


Introduction
In machine learning and natural language processing, we train models to predict given labels, assuming that these labels are actually correct. However recent studies have found that even highly-curated ML benchmark datasets are full of label errors, and real-world datasets can be far lower quality. In light of these problems, the recent shift toward data-centric AI encourages data scientists to spend at least as much time improving their data as they do improving their models. No matter how much you tweak them, the quality of your models will ultimately depend on the quality of the data used to train and evaluate them.
The open-source cleanlab library provides a standard framework for implementing data-centric AI. cleanlab helps you quickly identify problems in messy real-world data, enabling more reliable machine learning and analytics. In this hands-on blog, we’ll use cleanlab to find label issues in the IMDb movie review text classification dataset. Commonly used to train/evaluate sentiment analysis models, this dataset contains 50,000 text reviews of films, each labeled with a binary sentiment polarity value indicating whether the review is overall positive (1) or negative (0).
Here’s a review that cleanlab found in the IMDB data, which has been incorrectly labeled as positive:
Like the gentle giants that make up the latter half of this film’s title, Michael Oblowitz’s latest production has grace, but it’s also slow and ponderous. The producer’s last outing, “Mosquitoman-3D” had the same problem. It’s hard to imagine a boring shark movie, but they somehow managed it. The only draw for Hammerhead: Shark Frenzy was it’s passable animatronix, which is always fun when dealing with wondrous worlds beneath the ocean’s surface. But even that was only passable. Poor focus in some scenes made the production seems amateurish. With Dolphins and Whales, the technology is all but wasted. Cloudy scenes and too many close-ups of the film’s giant subjects do nothing to take advantage of IMAX’s stunning 3D capabilities. There are far too few scenes of any depth or variety. Close-ups of these awesome creatures just look flat and there is often only one creature in the cameras field, so there is no contrast of depth. Michael Oblowitz is trying to follow in his father’s footsteps, but when you’ve got Shark-Week on cable, his introspective and dull treatment of his subjects is a constant disappointment.
The rest of this post demonstrates how to run cleanlab to find many more issues like this in the IMDB dataset. We also demonstrate how cleanlab can automatically improve your data to give you better ML performance without you having to change your model at all. You can easily use the same cleanlab workflow demonstrated here to find issues in your own dataset. You can run this workflow yourself in under 5 minutes:

Overview of steps to find label issues and improve models
Depicted below are the high-level steps involved in finding label issues in text classification data with cleanlab.
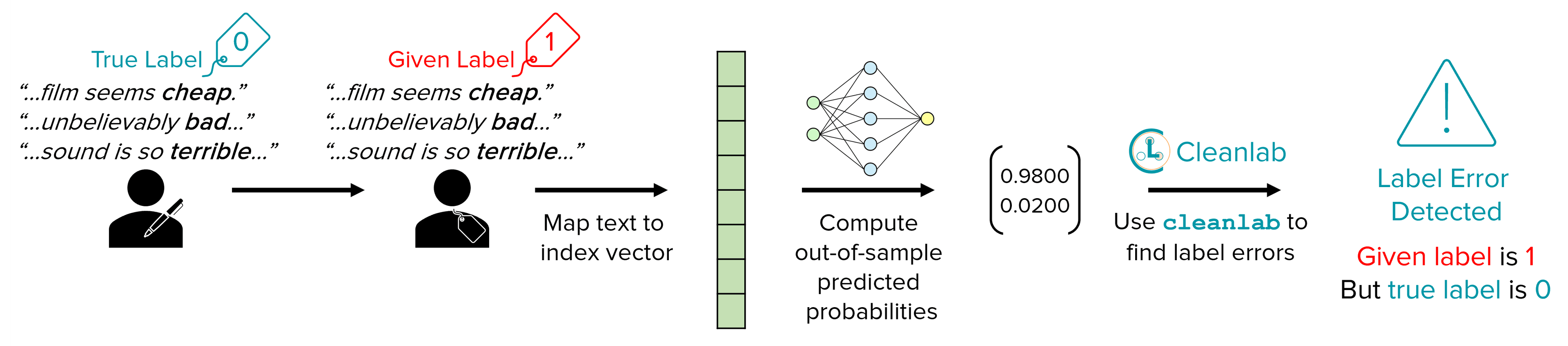
This blog will walk through the following workflow:
-
Construct a TensorFlow/Keras neural net and make it scikit-learn compatible using cleanlab’s
KerasWrapperSequential. -
Wrap the neural network with cleanlab’s
CleanLearningand use it to automatically compute out-of-sample predicted probabilities and identify potential label errors using thefind_label_issuesmethod. -
Train a more robust version of the same neural net after dropping the identified labeled errors using the same
CleanLearningobject.
The remainder of this blog lists the step-by-step code needed to implement this workflow.
Show me the code
Prepare the dataset
The IMDb text dataset is readily provided in TensorFlow’s Datasets.
Let’s print the first example in the train set.
Reassuringly, at least this example seems properly labeled (recall 0 corresponds to a review labeled as negative).
The data is stored as two numpy arrays for each the train and test set:
-
raw_train_textsandraw_test_textsfor the movie reviews in text format, -
train_labelsandtest_labelsfor the labels.
To run this workflow on your own dataset, you can simply replace the text and labels above with your own dataset, and continue with the rest of the steps.
Your classes (and entries of train_labels / test_labels) should be represented as integer indices 0, 1, ..., num_classes - 1.
Define a classification model
Here, we build a simple neural network for text classification via the TensorFlow and Keras deep learning frameworks. We will also wrap it with cleanlab’s KerasWrapperSequential to make it compatible with sklearn (and hence CleanLearning).
Note: you can wrap any existing Keras model this way, by just replacing keras.Sequential with KerasWrapperSequential in your code. Once adapted in this manner, the neural net can be interacted with all your favorite scikit-learn model methods such as: fit() and predict().
Now you can train or use the network with just a single line of code!
This network is similar to the fastText model, which is suprisingly effective for many text classification problems despite its simplicity.
The inputs to this network will be the elements of train_texts, and its outputs will correspond to the probability that the given movie review should be labeled as class 0 or 1 (i.e. whether it is overall negative or positive).
Use cleanlab to find potential label errors
Most real-world dataset contain some label errors, here we can easily define cleanlab’s CleanLearning object with the neural network model above and use its find_label_issues method to identify potential label errors.
CleanLearning provides a wrapper class that can easily be applied to any scikit-learn compatible model, which can be used to find potential label issues and train a more robust model if the original data contains noisy labels.
The find_label_issues method above will perform cross validation to compute out-of-sample predicted probabilites for each example, which is used to identify label issues.
This method will return a label quality score for each example (scores between 0 and 1, where lower scores indicate examples more likely to be mislabeled), and also a boolean that specifies whether or not each example is identified to have a label issue (indicating it is likely mislabeled)
We can get the subset of examples flagged with label issues, and also sort by label quality score to find the indices of the 10 most likely mislabeled examples in our dataset.
Let’s review some of the most likely label errors:
We can now inspect some of the top-ranked label issues identified by cleanlab. Below we highlight 3 reviews that are each labeled as positive (1), but should instead be labeled as negative (0).
Noteworthy snippets extracted from the first review:
- “…incredibly awful score…”
- “…worst Foley work ever done.”
- “…script is incomprehensible…”
- “…editing is just bizarre.”
- “…atrocious pan and scan…”
- “…incoherent mess…”
- “…amateur directing there.”
Noteworthy snippets extracted from the second review:
- “…film seems cheap.”
- “…unbelievably bad…”
- “…cinematography is badly lit…”
- “…everything looking grainy and ugly.”
- “…sound is so terrible…”
Noteworthy snippets extracted from the third review:
- “…hard to imagine a boring shark movie…”
- “Poor focus in some scenes made the production seems amateurish.”
- “…do nothing to take advantage of…”
- “…far too few scenes of any depth or variety.”
- “…just look flat…no contrast of depth…”
- “…introspective and dull…constant disappointment.”
With find_label_issues, cleanlab has shortlisted the most likely label errors to speed up your data cleaning process.
You should carefully inspect as many of these examples as you can for potential problems.
Train a more robust model from noisy labels
Manually inspecting and fixing the identified label issues may be time-consuming, but cleanlab can filter these noisy examples out of the dataset and train a model on the remaining clean data for you automatically.
First we’d like to establish a baseline by training and evaluating our original neural network model.
Let’s now train and evaluate our original neural network model.
Now that we have a baseline, let’s check if using CleanLearning improves our test accuracy.
CleanLearning provides a wrapper that can be applied to any scikit-learn compatible model. The resulting model object can be used in the same manner, but it will now train more robustly if the data has noisy labels.
We can use the same CleanLearning object defined above, and pass the label issues we already computed into .fit() via the label_issues argument. This accelerates things; if we did not provide the label issues, then they would be recomputed via cross-validation. After that CleanLearning simply deletes the examples with label issues and retrains your model on the remaining data.
We can see that the test set accuracy slightly improved as a result of the data cleaning. Note that this will not always be the case, especially if we are evaluating on test data that are themselves noisy. The best practice is to run cleanlab to identify potential label issues and then manually review them, before blindly trusting any accuracy metrics. In particular, the most effort should be made to ensure high-quality test data, which is supposed to reflect the expected performance of our model during deployment.
Conclusion
With one line of code, cleanlab automatically shortlists the most likely label errors to speed up your data cleaning process. Subsequently, you can carefully inspect the examples in this shortlist for potential problems. You can see that even widely-studied datasets like IMDB-reviews contain problematic labels. Never blindly trust your data! You should always check it for potential issues, many of which can be automatically flagged with cleanlab.
A simple way to deal with such issues is to remove examples flagged as potentially problematic from our training data.
This can be done automatically via cleanlab’s CleanLearning class.
In some cases, this simple procedure can lead to improved ML performance without you having to change your model at all!
In other cases, you’ll need to manually handle the issues cleanlab has identified.
For example, it may be better to manually fix some examples rather than omitting them entirely from the data.
Be particularly wary about label errors lurking in your test data, as test sets guide many important decisions made in a typical ML application.
While this post studied movie-review sentiment classification with Tensorflow neural networks, cleanlab can be easily used for any dataset (image, text, tabular, etc.) and with any classification model.
The cleanlab package is undergoing active development, and we’re always interested in more open-source contributors. Come help build the future of Data-Centric AI!
Additional References
-
Example code: Using Cleanlab, HuggingFace, and Keras to find label issues in IMDB text dataset
-
Example code: Using Cleanlab and FastText to find label issues in Amazon Reviews text dataset
To stay up-to-date on the latest developments from the Cleanlab team:
- Watch and star our GitHub
- Join our Cleanlab Community Slack
- Follow us on LinkedIn and Twitter
Easy Mode
While cleanlab helps you automatically find data issues, an interface is needed to efficiently fix these issues your dataset. Cleanlab Studio finds and fixes errors automatically in a no-code platform (no ML expertise required). Export your corrected dataset in a single click to train better ML models on better data.
Beyond its no-code interface, Cleanlab Studio also offers a powerful Python API. Get started with a quick tutorial on text classification.
