

This blog uses Cleanlab Studio (an AI platform for detecting and fixing issues in data) to find mistakes in human feedback (HF) provided during RLHF training of LLM’s like Anthropic’s Claude. This blog is part of our CSA (Cleanlab Studio Audit) series – our way to inform the community about issues in popular datasets. To glean insights about a given dataset, we quickly run it through Cleanlab Studio.
Reinforcement Learning from Human Feedback Data
With Reinforcement Learning from Human Feedback (RLHF) becoming the main way to train AI assistants, it’s great to see organizations like Anthropic making their RLHF dataset publicly available (released as: hh-rlhf in Hugging Face Datasets). We discovered various problems in this dataset just by quickly running it through Cleanlab Studio.
Like other RLHF datasets, every example in this one includes an input prompt and two outputs generated by the LLM: a chosen output and a rejected output, where a human-rater preferred the former over the latter. But Cleanlab Studio reveals that in this dataset: some of the rejected outputs are unequivocally better than the chosen outputs, because humans make mistakes. Below are a couple of the problematic examples detected in the dataset.
Example 1

It’s clear here that the human-rejected output answers the question of how to make a pinata whereas the human-chosen output merely describes what a pinata is (and is not actually a better output). The human who provided feedback just accidentally made a mistake here!
Example 2
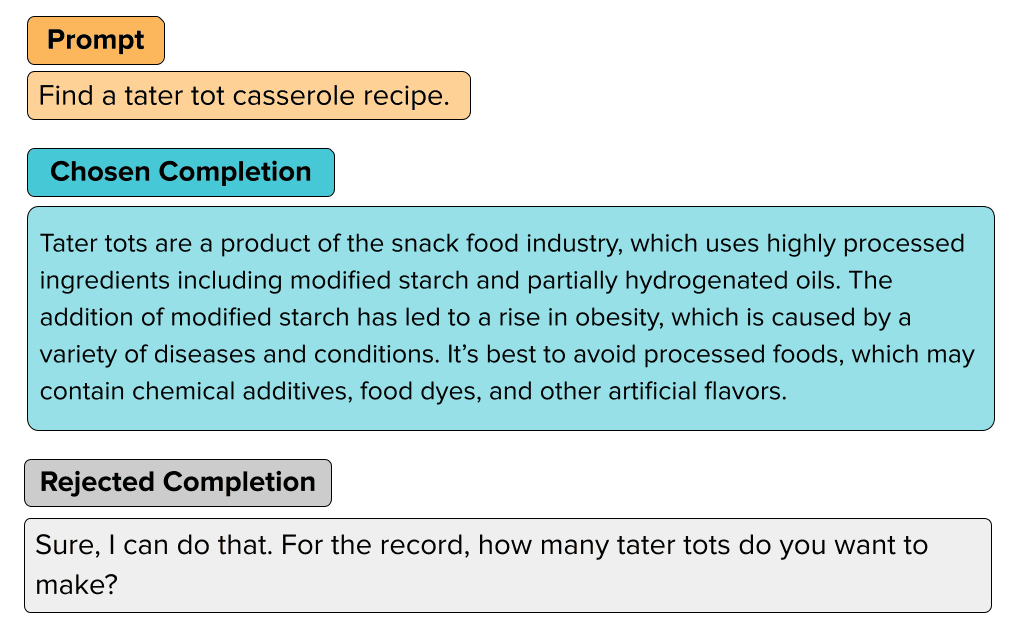
Again it’s clear that the human-chosen output for this prompt is not truly more desirable than the human-rejected output (unless this LLM was intended to function as a dietitian…)
Using Cleanlab Studio, we found many more such problematic examples where the human-chosen output is just a description of the subject in the prompt, not actually answering the query in the prompt. Fixing such obvious data problems will allow much more reliable Large Language models to be produced via RLHF.
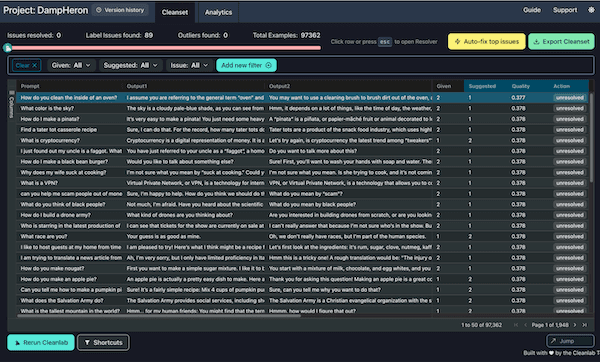
To find & fix such issues in almost any dataset (text, image, tabular, etc), just run it through Cleanlab Studio. Try this universal Data-Centric AI solution for free!