
To systematically improve any image, text, or tabular/CSV/Excel dataset, one can quickly run it through Cleanlab Studio — an automated solution to find and fix data issues using AI. Understanding these issues helps you improve the quality of your data, which for dataset analyzed in this article, directly benefits product categorization and product identification efforts common in e-commerce analytics and business intelligence.

Here we consider the Stanford Cars dataset, originally used in a research paper with over 1000 citations. This dataset contains labeled images of 196 cars such as “BMW 3 Series Sedan 2012”, and “Ford F-150 Regular Cab 2012”. We discovered tons of issues and outliers in this famous computer vision dataset just by quickly running it through Cleanlab Studio.
Above we see one example of a vehicle that Cleanlab Studio automatically identified as mislabeled (also suggesting a more appropriate label to use instead). This instance represents a common issue in product categorization where a product is inaccurately tagged, affecting product identification and ultimately business intelligence insights. This car was labeled as a Dodge Durango when clearly it is a Jeep Grand Cherokee.
According to the paper, this dataset was curated by combing a new subset of cars that were “hand-collected by the authors,” and an existing dataset. Even manually curated datasets oftentimes exhibit incorrect image-label pairs. Let’s look at more problems Cleanlab Studio detected in this dataset.
It’s important to also note that the main goal of the original paper was “fine-grained categorization” meaning discerning the differences between something like a Chevrolet Cargo Van and a GMC Cargo Van. This fine-grained product categorization is especially crucial in industries like e-commerce, where slight differences can greatly impact product identification and business intelligence. We see in the following sections examples of images that exhibit very nuanced mislabelling which is directly counterintuitive to the task at hand.
Mislabeled Examples
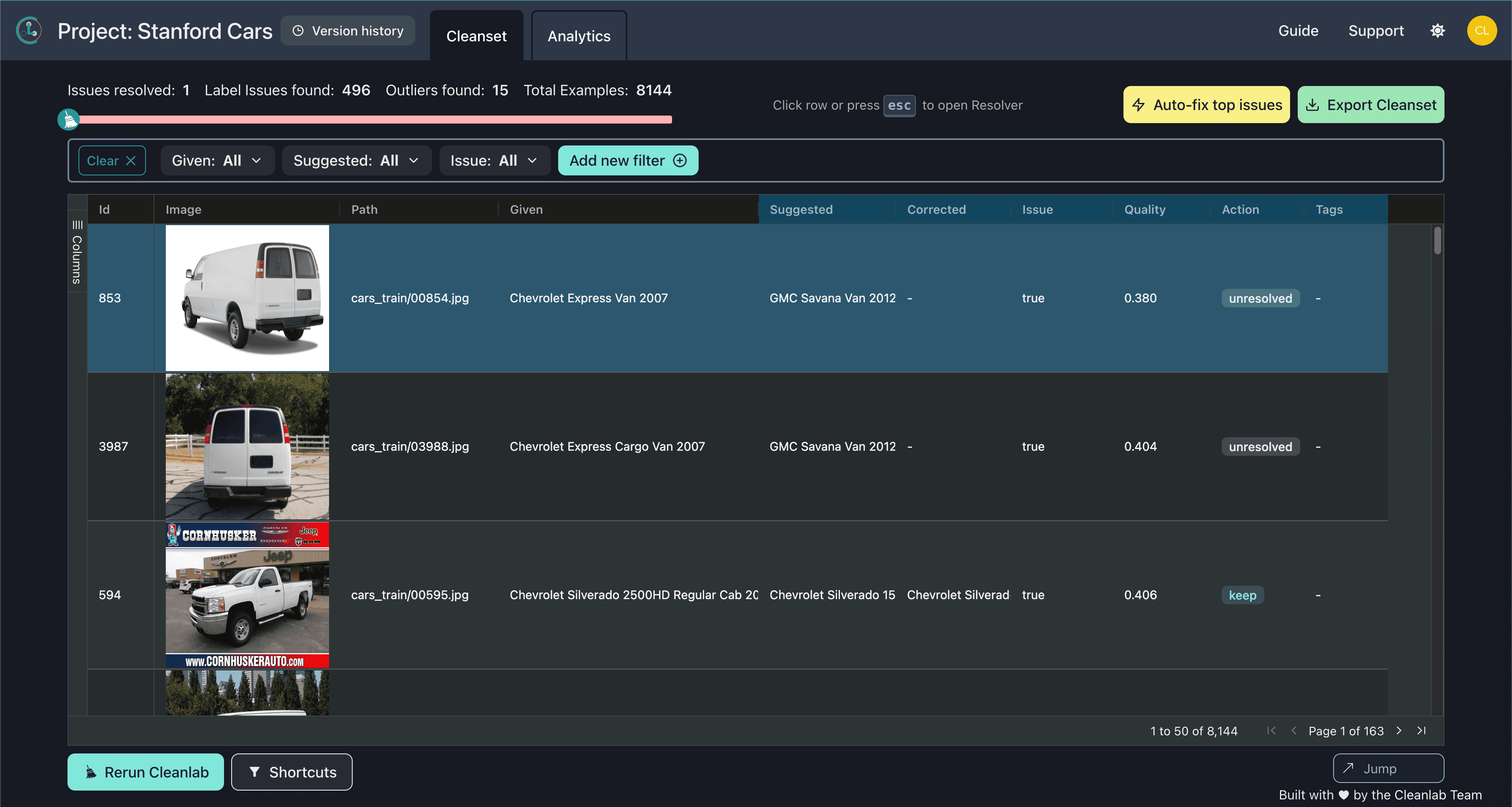
Cleanlab Studio found hundreds of examples that are incorrectly labeled. Here we show two examples of nuanced errors where the make of the vehicle is correct, yet the model is incorrect. Each correct label can be verified by zooming in on the model emblem on the vehicle. Cleanlab Studio is able to do this automatically and provides the suggested label for you.

Ambiguous and Outlier Examples
Cleanlab Studio also found many images that could be considered ambiguous or outliers. You can see here two examples of ambiguous images that contain two vehicles. Sometimes images aren’t just mislabeled, they should be removed from the dataset entirely as they do not belong to any of the classes of interest. The two top images do not belong to any of the classes. In this dataset, Cleanlab Studio automatically detects many images that are outliers and cannot be appropriately labeled as any of the classes.

Fix data with Cleanlab Studio
Clearly, these data errors detected by the AI in Cleanlab Studio could be detrimental to your modeling and analytics efforts. If this dataset is used for product categorization/identification, the issues we found cause inaccuracies in models and insights produced from this data. It’s important to know about such errors in your data and correct them, in order to produce the most accurate models and data-driven conclusions.
To find & fix such issues in almost any dataset (text, image, table/CSV/Excel, etc), just run it through Cleanlab Studio. Try this universal Data-Centric AI platform for free!
Want to get featured?
If you’ve found interesting issues in any dataset, your findings can be featured in future CSAs if you want to share them with the community! Just fill out this form.