




TL;DR
- Expert Guidance lets teams instantly improve AI behavior with human feedback.
- Helps agents reason better, communicate clearly, and understand intent accurately.
- Teach your AI how to behave correctly, directly in production, without retraining.
Most enterprises are racing to get AI agents into production. But once they’re live, a harder question emerges: how do you keep improving them as the world changes and new questions arise? Engineering cycles move in weeks or months, but your agents need updates that happen in minutes or hours.
Expert Guidance by Cleanlab provides a faster way to improve AI agents with humans in the loop. It enables any non-engineer to guide AI behavior in natural language, just as they would a human teammate. The AI learns instantly, with no retraining or fine-tuning required.
Let’s look at how it works in practice.
How Expert Guidance Improves AI Behavior
Expert Guidance helps when your AI completes tasks but not always in the way you intended. These are behavioral challenges that appear once agents start using tools, making multi-step decisions, or following complex workflows.
Maybe the AI has access to the right systems but executes actions in the wrong order, skips a validation step, or misinterprets a condition that a human would catch instantly. With Expert Guidance, teams can capture these moments and teach the AI how to handle similar situations more effectively next time.
It gives teams a faster, safer way to refine behavior in production using the expertise they already have.
To see how this works in practice, let’s look at three common areas Expert Guidance improves: reasoning, communication, and understanding.
| Behavior Type | Goal of Expert Guidance | Example (Airline AI Agent) |
|---|---|---|
| Reasoning | Helps the AI follow the correct steps or workflow | Confirming departure/arrival airports before searching for flights |
| Communication | Helps the AI communicate clearly and helpfully | Using tables and breakeven points to compare different passes |
| Understanding | Helps the AI interpret user intent accurately | Recognizing specific brands as smart luggage rather than mobility equipment |
Example 1: Improving How the AI Reasons
Take a simple case from an airline assistant. Expert Guidance can strengthen how the AI reasons through multi-step logic before acting.
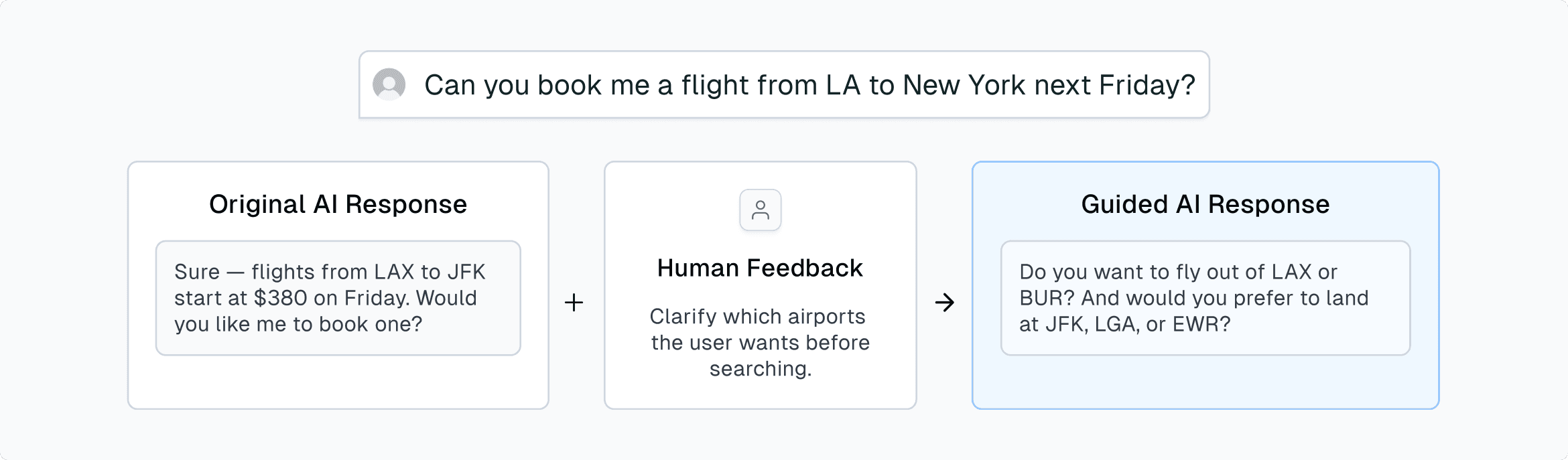
Workflow steps must be precise; small errors can cascade into future actions. In this case, the AI’s booking flow received human feedback to clarify what information it needs to accurately find and reserve flights.
Later, when a user asks “Book me a flight from Los Angeles to Chicago,” that same guidance ensures the agent confirms LAX vs. BUR and ORD vs. MDW before continuing. No prompt changes required.
Example 2: Improving How the AI Communicates
Expert Guidance is equally powerful for refining how an AI communicates. Sometimes the problem isn’t that the answer is wrong, but that it’s hard for users to interpret or act on.
Take a travel assistant helping customers choose between two GoWild! all-you-can-fly passes.
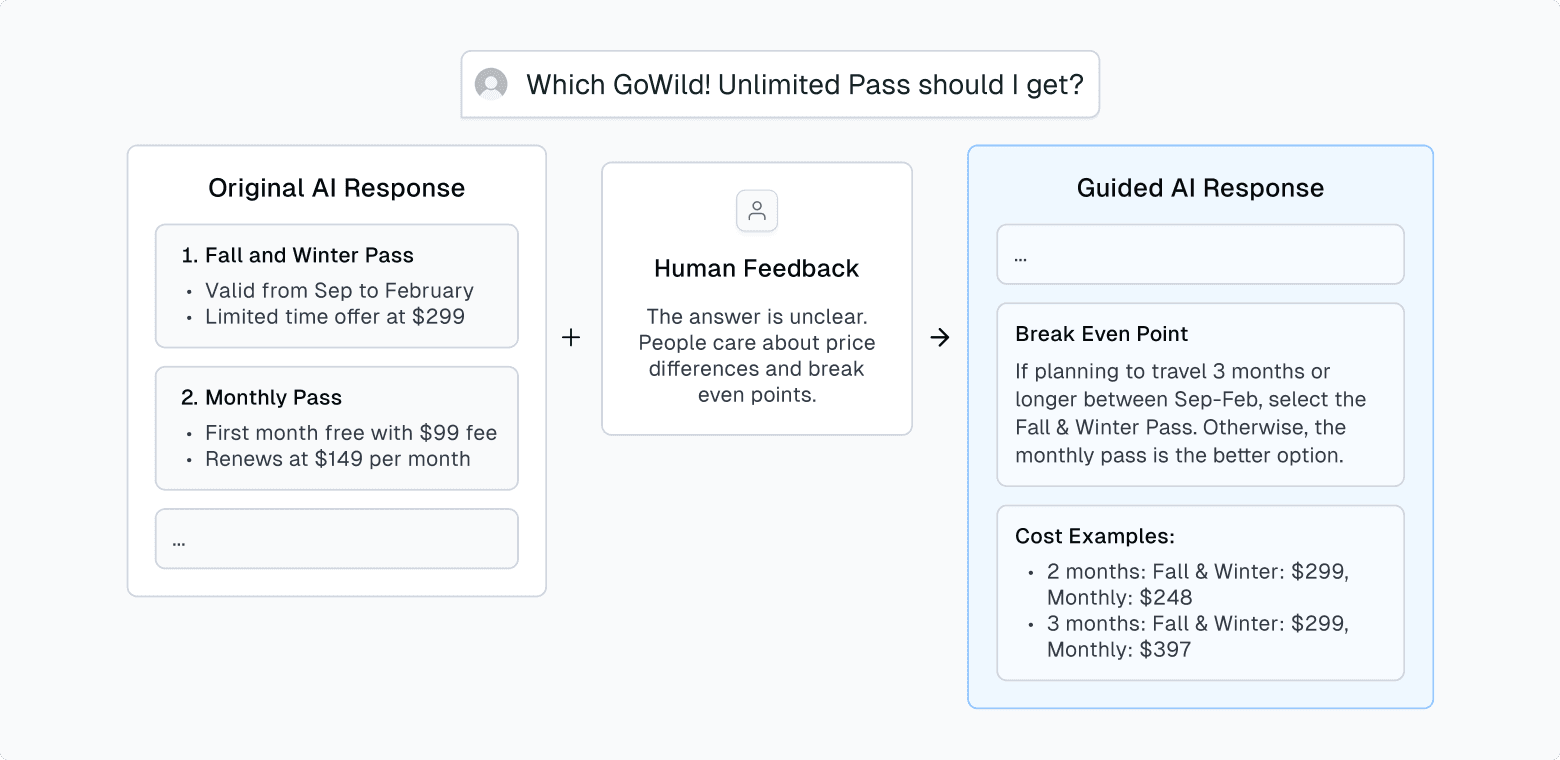
The AI’s original answer was factually correct but unhelpful. Users still couldn’t tell which option to choose. With Expert Guidance, the AI learned to present comparisons using pricing tables and breakeven points, making tradeoffs easier to understand.
Now, when users ask about other plan comparisons, the agent automatically applies that same clear, consistent structure.
Example 3: Improving How the AI Understands
Expert Guidance helps AI interpret meaning more accurately, especially when queries include ambiguous or undefined terms. Consumer brands are an example of terms that users are familiar with, but are topics where AI may not be.
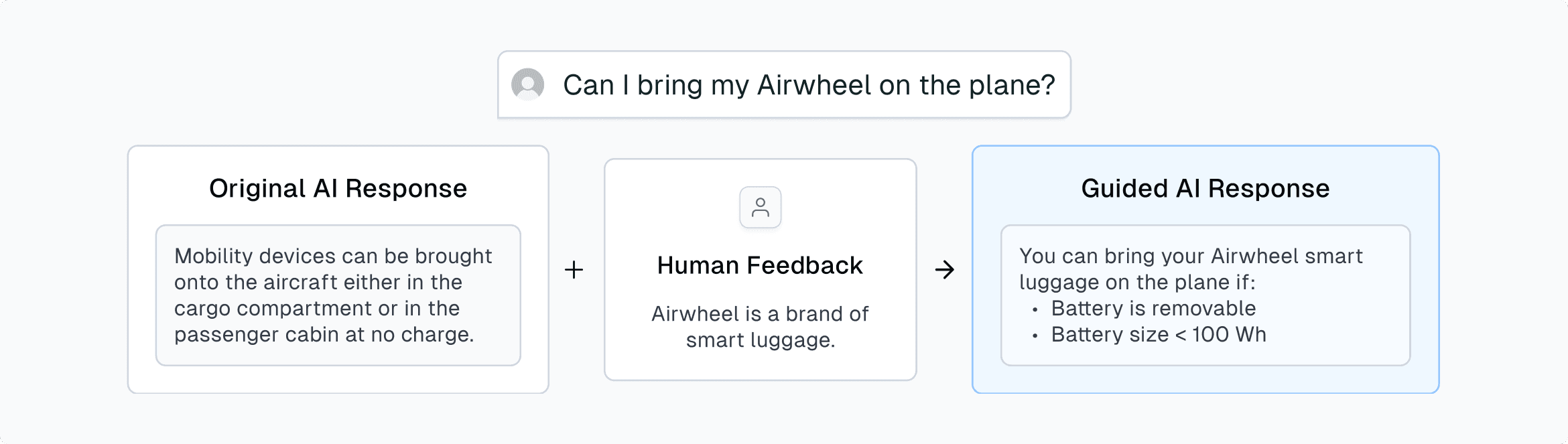
This guidance taught the AI to recognize Airwheel as a smart luggage brand. In this example, instead of the AI using a tool call to get information about mobility devices (pictured left), it’s now using a tool call to pull relevant documents related to smart luggage (pictured right).
What This Looks Like in a Real Customer Support Workflow
To measure the impact of Expert Guidance, we evaluated the same AI agent before and after adding guidance for a customer-support use case at a major airline. Both evaluations were run on the same 218 customer interactions, and expert reviewers assessed which responses were incorrect.
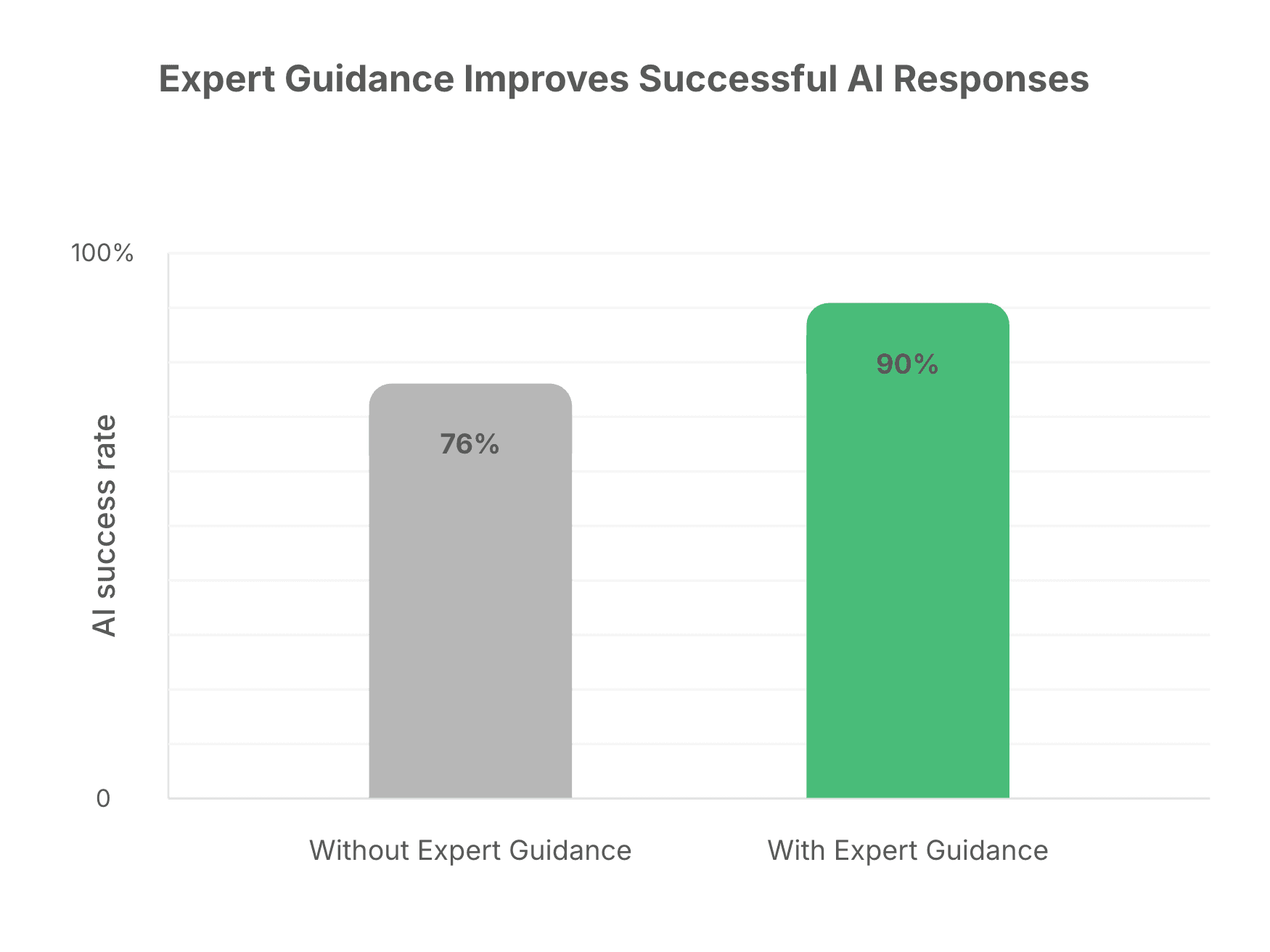
With just 13 guidance entries, the agent’s success rate improved from 76% to 90% on the same tasks.
How Expert Guidance Works
Every improvement starts with simple human feedback. In the Cleanlab platform, subject-matter experts (SMEs) can easily review past agent responses, mark them as incorrect, and explain what went wrong or how to improve it. Cleanlab’s detection layer automatically identifies and ranks AI failures, prioritizing the most common or highest-impact issues so experts focus only where their input makes the biggest difference.
After an SME submits feedback on a problematic AI response, Cleanlab converts that feedback into an Expert Guidance entry, transforming raw comments into structured, reusable instructions that the AI can apply in future scenarios to avoid similar errors.
When your AI encounters a similar scenario, Cleanlab’s scenario-matching system will return this Guidance through the API — allowing your engineers to inject it into the prompt just-in-time to improve the AI’s response. This system operates at ultra-low latency, combining vector database semantic search with preemptive hierarchical scenario extraction to recognize related contexts and scale across countless scenarios.
In short, Cleanlab not only determines when guidance applies but also how raw human feedback can be converted into effective, context-aware advice for AI agents.
From Human Feedback to AI Behavior Change
Expert Guidance turns human feedback into lasting improvements in how your AI behaves. Cleanlab automatically detects and prioritizes high-impact issues, and transforms raw feedback into guidance the AI reuses across related scenarios.
Each correction compounds into greater reliability over time, helping teams keep agents aligned and dependable in real deployments.
Learn more in the Cleanlab platform or explore our docs to see how it works in your own agents.