


Common reasons companies struggle to quickly get good ML models deployed and generating business value include: messy data full of issues, a need to explore many ML models to train a good one, and infrastructural challenges serving predictions from the model. Now you can handle all of this with just a few clicks via Cleanlab Studio, which automatically: trains a baseline ML model, uses it to detect/correct issues in your data, identifies the best ML model for your data, trains this model on the auto-corrected dataset, and deploys it for serving predictions in your application. This used to require tons of code/effort, not any more!
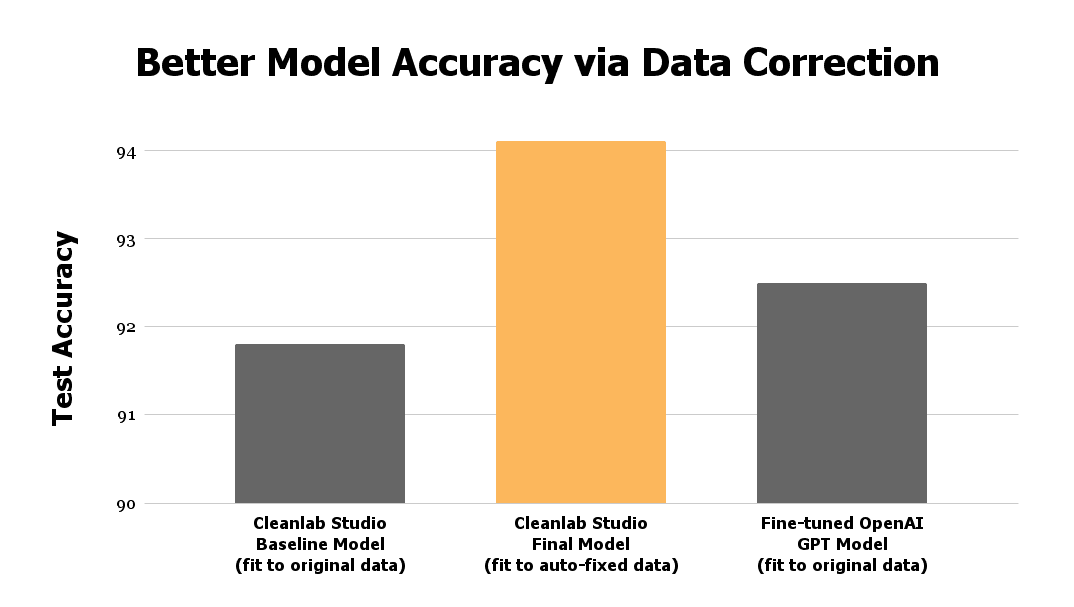
The figure above shows the accuracy achieved by 3 text classification models: a baseline model fit in Cleanlab Studio, a final version of this Cleanlab Studio model fit to an auto-corrected version of the same dataset, and an OpenAI Large Language Model fine-tuned on the original dataset for comparison. All data correction and model training/deployment above was done automatically in just a few clicks. Here the final model deployed using Cleanlab Studio (fit to auto-cleaned data) outperforms state-of-the-art OpenAI LLMs, emphasizing the importance of quality data for reliable ML deployments.
Cleanlab Studio allows you to rapidly turn messy real-world data into reliable ML model deployments, by automating all of the necessary steps. Details on how we make this possible are further below!
ML Model Deployment in Cleanlab Studio
Deployment of ML models is now generally available in Cleanlab Studio! Advanced features, including a one-line Python or HTTP API that easily integrates in your ML pipeline as well as new functionality for specific ML tasks faced by your business, are available with an Enterprise Subscription plan. The enterprise edition of Cleanlab Studio supports many more applications developed for specific businesses that are not generally available.
As part of the process used to automatically detect issues in any dataset, Cleanlab Studio applies a variety of AutoML systems and Foundation models which learn a lot about what doesn’t look right in the dataset when combined with novel data quality algorithms developed by our scientists. For text datasets, Cleanlab Studio applies optimal combinations of large pretrained LLMs and fine-tuned Transformer networks (T5, BERT variants, etc). For image datasets, Cleanlab Studio applies optimal combinations of large pretrained foundation models like CLIP/DINOv2 and fine-tuned computer vision networks like ResNets and Vision Transformers. For tabular (CSV/Excel/database) datasets, Cleanlab Studio applies optimal combinations of text models, neural architectures designed specifically for tabular data, and powerful tree ensembles like Gradient Boosting (LightGBM, XGBoost, CatBoost, etc) and Random Forests (plus Extremely Randomized Trees). Now you can deploy these same models to make predictions on additional test data!
In particular, you can quickly correct issues detected in your original dataset to improve its quality, and then Cleanlab Studio will re-train these same cutting-edge ML models on your improved data prior to deployment — ensuring the most reliable ML predictions for your downstream application. This entire process just requires a few clicks, and works seamlessly for text, image, and tabular datasets. Users who do not want to write any code can simply upload future test data via the Cleanlab Studio web interface to get back predictions from the deployed ML model. Users who want to integrate these ML predictions into an application can get inferences via an intuitive REST API.

Amazon Reviews Dataset
This article considers a text dataset of Amazon Reviews, which contains 5000 customer reviews for magazines labeled as either positive or negative.
You can download the train and test datasets yourself, and run them through Cleanlab Studio to see just how easy deploying reliable ML models can be!

Using Cleanlab Studio to Identify Potential Errors in the Dataset
We can upload this dataset to Cleanlab Studio and with a few button clicks, Cleanlab will automatically identify any potential issues in our data. For this Amazon dataset, Cleanlab Studio reveals many reviews that appear to be mislabeled, presumably because Amazon users often mis-click the star rating that is used to determine the positive/negative labels in this dataset. Cleanlab Studio ranks the data estimated to be erroneous in order of severity, allowing us to prioritize the data that would benefit most from correction or further review.
Here’s a review that Cleanlab Studio flagged as likely mislabeled. From reading the text, we can tell that this is actually a positive review, but it has for some reason been incorrectly labeled as negative.
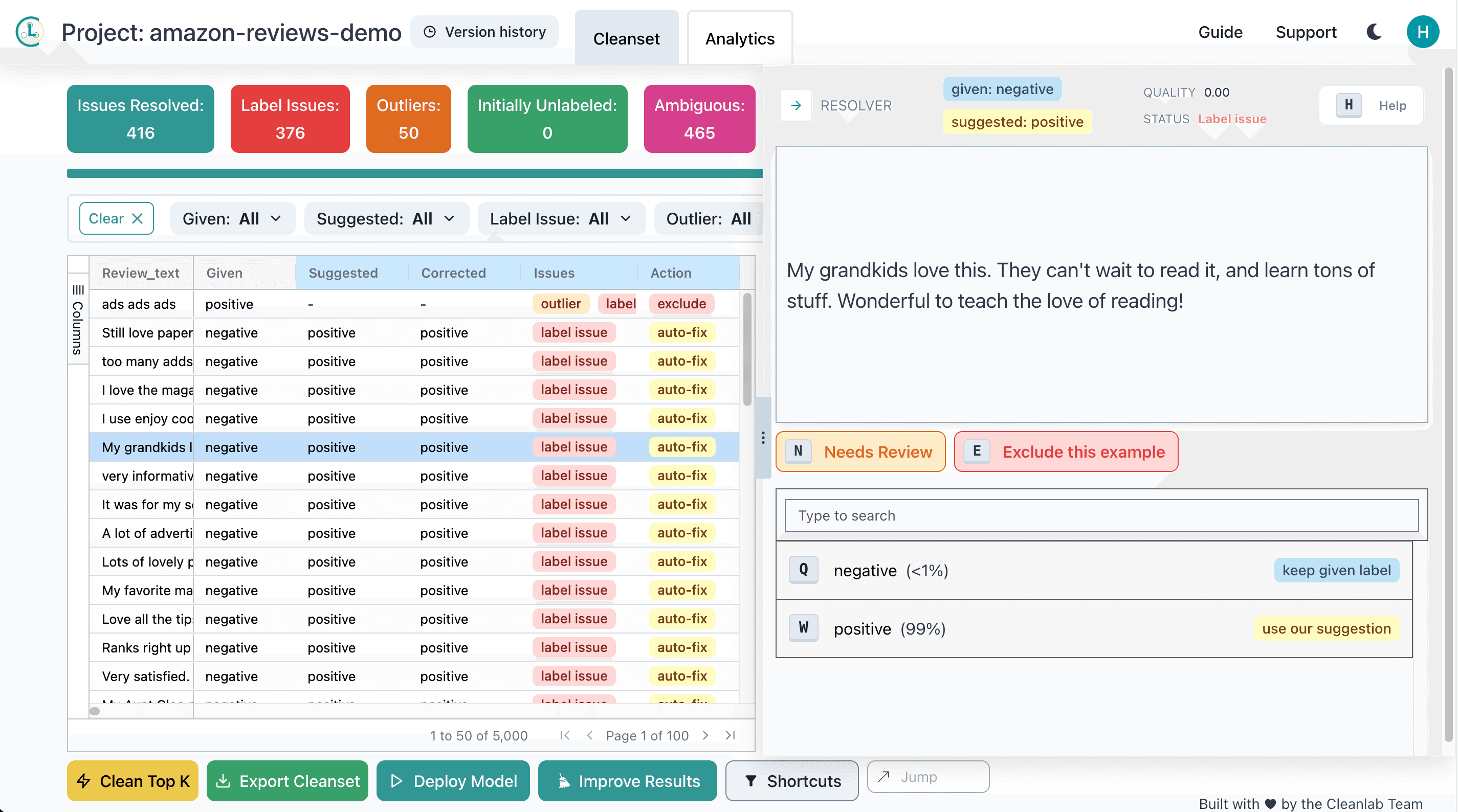
Cleanlab Studio automatically detected many examples that have been mislabeled like the one shown above. Now let’s correct these flagged errors. One way to ensure you get the highest quality data is to manually inspect all flagged examples in your dataset and decide how to best correct them. However inspecting hundreds of examples can be tedious! Here we use Cleanlab Studio’s Clean Top K feature, which allows us to automatically correct the top most severe issues detected in our dataset with an automatically suggested label (inferred to be more suitable for each example than its original label in the dataset).
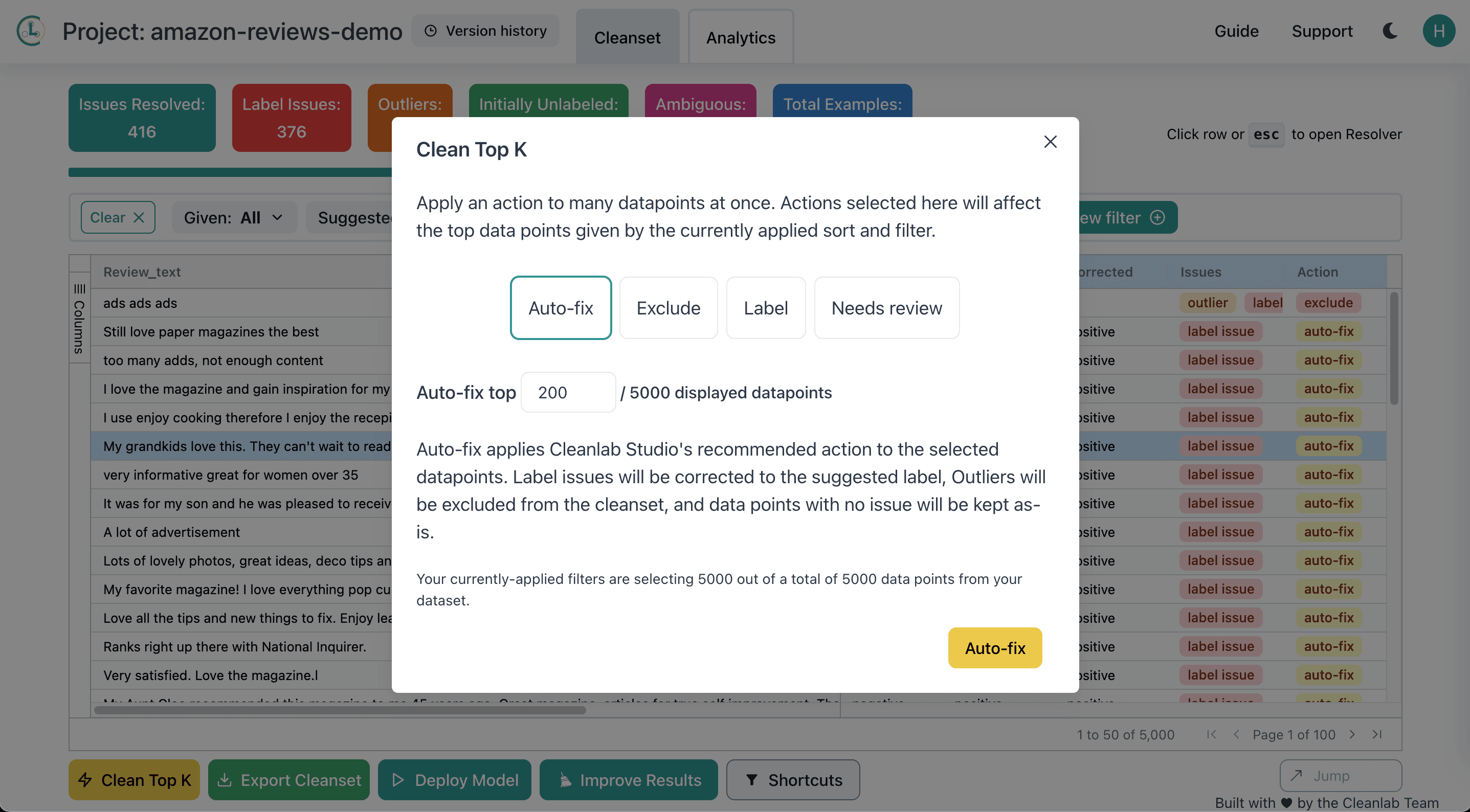
Using batch-actions to auto-fix our dataset, we have corrected hundreds of label issues with just a few clicks to produce a significantly higher-quality version of the original dataset.
Deploy Models for Prediction in Cleanlab Studio
After ensuring we have the best data possible, we can now train a new model on this new dataset to make predictions for any future data.
As seen above, deploying a model in Cleanlab Studio just takes one click, there’s no need to write any code as Cleanlab Studio automatically trains state-of-the-art models and deploys them for you. After model training completes, you can upload any new data, and Cleanlab Studio will return corresponding predictions from the model almost instantaneously. These predictions can also be downloaded as a CSV file by simply clicking Export.
This entire process which started from having messy data with various sorts of issues, and ended with a robust model trained on high-quality data only took a few clicks: upload the raw training data, automatically detect issues in the data via a baseline model, correct these issues, and then retrain + deploy a final model, which can produce predictions for new data with just a couple more clicks. Who says deploying Machine Learning / AI needs to be complicated?
Evaluating the Predictions
Now that we’ve seen how easily we can correct data and deploy new models in Cleanlab Studio, let’s check if the data improvement actually helps us get better models. In this study, we measure the accuracy of our deployed models on a held-out test set containing 1000 new magazine reviews. To reliably evaluate model predictions, the test set labels have been carefully examined to ensure they actually match each review’s sentiment with no errors. Always be cognizant that noisy test data may lead to unreliable conclusions — good thing Cleanlab Studio can easily assess your test data as well!
The original baseline model which Cleanlab Studio trained on the raw, noisy data achieved a test accuracy of 91.8%. After correcting the erroneous labels flagged by Cleanlab Studio, the final model that Cleanlab Studio trained on the improved data achieved a test accuracy of 94.1% (see bar chart at the top of this article). By improving the dataset algorithmically, we managed to obtain a 28% error reduction on the model predictions — all with just a few clicks!
To compare against the state-of-the-art for handling such text data, we fine-tuned an OpenAI babbage Large Language Model on the original data to predict the sentiment of the reviews. Fine-tuning LLMs allows them to produce far more accurate predictions for domain-specific datasets. For this reviews classification task, the fine-tuned OpenAI model only obtained a test accuracy of 92.5%. Thus on real-world data, you can get better ML performance with a few clicks in Cleanlab Studio (couple clicks to upload data, 1 click to train baseline model, 1 click to detect issues, 1 click to auto-fix the detected issues, 1 click to retrain and deploy final model) than with OpenAI LLMs — which require writing code and learning their APIs. Models deployed with Cleanlab Studio are not only more accurate/reliable, but also much smaller (and hence able to return predictions quickly and at low costs).
These results highlight that once you achieve good quality data, even smaller (easier to deploy) models can provide reliable predictions for your applications.
Automated Data-Centric AI tools such as Cleanlab Studio help us efficiently turn unreliable real-world data into reliable ML model deployments. Such tools are useful across many applications beyond this Amazon Reviews classification task, and they can handle arbitrary text datasets as well as data from tables/spreadsheets/databases and data containing images.
Resources
- Easily improve your data and ML models with Cleanlab Studio!
- To learn how to drastically reduce the time to model deployments + boost their accuracy at your company, simply reach out: sales@cleanlab.ai
- To deploy models for ML tasks not supported in the publicly-available version Cleanlab Studio, consider our Enterprise Subscription plan which supports a wide range of additional functionalities.
- Tutorial on how to programmatically deploy ML models via Cleanlab Studio’s Python API.