

Cleanlab Studio can be used to improve e-commerce websites, product listings, and analytics. Finding and fixing errors in product descriptions/metadata can be entirely automated, and improves: customer experience, product discoverability, SEO, advertising, as well as analytics/decision-making.
Cleanlab Studio seamlessly handles data with image, text, and structured/tabular features (e.g. product price, size, etc) to auto-detect many common issues in product catalogs including:
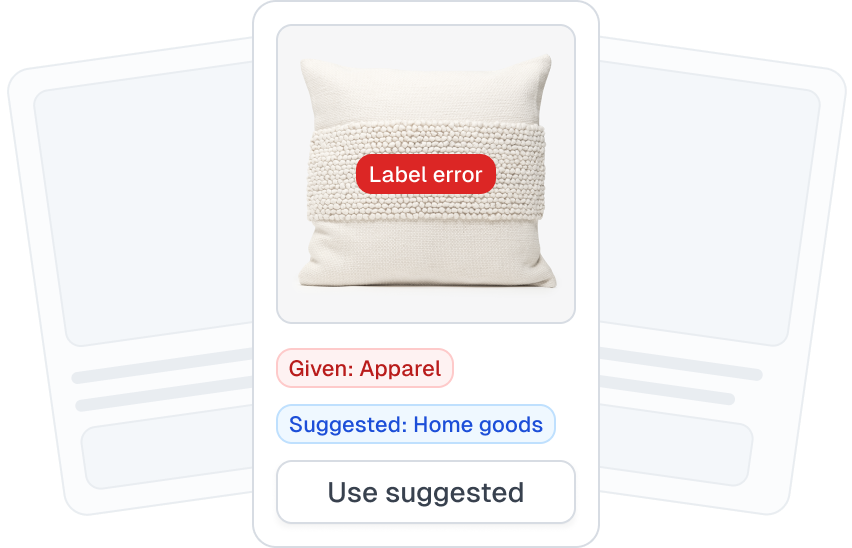
- Products (SKUs) that are miscategorized or have incorrect tags (tax-classifications, age-restrictions, …)
- Near-duplicate products (SKUs)
- Products with images that are low-quality or NSFW
- Products with low-quality text descriptions
- Products whose image does not match description
- Text in descriptions or review comments containing: toxic language, Personally Identifiable Information, or is not English
Learn how to: Improve your own catalog data
Read more: Enhancing Product Analytics and E-commerce with Cleanlab Studio
HOW IT WORKS

Catch Unsafe and Low-Quality Images in any Dataset
Read how Cleanlab Studio can be used as an automated solution to ensure high-quality image data, for both content moderation and boosting engagement. Curate any product/content catalog or photo gallery by automatically detecting images that are outliers, near duplicates, Not-Safe-For-Work, or low-quality (over/under-exposed, blurry, oddly-sized/distorted, low-information, or otherwise unaesthetic).
Catch Problematic Text in any Dataset
Read how Cleanlab Studio can be used for automated content moderation and curation of product descriptions and reviews. Cleanlab’s AI flags any text that is: poorly-written, non-English, indecipherable, or contains toxic language or Personally Identifiable Information.
Instantly Deploy Reliable AI
With a few clicks, Cleanlab Studio allows you to clean your dataset, train the best ML model for your data, and deploy it to serve predictions in your applications. This is the fastest path from raw data → value, for any supervised learning task (classification, tagging, regression, etc). You can alternatively improve any of your existing ML models via data curation with Cleanlab. Read how Cleanlab was used to improve an XGBoost model and OpenAI LLMs.
Resources and Tutorials
Videos on using Cleanlab Studio to find and fix incorrect labels for: product reviews (text data), product categories (image data), and tabular data (e.g. numeric/categorical product metadata like price, rating, brand, etc.).
CASE STUDY

Ping An Insurance is a Chinese holding conglomerate whose subsidiaries provide insurance, banking, asset management, financial, and healthcare services.
Ping An Insurance used Cleanlab in an e-commerce application to find 10% noise in their data labels, filter the detected bad data, and more robustly train their product classifier. Cleanlab was used to find label errors in image datasets. Multiple ResNet50 image classifiers were trained to compute the predicted product category probabilities for all the training samples in a cross-validation manner. Cleanlab was able to utilize the matrix of predicted probabilities to find noisy samples, ordered by likelihood of being an error.
10%
reduction in label noise
“[With Cleanlab], we removed the top 10% noisy samples from the training set.”
From A Multimodal Late Fusion Model for E-Commerce Product Classification, published in August 2020.

