it might seem like magic that Cleanlab Studio can automatically ensure this, it is just clever algorithms developed via extensive scientific research by our scientists. Intuitively, Cleanlab Studio will tag fewer examples as Well Labeled when model accuracy is low (it is not trustworthy) or model confidence/calibration is low (we cannot use the model to effectively corroborate the data) — usually such datasets have significantly fewer examples that look like clear representatives of the label concepts.
Datasets with Imbalanced classes
Finding label errors in datasets with imbalanced classes can be particularly challenging due to the lack of samples from the minority class. The correction of these errors is critical, as label errors can disproportionately affect the underrepresented class. Cifar10-Noisy3IB is composed only of cat, dog, and horse classes, with only 500 dog compared to 5000 cat and 3000 horse images (and a label-noise rate of 3%). Cifar10-NoisyIB has all 10 classes from the original Cifar104 dataset, but far fewer cat, dog, and horse images compared to the rest of the classes (and a label-noise rate of 20%).
Cleanlab Studio identified 27% of the Cifar10-NoisyIB images as Well Labeled, none of which had actual label errors. In Cifar10-Noisy3IB, where the model accuracy was significantly higher, Cleanlab Studio tagged 68% of the dataset as Well Labeled, and again none of these images actually had label errors. This 0 false positive rate on both imbalanced datasets demonstrates how you can confidently skip thousands of examples when manually reviewing data in annotation quality control efforts, saving significant time without sacrificing quality.
Datasets of variable sizes and with variable number of classes
In addition to datasets with class imbalance, we tested Cleanlab Studio on differently sized datasets and with variable numbers of classes. Cifar10-Noisy2 is a binary classification dataset with a label-noise rate of 13% and only has 1000 images of the classes airplane and ship. Cleanlab Studio only marks 7% of this data as Well Labeled, which might seem low, but model performance on this small/noisy dataset is subpar (79% accuracy). Thus, Cleanlab Studio adaptively identifies fewer examples as Well Labeled to avoid incorrectly including an annotation error in this high confidence set.
At the other end of the spectrum is the Food101N dataset2 with 101 classes and 310,000 images. Here Cleanlab Studio’s model is quite accurate and identifies over 100,000 of the images as Well Labeled. Since modeling labels in small datasets can be statistically challenging, we also studied RomanNumeral5, a dataset with 10 classes and only 2880 examples. Applying Cleanlab Studio to this dataset, you could skip 67% of images that it marked Well Labeled and not miss a single one of the many actual label errors lurking in the dataset. Across datasets of varying sizes and modeling difficulty, 0 actual label errors were ever found amongst the set Cleanlab Studio automatically identifies as Well Labeled.
Datasets with variable annotation quality
Cleanlab Studio also proves highly effective for datasets with variable annotation quality. We considered two variants of Cifar10 popular in noisy-labels research: Cifar10-aggre6 and Cifar10-worse6, which contain 5% and 35% label noise, respectively. Cleanlab Studio’s model trained on the dataset with less label noise outputs more confident estimates, allowing our method to automatically mark a larger portion of the Cifar10-aggre dataset as Well Labeled (69% to be precise).
In contrast, no images in Cifar10-worse are marked as Well Labeled since the underlying label noise is so extreme that Cleanlab Studio automatically recognizes it cannot sufficiently trust its ML model. By adaptively becoming more conservative as needed, the algorithms in Cleanlab Studio successfully avoid incorrectly marking any of the mislabeled images in either dataset Well Labeled.
Conclusion
Our automated approach to identify Well Labeled data incorporates both model confidence and annotation quality, enabling reviewers to confidently bypass manual review of large portions of a dataset. In some cases, over 60% of the data does not need a secondary review, saving significant time and resources while achieving the same results as a comprehensive manual review of the full dataset. While this blogpost focused on image data, the same technique can be applied for automated quality control of annotations for text and tabular datasets as well.
Next Steps
- Automatically identify which of subset of your data is Well Labeled with Cleanlab Studio. Rest easy knowing the data annotations have been verified with confidence by cutting-edge AI!
- Join our Community Slack to discuss using AI/automation to improve your data.
- Follow us on LinkedIn or Twitter to stay up-to-date on the best data quality tools.
References
Footnotes
-
Northcutt C, Jiang L, Chuang I. Confident learning: Estimating uncertainty in dataset labels. Journal of Artificial Intelligence Research. 2021. ↩ ↩2
-
Lee, K.-H., He, X., Zhang, L., and Yang, L. Cleannet: Transfer learning for scalable image classifier training with label noise. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018. ↩ ↩2
-
Kuan J. Mueller J. Model-Agnostic Label Quality Scoring to Detect Real-World Label Errors. ICML DataPerf Workshop, 2022. ↩
-
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, 2009. ↩
-
Ng, A. Data-centric AI competition. DeepLearning.AI and Landing AI, 2021. ↩
-
Wei, J., Zhu, Z., Cheng, H., Liu, T., Niu, G., and Liu, Y. Learning with noisy labels revisited: A study using real world human annotations. International Conference on Learning Representations, 2022. ↩ ↩2