

This article evaluates 5 AI Agent architectures over the BOLAA (ICLR 2024) benchmark, and assesses the effects of adding automated trust scoring to flag incorrect Agent responses in real-time. Across single- and multi-hop QA tasks, trust scoring automatically reduces incorrect responses across all AI Agent types: from Act by 56.2%, from ReAct (Zero-shot) by 55.8%, from ReAct (Few-shot) by 15.7%, from PlanAct by 24.5%, and from PlanReAct by 10.0%.

Many teams are struggling to prevent incorrect responses from their AI Agents because: LLMs are prone to hallucination and factual/reasoning errors, Tools and Retrieval/Search are hard to implement optimally, and Data may be messy. When mistakes go uncaught and your company’s AI Agent responds incorrectly to a customer, this erodes trust and hurts your business – undermining the benefits of AI.
That’s where automated trust scoring comes in. Cleanlab’s Trustworthy Language Model (TLM) automatically assigns a real-time trust score to every Agent response. When scores are low, you can suppress the output, escalate to a human, or return a fallback like “I’m not sure.” This ensures your Agents doesn’t confidently provide wrong answers.
In this study, we benchmark how trust-score-based-guardrailing affects incorrect response rates across 5 popular AI Agent architectures. Our study adopts the BOLAA benchmark from Salesforce AI Research, whose underlying dataset (HotPotQA) includes single- and multi-hop questions that require reasoning across multiple data sources for the Agent to produce the correct answer.
Trust Scoring Works on Any Agent
TLM is easy to integrate into any AI Agent you’ve implemented, and can provide real-time trust scores for every LLM output that the Agent relies on, including the final response it provides to the user. We’ve released all of the code to reproduce our study on GitHub.
Here we add TLM to each of the five popular Agent architectures studied in the Salesforce’s BOLAA benchmark, which were implemented in their AgentLite library (and depicted above).
Act. This Agent directly generates actions and then a final response using only the task instructions (no intermediate reasoning steps nor few-shot examples). This Agent is referred to as Zeroshot in the BOLAA paper.
ReAct (Zero-shot). The popular ReAct framework adds a “think” step (chain-of-thought reasoning) before each step where the Agent chooses an action. This Agent is equivalent to the original ReAct Agent, but without any few-shot example trajectories in the prompt to guide the Agent. This Agent is referred to as ZeroshotThink in the BOLAA paper.
ReAct. A standard ReAct Agent, that includes few-shot example trajectories in its prompt in addition to utilizing chain-of-thought reasoning. This is a common type of AI Agent used today, as it is quite general.
PlanAct. A Plan-then-Act Agent that generates a full plan before executing any actions, rather than reasoning in every step. This Agent also has few-shot examples in its prompt.
PlanReAct. An Agent that combines planning and chain-of-thought reasoning, and also has few-shot examples in its prompt. This Agent first generates a plan and then uses the ReAct framework to execute on that plan.
Scoring the trustworthiness of each Agent’s final response only takes a few lines of code with Cleanlab (see code further below).
Example Where Trust Score Catches a Faulty Response
Here’s a concrete instance from the BOLAA benchmark, where an Agent gives a wrong answer that automatically received a low trust score from Cleanlab.
Task: Where did the form of music played by Die Rhöner Säuwäntzt originate?
Agent Response: The form of music played by Die Rhöner Säuwäntzt, skiffle-blues, originated in the Rhön Mountains region in Hessen, Germany, incorporating local dialects.
TLM Trust Score: 0.325
Although Die Rhöner Säuwäntzt is a German band rooted in regional culture, the musical style they play (skiffle-blues) originates from the United States. This subtle but important factual error in the Agent’s response highlights the power of trust scoring: even nuanced inaccuracies that might slip past casual readers can be flagged by low confidence scores from Cleanlab.
Benchmark Results
After using Cleanlab to score the trustworthiness of each Agent’s final response, we assess performance across the BOLAA dataset using the following metrics:
- Correct = % of Agent responses graded as correct.
- Incorrect = % of Agent responses graded as incorrect.
- Not attempted = % of Agent responses graded as not attempted + Agent responses with TLM trust score below a 0.8 score threshold.
- Halted = % of tasks where no response was produced because AgentLite exceeded its 10-step limit.
Here each Agent response was categorized as Correct, Incorrect, or Not Attempted (i.e. when the Agent explicitly abstained from answering). When trust scores fall below a threshold, we guardrail the Agent’s original response replacing it with a fallback answer (that is considered Not Attempted). Ideally, our Agent should get every response correct, but when this is infeasible, we strongly prefer an Agent that does not attempt to answer rather than one which answers incorrectly. To grade Agent responses, we rely on the ground-truth answers available in the BOLAA benchmark (which are not available during Cleanlab’s trust scoring). We use OpenAI’s SimpleQA LLM-grading templates to evaluate Agent responses against ground-truth answers.
The results of our benchmark reveal that trust score guardrailing significantly reduces incorrect responses across all Agents.
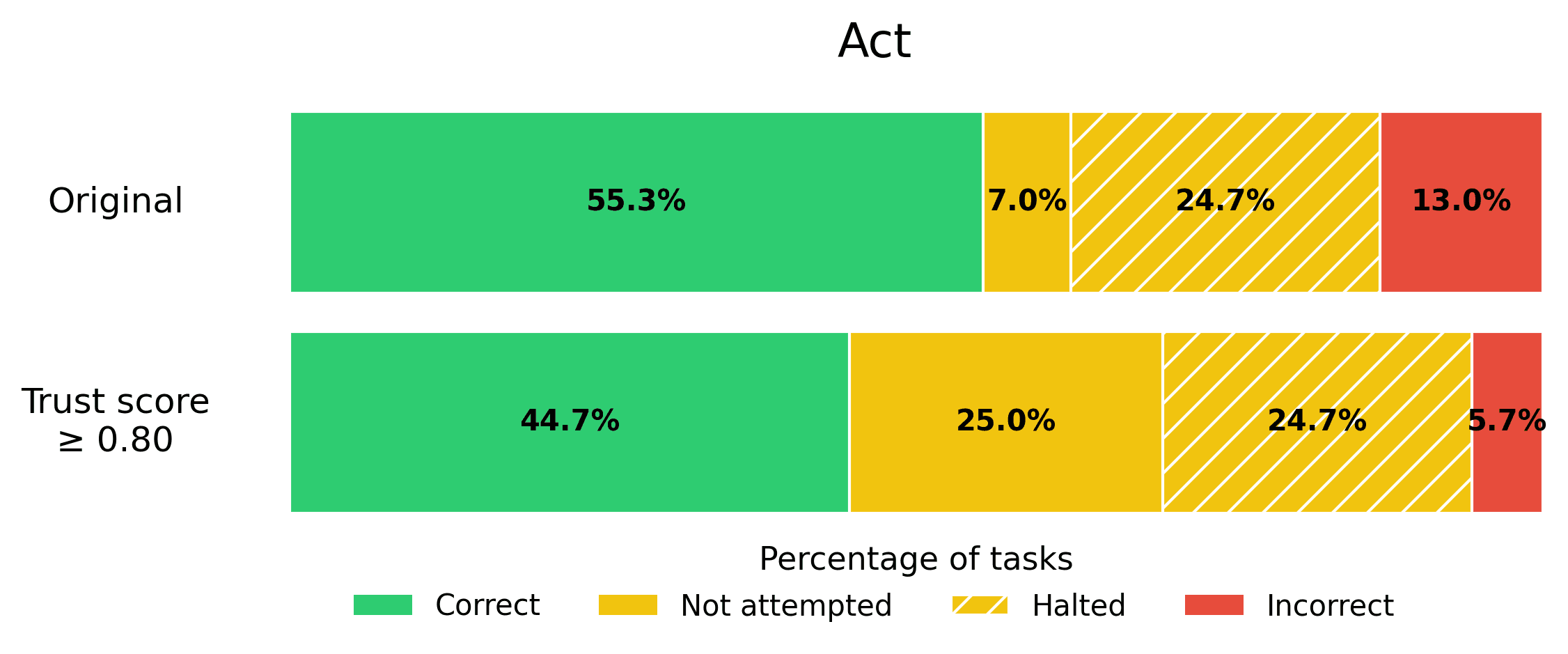
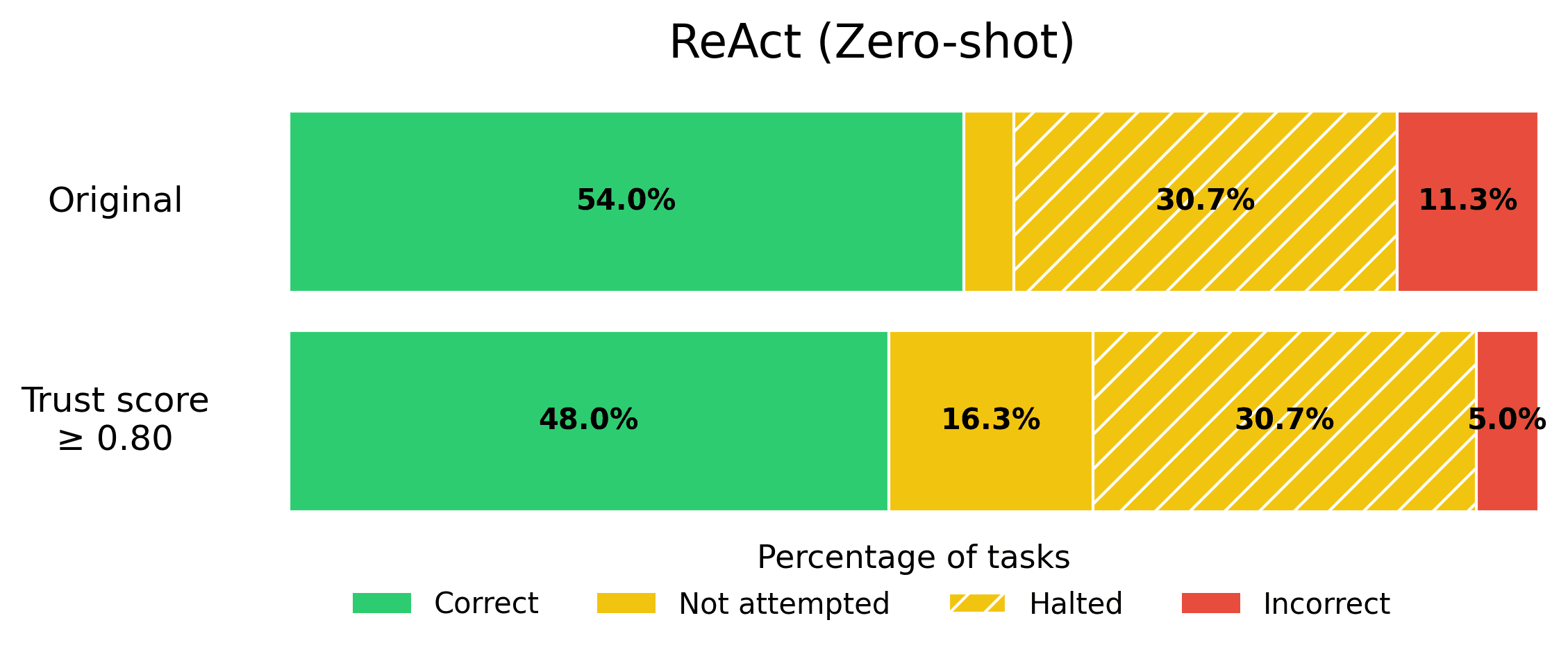
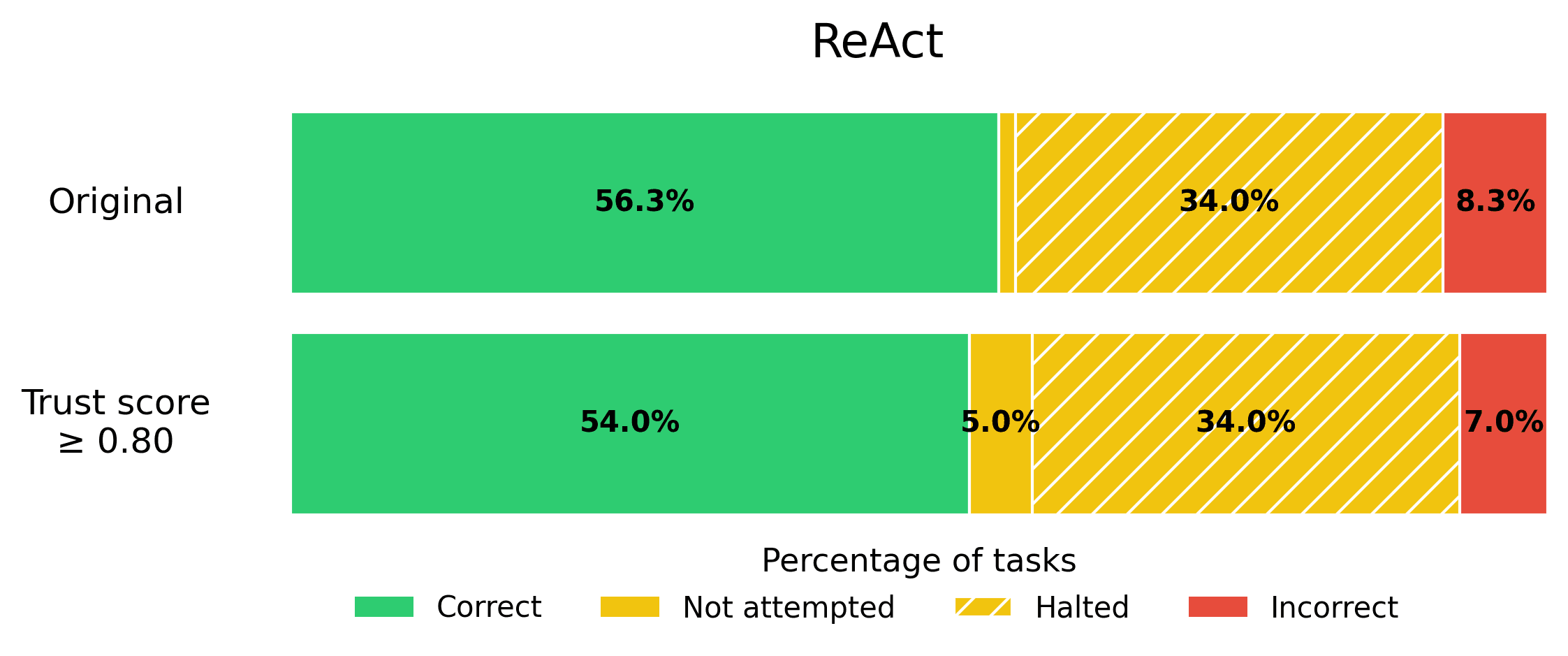
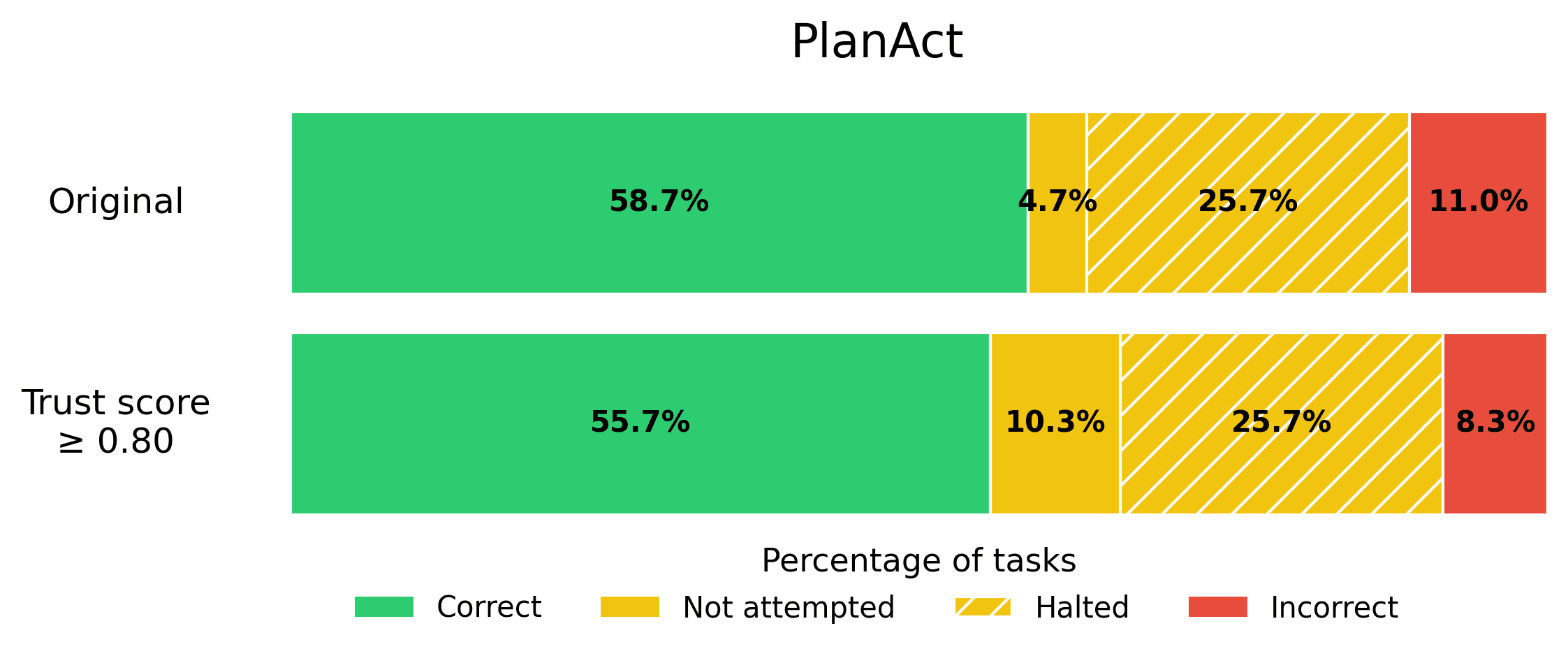
If reducing incorrect Agent responses is vital to you, consider applying a stringent trust score threshold! Here we used 0.8 as an example threshold, but the optimal threshold value will depend on your use-case.
Achieving production-ready error rates
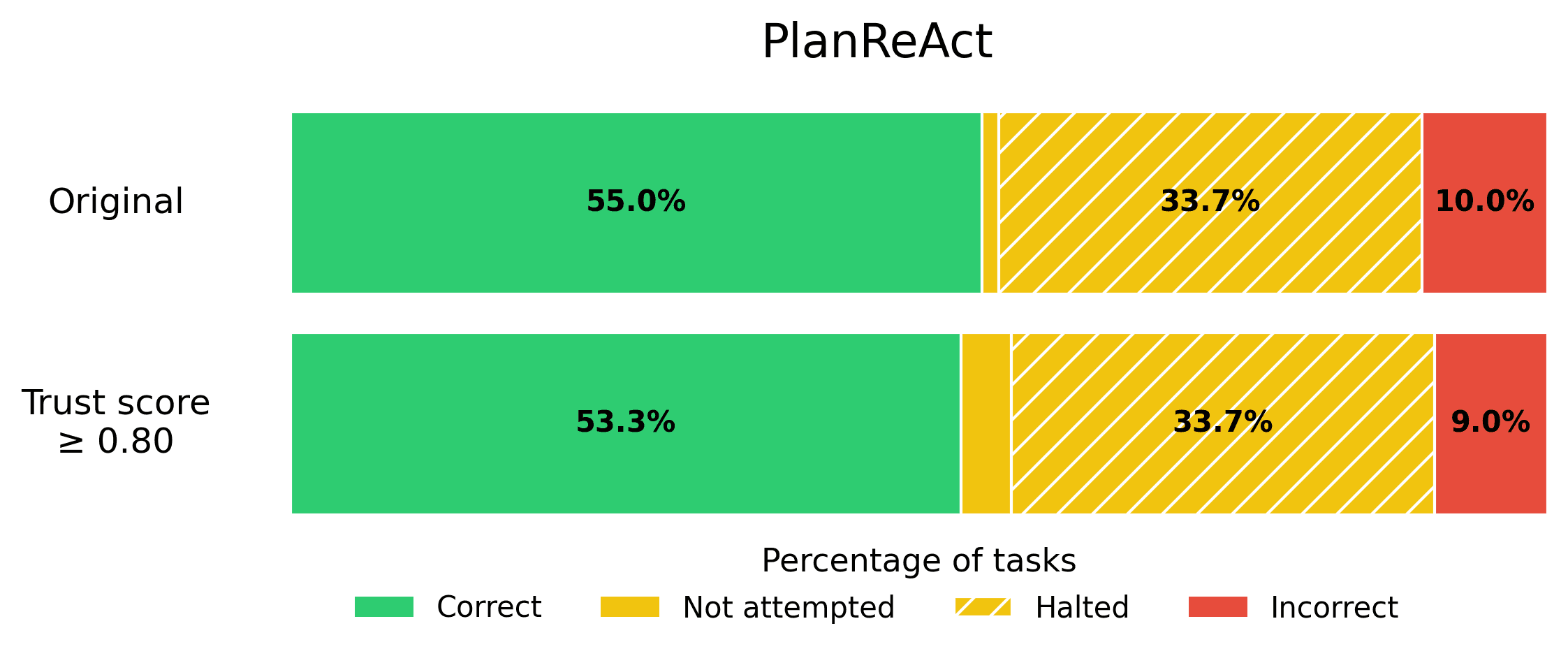
Suppose your business requires that the rate of incorrect responses not exceed 5%, in order for an Agent to be production-ready. You can calibrate the trustworthiness threshold on a eval set to find the appropriate threshold that satisfies this error tolerance, and then quickly get your AI Agent into production. Here we show what this looks like for each Agent from the BOLAA benchmark.
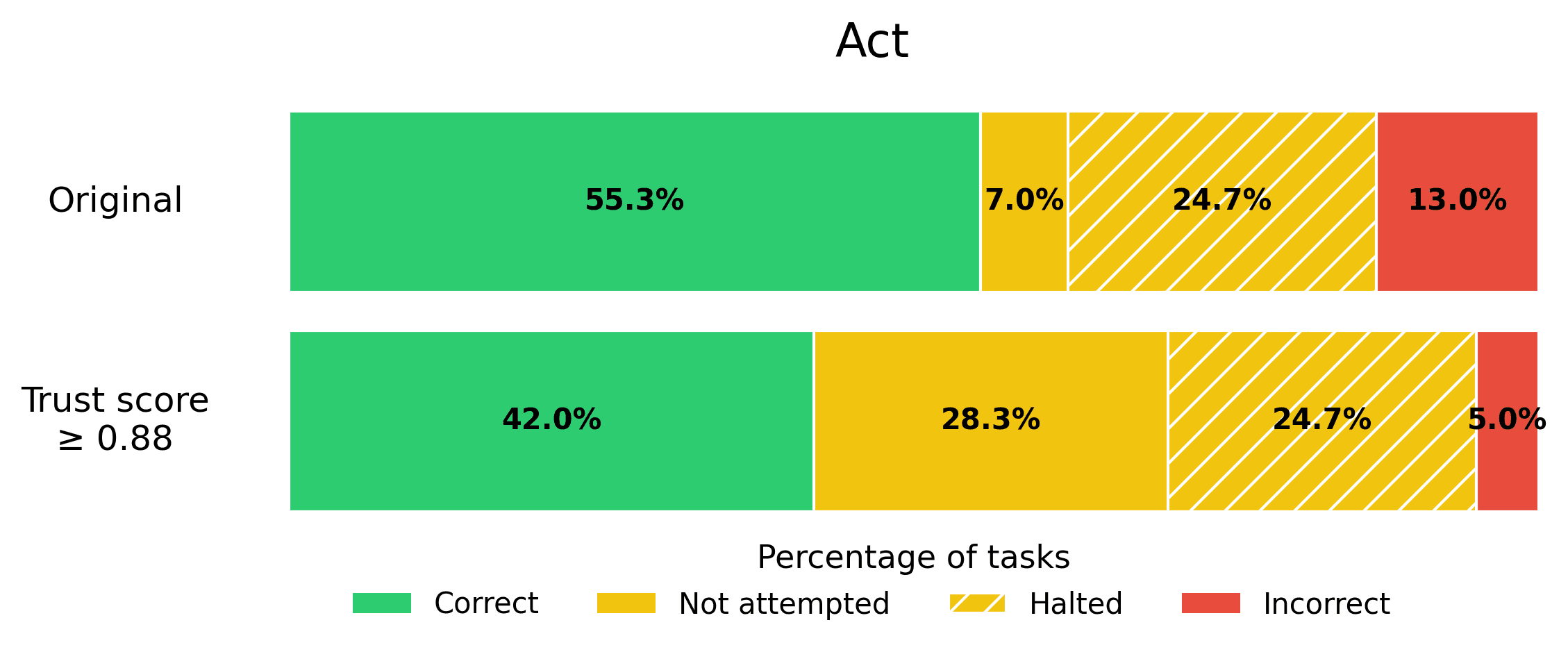
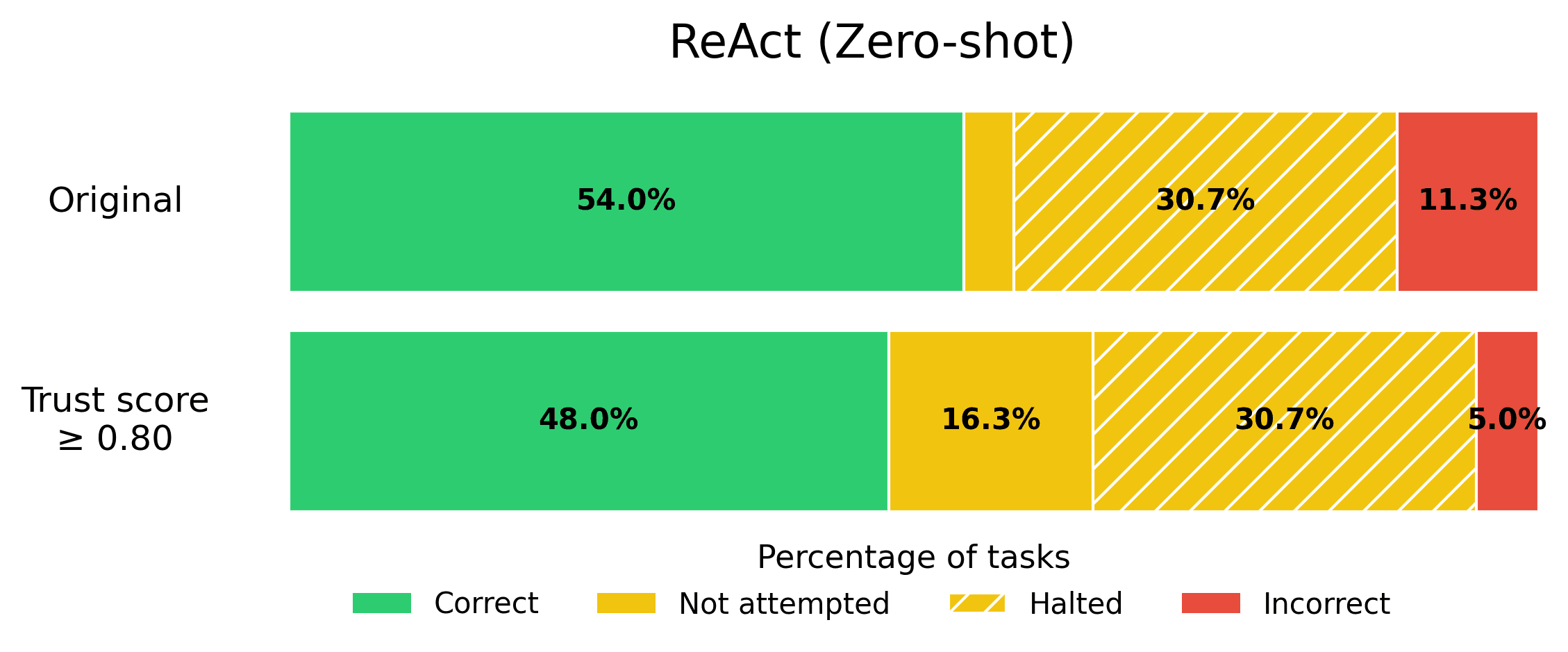
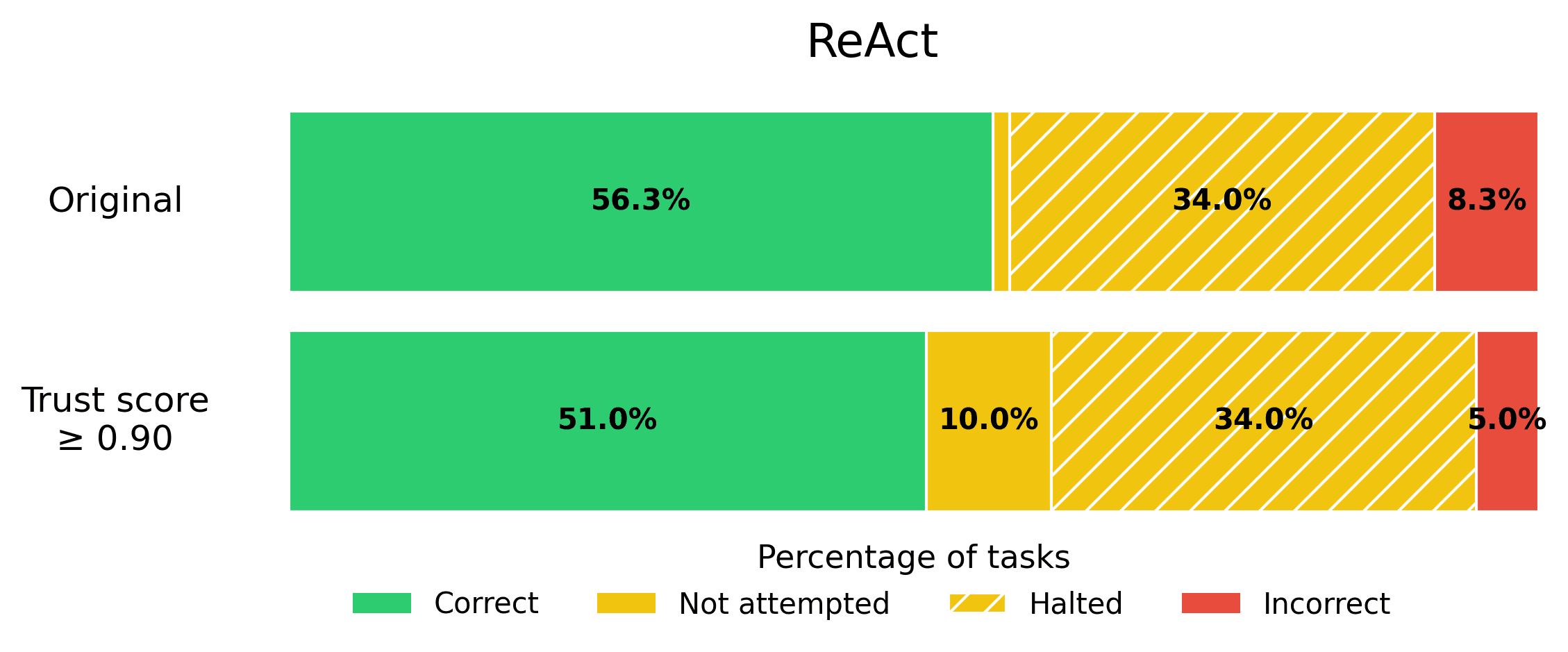
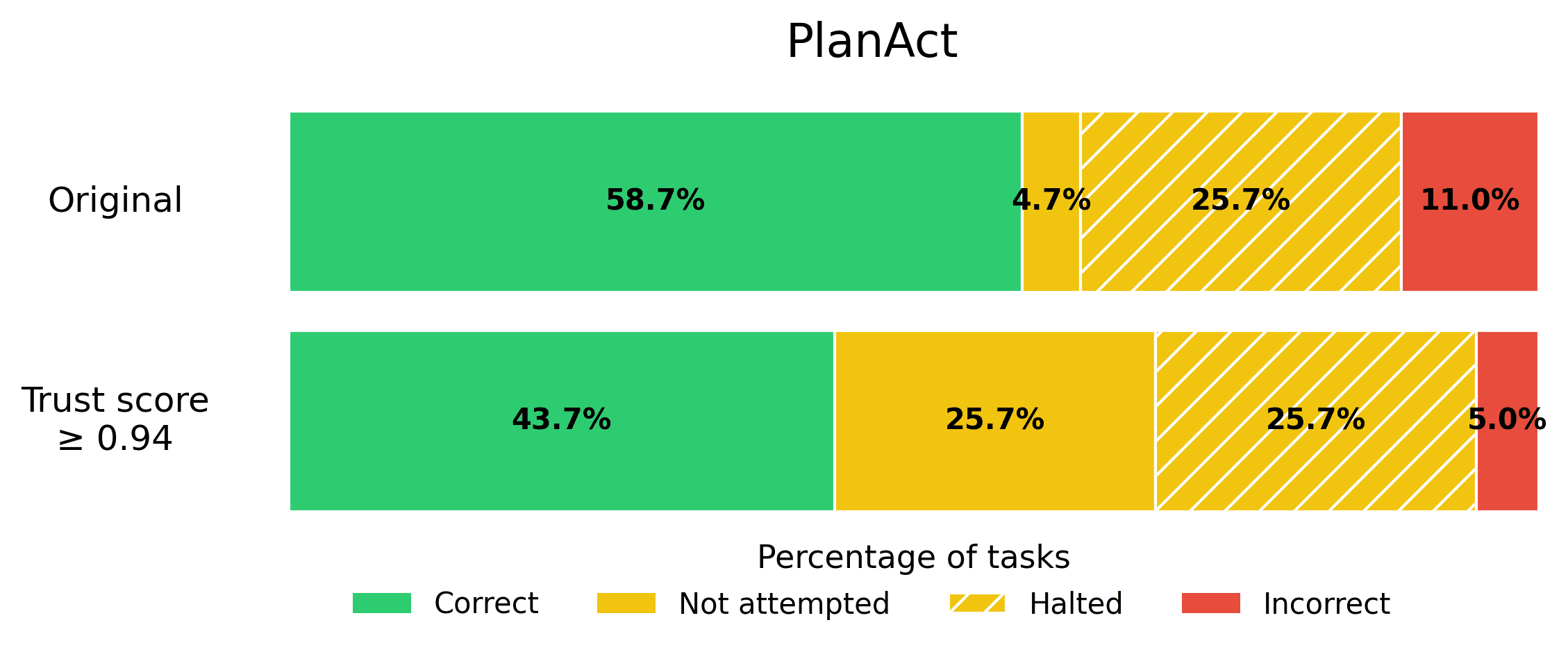
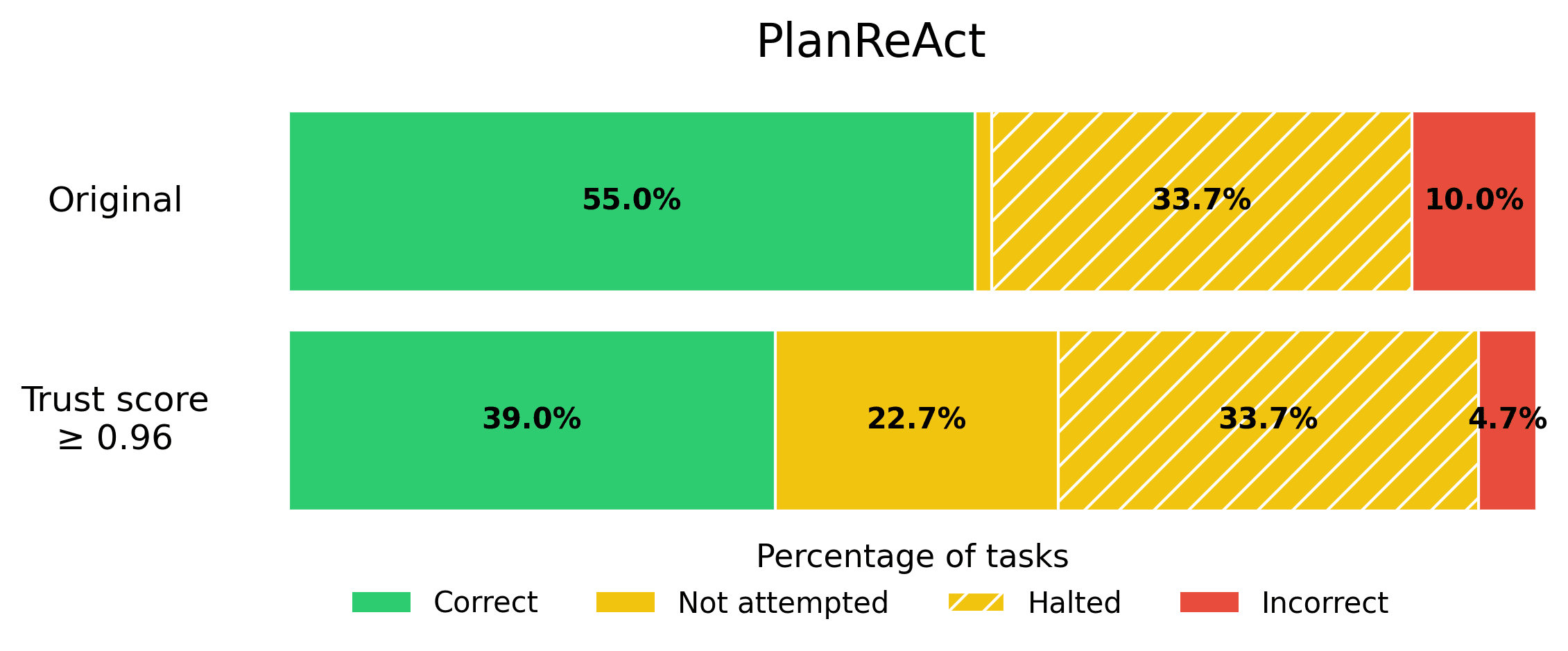
Note that trust scoring allows us to achieve the 5% error rate requirement, without sacrificing the helpfulness of our AI Agent too severely.
Trust scoring is best for use-cases where you need to tightly control AI Agent error rates. If you instead want an AI Agent that feels helpful no matter what (i.e. never abstains from answering) even if it actually gets many answers wrong, then trust scoring is probably not applicable for your use-case. For example, a general-purpose consumer AI provider like OpenAI is incentivized for their AI to seem extremely helpful, and this is why hallucinated/incorrect responses are common from their API.
Don’t Just Build Smart Agents - Build Trustworthy Ones
Reasoning, planning, and tool use are great but they don’t eliminate errors. Cleanlab gives Agents a final layer of defence: don’t say it if you can’t trust it.
Try Cleanlab’s TLM API for free, and add real-time trust scores to any LLM/Agentic application within minutes.
Appendix
We also ran some additional studies in our benchmark. Expand each collapsible section below to learn more.