Machine learning has traditionally followed a model-centric approach, with the primary focus placed on optimizing model architecture, algorithms, and hyperparameters while treating training data as largely fixed.
Take GPT models as an example. From GPT-1 to GPT-4, OpenAI researchers found that simply training on “more data” did, in fact, improve performance. That paradigm, however, is coming to an end, as performance increases plateau with just more data.
A book from 2016 explored why small data is the new big data. While perhaps ahead of its time, the ideas were prescient for the challenges AI practitioners face today. With massive datasets readily available, it’s no longer sufficient to just collect more data. Rather, the focus must shift to creating more high-quality, representative data.
This revelation is fueling a paradigm shift towards data-centric AI. It is already becoming commonplace for top research universities like MIT to provide classes about DCAI.
What Is Data-Centric AI and Why It Matters
Data-centric AI (DCAI) is a systematic approach to curating, managing, and enhancing training data through its full lifecycle to drive increased model accuracy. The key principles of DCAI are placing primary focus on elevating data above models, adopting programmatic and scalable data workflows, directly involving subject matter experts in the data pipeline, and continuously improving data based on model feedback.
In short, DCAI treats the improvement of training data as a software engineering discipline in its own right, rather than a one-time preprocessing step before modeling occurs. Under this paradigm, data is viewed as a living, evolving asset that requires careful stewardship and engineering, not a static input bundled together once and forgotten. The quality of the training data becomes a primary driver of model capabilities rather than merely model architecture.
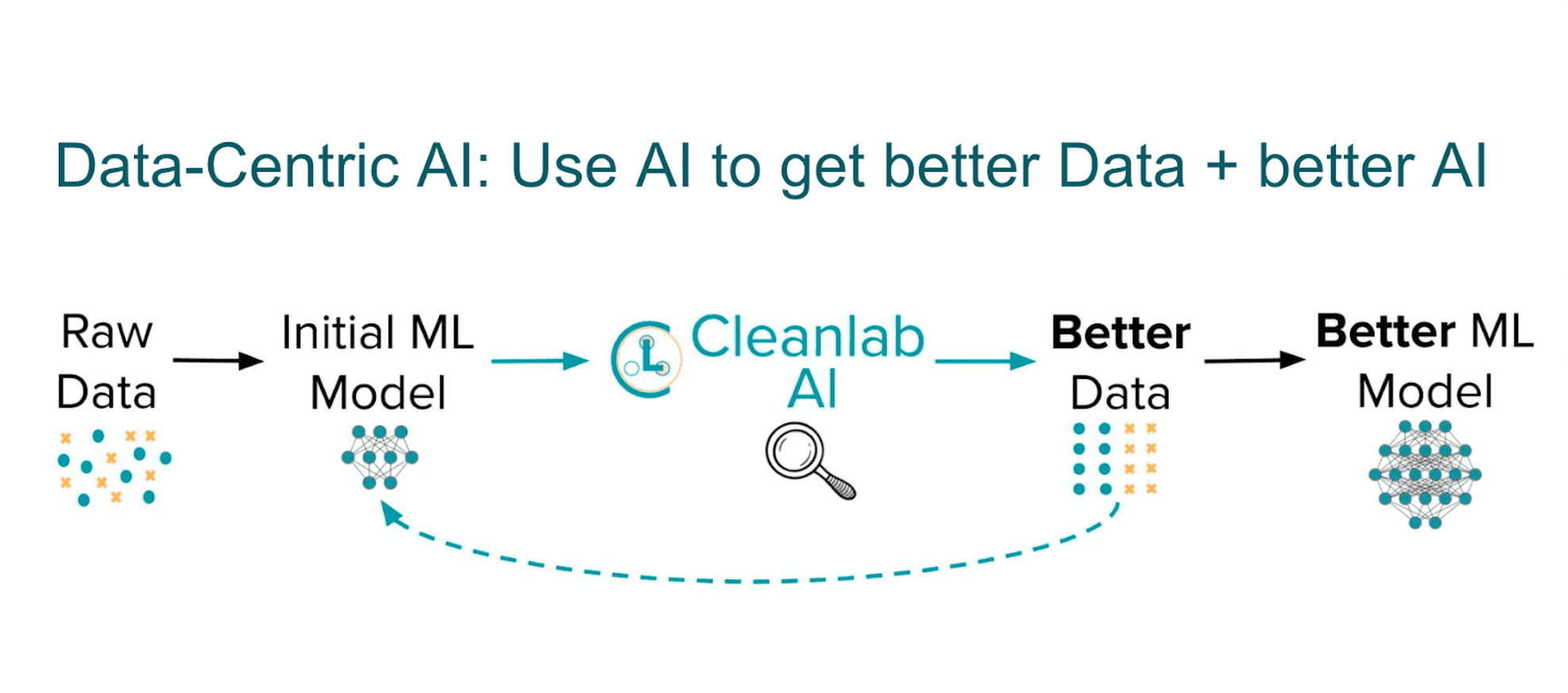
Some key characteristics of the data-centric approach include treating data as a strategic asset requiring ongoing investment and engineering, not just passive collection. This means carefully designing, documenting, versioning, monitoring, and actively enhancing training data.
It means adopting programmatic, scalable data pipelines and workflows to replace manual processing which is not sustainable at scale. It requires directly involving subject matter experts in the curation process so their domain knowledge can be injected into the training data. And it necessitates continuously analyzing data and improving it based on model feedback through redos like error analysis.
Above all, data quality and fitness for the model’s purpose becomes a top strategic priority and competitive differentiator, not an afterthought. High-quality training data is actively crafted to feed capable models, which in turn analyze that data to drive further improvements. This creates a flywheel effect on model accuracy and ultimately business value.
OpenAI’s “data flywheel” puts this into practice, enabling state-of-the-art large language models.
Limitations of the Model-Centric Approach
The conventional approach to machine learning has been model-centric, with nearly all focus placed on model architecture, algorithms, and hyperparameters while largely treating training data as a fixed input. But this approach has inherent limitations including brittleness to poor data quality, lack of scalability, hunger for massive labeled datasets, separation of data from models, and over-reliance on custom modeling.
Issues like label errors, noise, bias, and stale data in training sets all undermine model accuracy regardless of how well the model itself is engineered and tuned. And no amount of model tweaking can rescue low-quality data or compensate for gaps in training data that fail to capture real-world diversity.
As training set sizes swell into millions or billions of rows, manual techniques for data collection, cleaning, labeling, and augmentation clearly do not scale. Yet model-centric AI generally relies on ad hoc human wrangling versus programmatic and automated data pipelines capable of handling tremendous scale.
In the same vein, deep learning models are extremely powerful but opaque. Maximizing their potential requires massive training sets with broad, high-quality labeling and exemplars - far beyond what is humanly feasible manually. Weak supervision and programmatic labeling techniques are necessities to generate ample training data.
More broadly, the model-centric view sees data as largely static and detached from modeling. But in practice data and models inherently co-evolve and impact each other. Keeping data isolated inhibits this tight, iterative feedback loop.
Lastly, model-centric AI tends to emphasize extensive, custom model development and tuning targeting very specific datasets. However, this overfitting limits the reusability of models across data domains. With sufficient data quality and volume, well-architected models require far less customization to generalize successfully.
The model-centric status quo will become increasingly ineffective as data scale and velocity accelerate exponentially. Sole reliance on intense model customization and data wrangling is not sustainable. Data-centric AI offers an evolved paradigm better suited for building and deploying AI at scale.
Why Data-Centric AI Represents a Key Paradigm Shift
The shift from model-centric AI to data-centric AI represents a seismic change in approach. Data-centric AI views data not as a static input, but as a living, dynamic asset that requires constant improvement through engineering and stewardship. With this mindset, data workflows and models evolve together through integrated iteration.
Data-centric AI adopts scalable, programmatic data pipelines capable of handling tremendous scale where manual work falls short. This enables techniques like weak supervision to generate vast labeled datasets. The focus becomes configurable models paired with high-quality, well-understood data rather than extensive custom architectures.
Crucially, subject matter experts take on direct roles supervising data workflows, providing context, codifying domain knowledge, and supplying real-world nuance often absent from raw data. Their knowledge is tightly integrated into the machine learning process. Model behavior analysis surfaces data deficiencies to drive continuous enhancement in a closed-loop flywheel between models and data.
MLOps and DataOps enable governance, automation, experimentation, and reproducibility while tightly integrating dynamic data workflows and models throughout their lifecycle.
Upholding training data quality and fitness becomes the key strategic priority for driving model capabilities, rather than incremental architecture changes or algorithm tweaks.
Benefits of the Data-Centric Approach
Focusing on improving training data quality delivers major benefits across all stages of developing machine learning models. Clean, consistent, and representative training data leads to more accurate models, boosting accuracy.
Automating manual data tasks through code speeds up model building by up to 10x. Techniques like weak supervision cut labeling costs by up to 10x compared to manual labeling, which is key as training sets grow into millions of rows.
Maintaining high-quality, documented datasets allows quickly updating training data and rebuilding models when new information comes in or business needs change. This supports continuous progress and testing. Programmatic data processing removes bottlenecks from manual work, enabling reliable management of massive training sets and thousands of distributed labeling workers.
Directly involving experts multiplies specialized human knowledge throughout machine learning, as experts guide improvements to data workflows. Instrumented, transparent data processing also improves reproducibility, explainability, oversight and other governance compared to opaque manual methods.
Simply put, higher training data quality reduces model brittleness and potential biases that can make model behavior unpredictable or unreliable in the real world, lowering model risk. Continually improving data workflows prevents data from becoming a legacy liability as algorithms and uses change.
Together these benefits yield more capable, reliable and scalable real-world AI systems, where data is engineered to drive model success.
Data-Centric AI in Action
Data-centric techniques are demonstrating transformative impacts across diverse real-world AI applications. By transitioning from manual data tasks to programmatic data workflows, organizations are achieving many benefits.
For instance, a large financial institution, Banco Bilbao Vizcaya Argentaria, used Cleanlab’s data-centric AI to reduce label costs by over 98% and boost model accuracy by 28%. And The Stakeholder Company reduced time spent by 8X in their ML data workflow by using Cleanlab to order data by label quality.
Healthcare organizations can minimize the clinician time required for medical image labeling by amplifying limited samples. Government agencies can leverage data-centric pipelines to keep pace with exploding document volumes. Autonomous vehicle companies can efficiently simulate new scenarios and edge cases via synthetic data generation.
The overarching impact is transforming raw data into high-quality, understandable training data using software automation guided by human expertise. This amplifies model accuracy while reducing costs and manual effort, demonstrating the profound benefits of the data-centric approach for real-world AI.
Considerations for Implementation
Implementing data-centric AI can deliver immense value, but requires thoughtful strategy tailored to the organization.
Start with targeted pilots demonstrating impact before broader rollouts. Maintain focus on driving business results over chasing technical elegance. Prioritize high-impact use cases where improving data quality clearly translates into tangible bottom-line benefits. Quick wins build buy-in for further investment.
Institute data standards, quality SLAs, validation protocols, and governance on par with top-tier products. Treat training data as a carefully crafted asset, not an afterthought. Design flexible, modular pipelines to efficiently leverage domain experts’ scarce time and knowledge.
Adopt MLOps and DataOps to enable versioning, monitoring, automation and governance of data and model workflows, promoting organizational maturity. Get foundational programmatic workflows established before over-engineering each one.
Add monitoring, validation and integration touchpoints across pipelines to surface issues quickly. Fail fast, but safely. Continuously review samples and metrics to identify areas for data quality improvement. Analyze model behavior and feedback to prioritize enhancements.
With strategic implementation tailored to the organization, data-centric AI can deliver sustainable competitive advantage by transforming training data from a liability into a core asset differentiator.
The Future of Data-Centric AI
Data-centric AI represents a seismic shift in mindset where quality training data eclipses models as the primary strategic priority. Additional trends that will emerge as this philosophy propagates include the rise of the data engineer. More focus will be placed on rigorously engineering training data with “data engineer” becoming a discipline on par with data scientists. Crafting data will be valued.
Enter cleanlab.ai, an innovative startup that automates the entire data curation pipeline required for reliable AI.
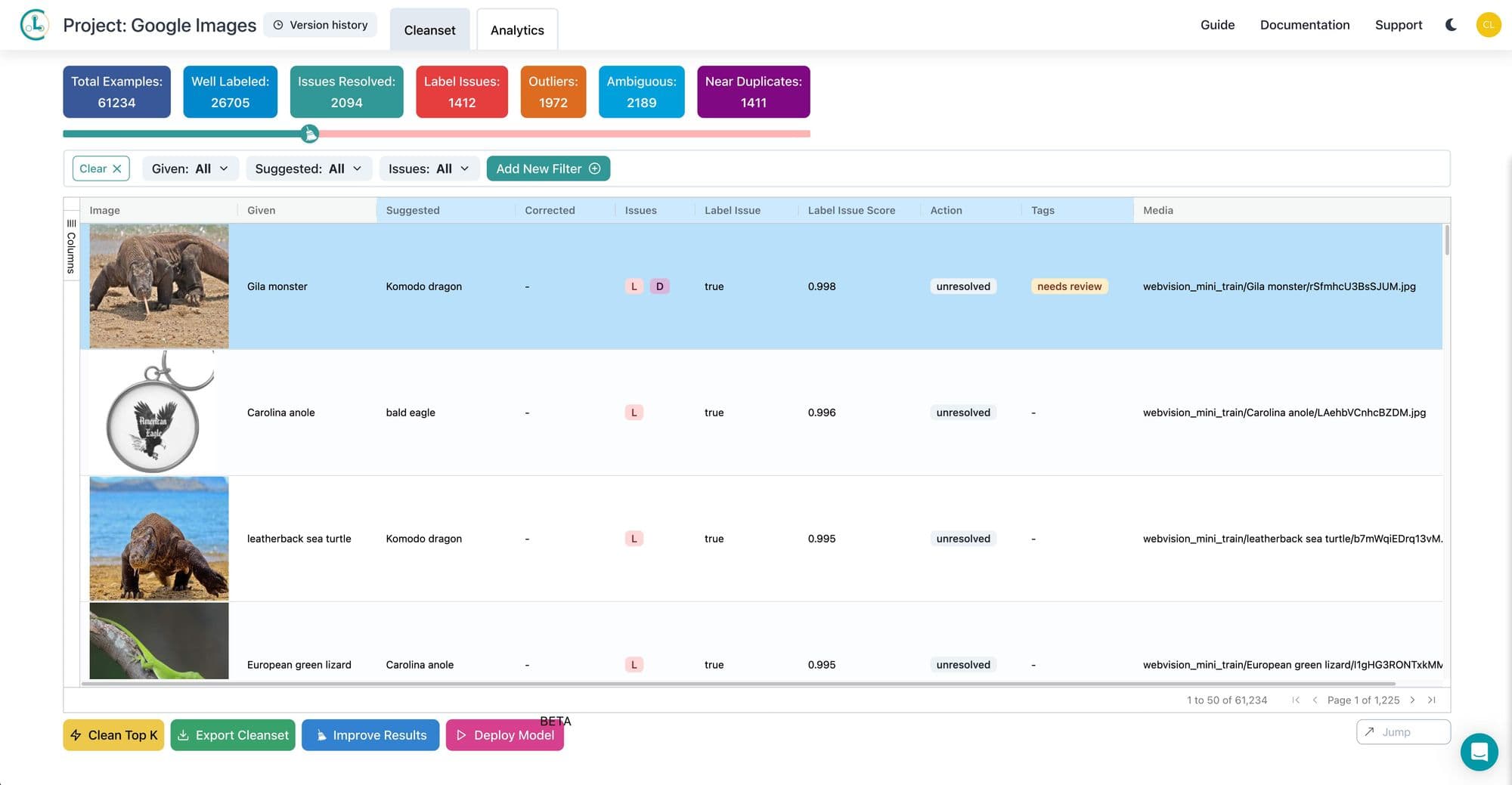
Cleanlab provides an end-to-end platform to clean dirty data and train robust models without coding. It automatically diagnoses label errors, invalid data, and other issues in datasets. The system suggests specific corrections down to the sample level. Users can then review and approve changes to create a high quality training set.
Cleanlab further includes integrated autoML capabilities to automatically train and tune models on the improved data with one click. The optimized models are deployed for batch or real-time inference via a web interface or API. Secure and scalable, Cleanlab handles varied data types across industries including tech consulting, financial services, manufacturing, and healthcare.
Pioneered at MIT by renowned experts, cleanlab represents the cutting edge of data-centric AI. Leading organizations including Google, Amazon, and BBVA already use Cleanlab to boost model accuracy by curating reliable training data. With Cleanlab, any business can turn unreliable data into trustworthy AI insights.
Utilizing DCAI with Cleanlab Studio
Data-centric AI is reshaping the way businesses approach analytics and modeling. If you’re ready to move past poor quality data, Cleanlab is here to help.
Cleanlab Studio is the fastest no-code Data-Centric AI platform to turn messy raw data into reliable AI/ML/Analytics. Try it to see why thousands of engineers, data scientists/analysts, and data annotation/management teams use Cleanlab software to algorithmically improve the quality of their image/text/tabular datasets.
- Get started with Cleanlab Studio for free!
- Join our Community Slack to discuss how you’re practicing Data-Centric AI and learn from others.
- Follow us on LinkedIn or Twitter to stay up-to-date on new techniques being invented in Data-Centric AI.