


Data quality is paramount in instruction tuning, a popular method to improve the performance of pre-trained Language Models (LLMs) for specific tasks. Low-quality examples lurking in the dataset hamper LLM instruction tuning, resulting in poor performance. Such bad data is prevalent in real-world datasets and hard to catch manually. Here we demonstrate an automated solution to detect low-quality data in any instruction tuning dataset, which caught issues like this in the databricks-dolly-15k dataset:
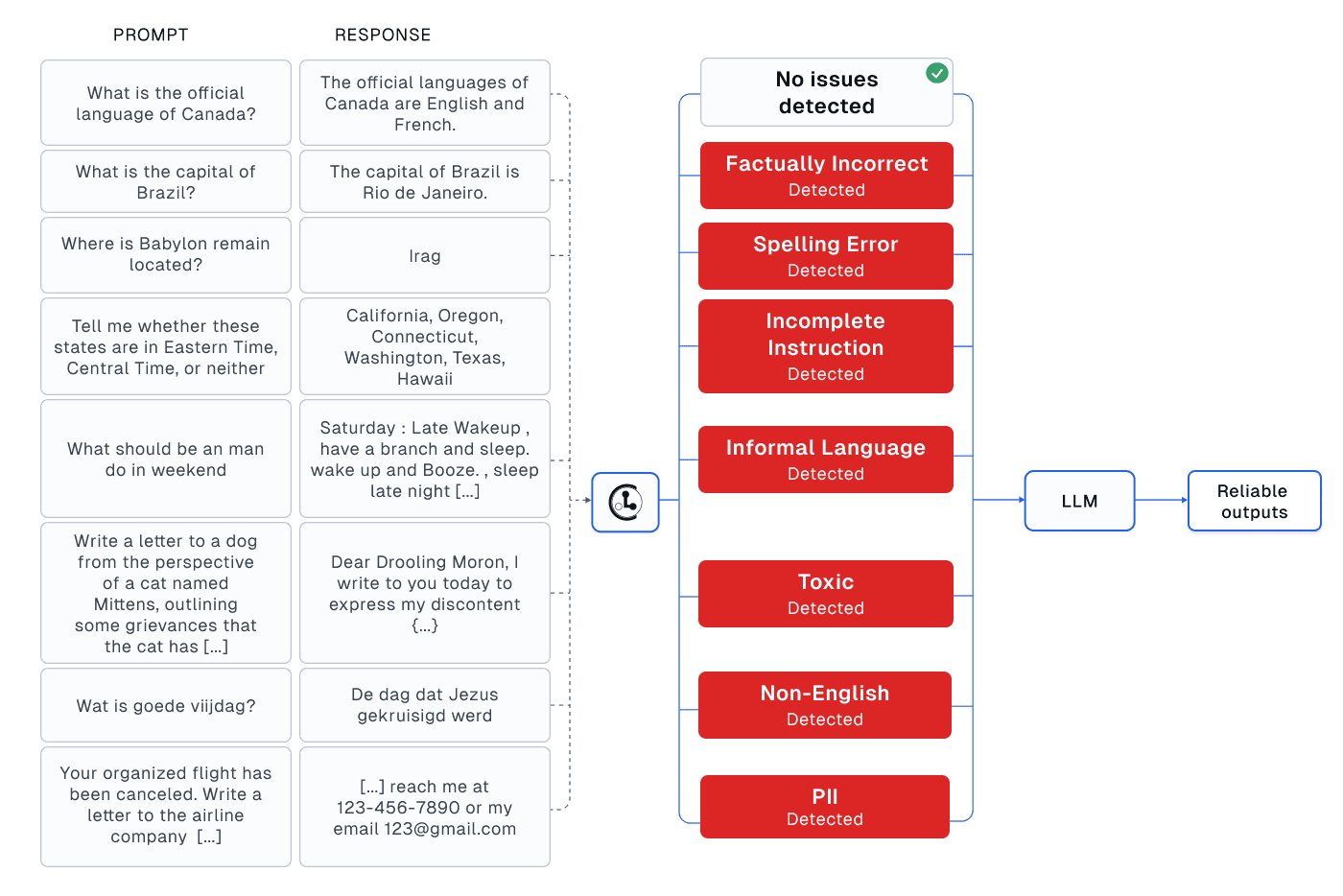
In instruction tuning (also known as alignment or fine-tuning), LLMs are trained using human-written or synthetically-generated target responses that the model should imitate for new requests. One of the most famous instruction tuning datasets is the human annotated databricks-dolly-15k dataset, which was used to fine-tune the famous Dolly 2.0 model and many other popular LLMs. This dataset contains 15,000 instruction-response pairs covering various categories (such as: Q&A, Information Extraction, Summarization, Brainstorming, Creative Writing, Classification). Significant human effort was utilized to curate this dataset and ensure high-quality responses (over 5000 employees’ time), but we can see that lots of bad data is still present (as inevitably happens for all real-world instruction tuning datasets).
This article demonstrates Cleanlab Studio as an automated tool for catching: low-quality responses, incomplete/vague prompts, and other problematic text (toxic language, PII, informal writing, bad grammar/spelling) lurking in any instruction-response dataset. We can significantly boost LLM fine-tuning efforts by detecting such problematic data points in the dataset, and then filtering or fixing them. Bad data hampers not only LLM fine-tuning but evaluation as well.
All data issues shown in this article were automatically discovered using Cleanlab Studio (via just a few lines of code and hardly any of our own time). The code to reproduce all results is shared here. You can follow this tutorial to automatically catch such issues in your own supervised fine-tuning dataset.
Find questionable responses via Cleanlab TLM
How does the Cleanlab Studio data-centric AI platform detect bad data? It is powered by many novel algorithms and ML models invented by Cleanlab scientists, one of which is Cleanlab’s Trustworthy Language Model (TLM). This LLM outputs a trustworthiness/confidence score along with each of its responses, which helps you determine how much to trust it. TLM can additionally score the confidence of any given response, such as a human written response. These trustworthiness/confidence scores account for both aleatoric and epistemic uncertainties, offering a more comprehensive assessment with better calibration than relying solely on say token probabilities. Here we dive into the examples in the databricks-dolly-15k dataset that received the lowest TLM confidence scores (applied to the given instruction-response pair in the dataset), and discuss different types of problems revealed by this automated process.
Factual inaccuracies
Below we show some of the lowest confidence/trustworthiness responses identified by Cleanlab Studio in the databricks-dolly-15k dataset. Along with each response, we show Cleanlab’s TLM-estimated confidence score, as well as what the correct response should be. Note these responses are factually inaccurate, having them in the training data for a LLM can encourage the resulting model to spread misinformation.
| Instruction | Response | Category | Cleanlab Trustworthiness Score | Correct Response |
|---|---|---|---|---|
| Who invented the airplane? | The airplane was invented by Santos Dumont, a Brazilian inventor. He flew for the first time in France, in the year of 1906. | open_qa | 0.000750 | The airplane was invented by the Wright brothers, Orville and Wilbur Wright, in 1903. |
| What’s the capital of Brazil? | The capital of Brazil is Rio de Janeiro. | open_qa | 0.008427 | The capital of Brazil is Brasília. |
| When does the world celebrate Hindi diwas every year? | On January 10 | open_qa | 0.027285 | On September 14 |
| Which of these are dogs and which are birds: Phoenix, Siberian Husky, Alaskan Malamute, Hawk, Border Collie, Labrador, Araucana | Birds: Phoenix, Siberian Husky, Alaskan Malamute, Border Collie, Labrador Dogs: Siberian Husky, Alaskan Malamute, Border Collie, Labrador | classification | 0.174656 | Birds: Phoenix, Hawk, Araucana Dogs: Siberian Husky, Alaskan Malamute, Border Collie, Labrador |
Context-based inaccuracies
In this databricks-dolly-15k dataset, Cleanlab Studio also automatically detected many responses that are inaccurate based on the provided context. This problem is common for information extraction or Q&A prompts that require properly reasoning about the knowledge provided in the input instruction. Below we show some examples like this found amongst the set of instruction-response pairs with the lowest TLM-estimated confidence score. Again, such data should certainly not be included in a LLM training dataset.
Context: Liebers is a German language surname. Notable people with the name include: Mario Liebers (born 1960), German former competitive figure skater; Martin Liebers (born 1985), German former competitive figure skater; Matthias Liebers (born 1958), former German footballer; Peter Liebers (born 1988), German former figure skater.
Question: Which notable person having surname Liebers in this list was born first?
Response: Mario Liebers
Cleanlab Trustworthiness Score: 0.007659
Correct Response: Matthias Liebers
This example shows an error resulting from inaccurate chronological comparison based on birth years. Fixing such hard examples can help increase the complexity of data which is an important factor in fine-tuning LLMs to learn complex tasks.
Context: In 2011 Kathy Ryan, director of photography for The New York Times Magazine, commissioned Prager to shoot 12, 1 minute films with some film actors from that year, inspired by “cinematic villainy”. Prager won a News and Documentary Emmy Award for New Approaches to News & Documentary Programming: Arts, Lifestyle & Culture for her Touch of Evil short films.
Question: What magazine was Alex Prager the director of Photography for?
Response: Alex Prager was the director of photography for the New York Times Magazine.
Cleanlab Trustworthiness Score: 0.064139
Correct Response: The information provided states that Kathy Ryan was the director of photography for The New York Times Magazine, not Alex Prager.
In the above example we can note that either the information is not present in the context or a wrong question is being asked. The author probably meant What magazine was Kathy Ryan the director of Photography for?. Such examples can aggravate the hallucinations of LLMs. In such cases, either a clarification question should be asked further or it should refuse to answer as its lacking information. Either way, it’s a low quality example that can affect the performance of fine-tuned LLMs.
Context: Memphis is the fifth-most populous city in the Southeast, the nation’s 28th-largest overall, as well as the largest city bordering the Mississippi River and third largest Metropolitan statistical area behind Saint Louis, MO and the Twin Cities on the Mississippi River. The Memphis metropolitan area includes West Tennessee and the greater Mid-South region, which includes portions of neighboring Arkansas, Mississippi and the Missouri Bootheel. One of the more historic and culturally significant cities of the Southern United States, Memphis has a wide variety of landscapes and distinct neighborhoods.
Question: What is the largest city on the Mississippi River?
Response: Saint Louis, Missouri is the largest city on the Mississippi River. Twin Cities is the second largest city on the Mississippi River and Memphis is the third largest city on the Mississippi River.
Cleanlab Trustworthiness Score: 0.255350
Correct Response: The information provided states that Memphis, Tennessee is the largest city bordering the Mississippi River.
This example highlights an error in extracting and interpreting detailed information correctly. These kinds of responses can also induce the tendency to give long answers instead of concise ones, apart from being incorrect.
Incomplete/vague prompts
When examining the other examples that received the lowest TLM trusthworthiness/confidence scores amongst this databricks-dolly-15k dataset, we find many of these instances have instructions which are not fully specified (some shown below). It seems these incomplete-looking instructions somehow got truncated, perhaps some of the instruction was accidentally recorded as part of the response. Cleanlab Studio is able to detect such examples, recognizing what consistutes a good response is impossible to confidently determine when the instruction is vague. Including such ambiguous examples in LLM training data is often a major culprit behind why the fine-tuned model does not perform well.
| Instruction | Response | Category | Cleanlab Trustworthiness Score |
|---|---|---|---|
| Tell me whether these states are in Eastern Time, Central Time, or neither | California, Oregon, Connecticut, Washington, Texas, Hawaii | classification | 0.014588 |
| Categorize these superheroes as ‘Marvel’ or ‘DC Comics’ | Thor, Flash, Iron Man, Super Man, Wonder Woman, Captain America | classification | 0.172828 |
Spelling errors
When examining other responses that received the lowest TLM confidence scores amongst this databricks-dolly-15k dataset, we find many of these instances have spelling errors or are otherwise poorly written (some shown below). Of course, one should not train a LLM to reproduce these flawed responses.
| Instruction | Response | Category | Cleanlab Trustworthiness Score | Correct Spelling |
|---|---|---|---|---|
| classify the following as mammals vs reptiles: goat snake cockroach pig dog caterpillar lion | mammals: goat, pig, dog, lion reptiles: snack, cockroach, caterpillar | classification | 0.080254 | snake |
| Where is Babylon remain located? | Irag | open_qa | 0.038063 | Iraq |
Detecting other problematic text via a Cleanlab Studio Project
Beyond the TLM model, Cleanlab Studio offers a variety of other automated algorithms that detect problematic text in any dataset (whether instruction tuning or other sorts of more general text). These algorithms are automatically run in every Cleanlab Studio Project for a text dataset, and can be applied without writing a single line of code! Each of these algorithms in the Cleanlab Studio Project aims to detect a certain type of data issue and flags which examples exhibit this issue, as well as scoring the severity of the issue in each example (higher scores generally correspond to more problematic text).
Toxic Language
Cleanlab Studio automatically flagged some text in this databricks-dolly-15k dataset as toxic (examples shown below). One probably wants to avoid including such text amongst any of the responses present in a LLM training dataset.
| Text | Toxicity Score |
|---|---|
| People that pour milk before cereal??? People that pour MILK before CEREAL??? Are you out of your mind?? When you pour milk before cereal you not only do a disservice to yourself but you are fighting tooth and nail to collectively drag the human race ten steps back to the stone age. You are morally bankrupt and your soul is in ANGUISH. You absolute mongrels. You blithering neanderthals. […] | 0.862 |
| Dear Drooling Moron, I write to you today to express my discontent (that means unhappiness) regarding our current living situation. You may or may not have noticed, considering your obliviousness to anything that isn’t food related, that you actually live in a house with other animals. […] | 0.847 |
Personally Identifiable Information (PII)
Cleanlab Studio also automatically flagged some text in this databricks-dolly-15k dataset as containing PII (example shown below). We see this text contains potentially sensitive information that could be used to identify an individual. One probably wants to avoid including such text amongst any of the responses present in the training dataset of a LLM that is not supposed to divulge personal information.
| Text | PII Score |
|---|---|
| Hi Delta Airline, I am Ao Ni, I send this email regarding […] You can reach me at 123-456-7890 or my email mailto:123@gmail.com. | 0.5 |
| […] the emails for those people would be: Jon Doe: mailto:jdoe@somecompany.com Richard Smith: mailto:rsmith@somecompany.com Tom Jenkins: mailto:tjenkins@somecompany.com Nick Parsons: mailto:nparsons@somecompany.com | 0.5 |
Informal Language
Cleanlab Studio also automatically flagged some text in this databricks-dolly-15k dataset as being informal, meaning it lacks: proper spelling/grammar or polished writing. One probably wants to avoid including such text amongst any of the responses present in the training dataset for a LLM that is supposed to appear professional.
| Text | Informal Score |
|---|---|
| Wat id DNA annotation? | 0.771 |
| What if a buff? | 0.717 |
| Was She Couldn’t say No movie re-released? | 0.715 |
| Who where the San Diego Stingrays? | 0.695 |
| Is PM Modi is honest | 0.687 |
Non-English Text
Cleanlab Studio also automatically flagged some text in this databricks-dolly-15k dataset as being non-English. In this case, Cleanlab automatically inferred the text to be of the Dutch language. One likely wants to be aware of such text in an otherwise predominantly English dataset.
| Text | Non English Score | Predicted Language |
|---|---|---|
| Goede Vrijdag is de vrijdag voor Pasen. Op deze dag herdenken christenen de kruisiging en dood van Jezus. […] | 0.861 | Dutch |
Conclusion
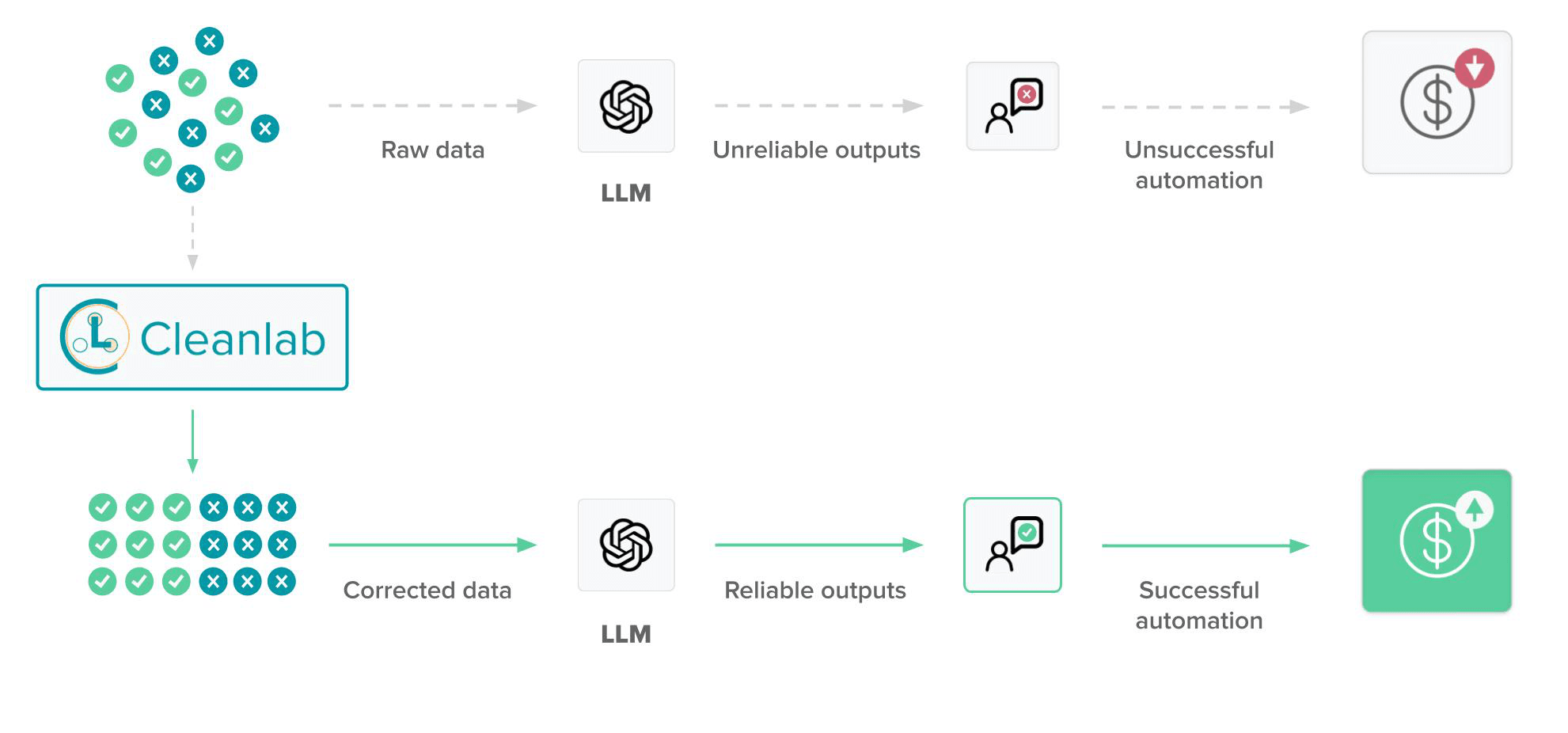
Ensuring the quality of your instruction tuning datasets is key to graduating LLMs from demos into production applications. Without careful curation, your instruction tuning data will inevitably be full of problematic instances and edge-cases that prevent your LLM from behaving reliably. Cleanlab Studio (along with its Trustworthy Language Model) offers a quick solution to automatically curate LLM fine-tuning data. In the databricks-dolly-15k dataset, Cleanlab Studio automatically detected a variety of data quality issues across multiple types of prompts and responses. Data auto-detected to be bad can either be filtered from the dataset, or manually corrected. This is the fastest way to improve the quality of your existing data!
Resources
- Try Cleanlab Studio to curate your own text or LLM dataset for free.
- Learn how to automatically catch such issues in your own supervised fine-tuning dataset via a quick tutorial.
- Check out the code we used to produce the findings presented in this article.
- We’ve released databricks-dolly-15k-cleanset, which provides Cleanlab’s various data quality scores for each datapoint in the original dataset. You can use these scores to easily curate your own improved version of the dataset. Here’s an improved version of the dataset we instantly curated by filtering all datapoints estimated to be low-quality: databricks-dolly-15k-cleaned.
- If you are interested in building AI Assistants connected to your company’s data sources and other Retrieval-Augmented Generation applications, reach out to learn how Cleanlab can help.