
This article highlights data-centric AI techniques using cleanlab to improve the accuracy of an XGBoost classifier (reducing prediction errors by 70% on the noisy dataset considered here!). These techniques optimize the dataset itself rather than altering the model’s architecture or hyperparameters. As a result, it is possible to achieve further improvements in accuracy by fine-tuning the model with the newly enhanced data. Enhancements to the dataset are model-agnostic and therefore are transferable to other modeling and analytical endeavors, as opposed to being specific to a particular type of model.

Previous research shows many popular datasets contain incorrect or mislabeled examples. Similar to other modalities, tabular data is also vulnerable to label noise. This data table is typically organized in a row, and column format, stored in a CSV file or SQL database, and can include numerical, boolean, and/or text values (such as sensor readings, bank loan details, car sales data, etc.). While errors in tabular data may not be as immediately apparent, it is crucial to address this issue in order to ensure the reliability and accuracy of machine learning models trained on this type of data.
Because data-centric techniques focus on improvements to the data, in this article, we will not change any code related to model architecture, hyperparameters, or training! We will see a reduction in error strictly come from increasing the quality of our data which leaves room for additional optimizations on the modeling side.
Take a Snapshot
At a high level we will:
- Establish a baseline accuracy of XGBoost model trained on the original data.
- Use cleanlab’s
find_label_issues()to highlight hundreds of mislabeled data points. - Remove the data with automatically-flagged label issues from the dataset, and then retrain the exact same XGBoost model. This simple step reduces the error in model predictions by 36%! The raw difference in accuracy values between the two XGBoost models is 8%.
- Introduce a no-code solution to efficiently fix the label errors in the dataset which reduces the error in model predictions by 70% from the baseline, identical XGBoost model!
To run the code demonstrated in this article, here’s the full notebook.
Examine the Data
You can download the dataset here.
Let’s take a look at our student grades tabular dataset. The data includes three exam scores (numerical features), a written note (categorical feature with missing values), and a (noisy) letter grade (categorical label). Our aim is to train a model to classify the grade for each student based on the other features, but 20% of the grade labels in this dataset are actually incorrect.
We have access to the true letter grade each student should’ve received, which we use for evaluating both the underlying accuracy of model predictions and how well cleanlab detects which data are mislabeled. These true grades are only reserved for model evaluation and are manually validated, gold-standard labels. They are not present in any of the training procedures. We utilize a 75/25 split for our train/test data.
In your noisily-labeled datasets, there will typically be no such ground truth, and therefore addressing label issues is even more important to facilitate proper model evaluation.
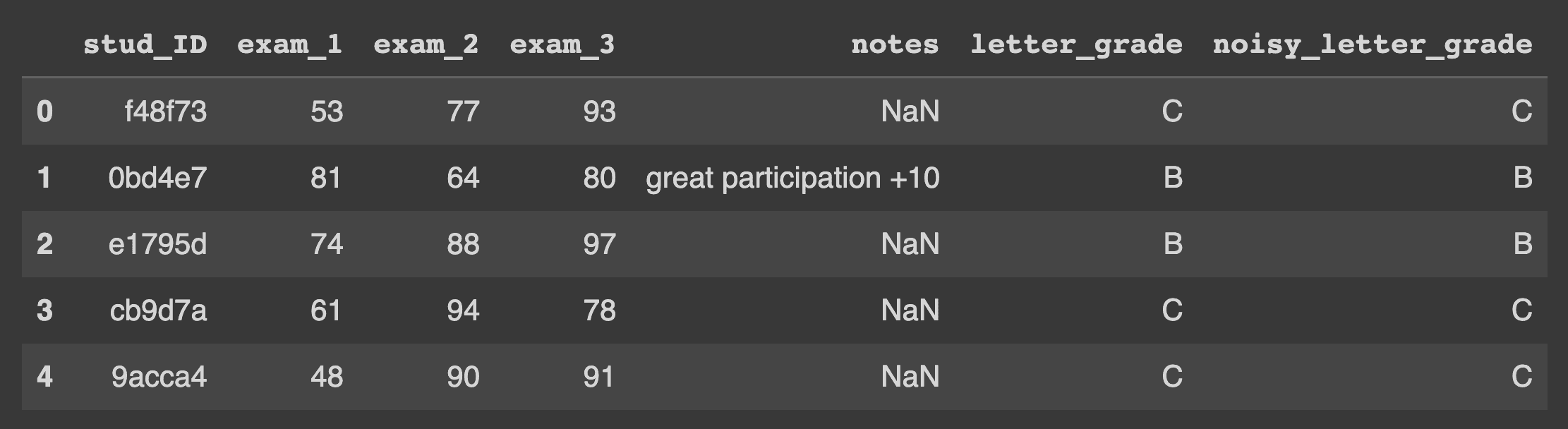
Train and Evaluate XGBoost Classifier
Now that we’ve seen what can be achieved with cleanlab, let’s take a look at how we get there.
For our model of choice, we will use XGBoost, an implementation of gradient-boosting decision trees (GBDT), which are commonly used with tabular data. If our tabular data consisted solely of numerical and boolean values, we could potentially utilize a simpler model such as a nearest-neighbor or logistic regression. However, our data includes a notes column, which we will treat as a categorical feature. Fortunately, XGBoost (>v1.6) is able to handle mixed data types (numerical and categorical) by setting the enable_categorical parameter to true, thereby simplifying the modeling process.
Using the default hyperparameters, our baseline XGBoost model demonstrates an accuracy of 79.2% when trained on the noisy labels and predicting the test set. It appears that the presence of 20% label noise is significantly disrupting the model’s ability to accurately predict the labels on such a trivial task.
Find Label Issues
In order to use cleanlab, we need to obtain out-of-sample predicted probabilities for all of our training data in order to provide the find_label_issues() method with the necessary input. Getting the predicted probabilities can be achieved through the use of our XGBClassifier model with cross-validation, which can be implemented easily using the cross_val_predict function from scikit-learn.
In just a few lines of code, we get a list of possible label issues! A few of the top results are shown below.
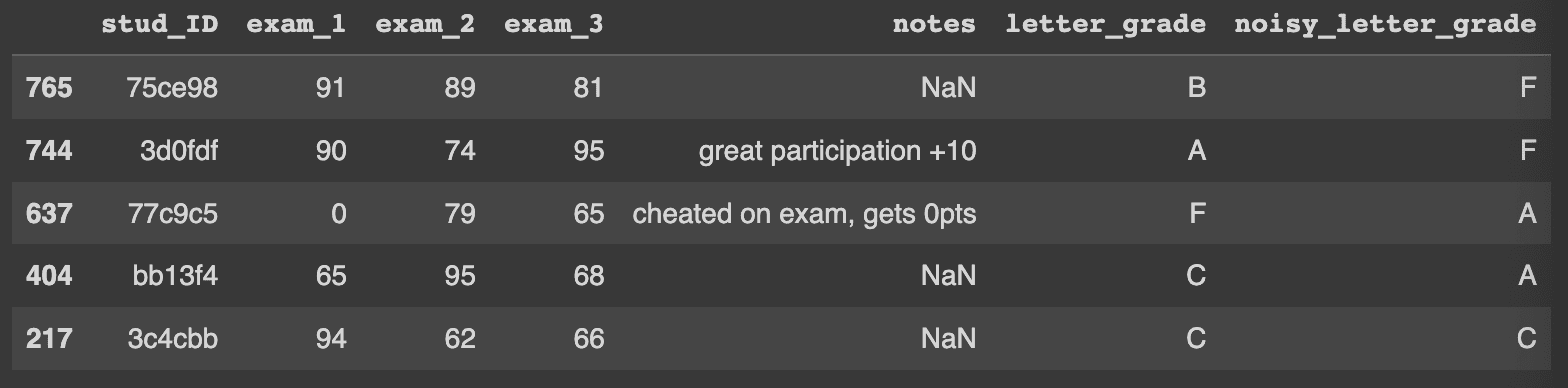
Let’s take a look at a few of the label issues automatically identified in our dataset. Take a look at row 1, where the student got grades of 91, 89, and 81, which should result in a ‘B’ yet was accidentally labeled as an ‘F’. In row 2, the student had great participation resulting in an addition of 10 points to the overall average, receiving exam grades of 90, 74, and 95 (averages to 86.3, overall 96.3 with the bonus), which should result in a ‘A’ yet was accidentally labeled as an ‘F’.
Note: find_label_issues is able to determine that the given label is incorrect, without ever seeing the ground truth label letter_grade.
How’d We Do?
Let’s go a step further and see how cleanlab did at automatically identifying which data points are mislabeled. If we take the intersection of the label errors identified by cleanlab and the true label errors, we see that cleanlab was able to identify 83% of the label errors correctly (based on predictions from a model that is only 79% accurate).
Retraining for a More Robust Model
Now that we have the indices of potential label errors let’s remove them from our data, retrain our model, and see what performance improvement we can gain.
Keep in mind our baseline model from above, trained on the original data using the noisy_letter_grade as the prediction label, achieved an accuracy of 79%.
Let’s use a very simple method to handle these label errors and just drop them entirely from the data and retrain our exact same XGBClassifier.
After removing the suspected label issues, our model’s new accuracy is now 87%, which means we reduced the error-rate of the model by 36%.
Note: throughout this entire process, we never changed any code related to model architecture/hyperparameters, training, or data preprocessing! This improvement is strictly coming from increasing the quality of our data which leaves room for additional optimizations on the modeling side.
Fixing the Label Errors
Instead of just dropping the potential label issues, the smarter (yet more complex) way to increase our data quality would be to correct the label issues by hand. This simultaneously removes a noisy data point and adds an accurate one, but making such corrections manually is cumbersome.
The Cleanlab Studio platform provides a user-friendly interface to make these changes without writing a single line of code. Simply upload your dataset and Cleanlab Studio computes everything we just did for you, so you can spend more time fixing the issues instead of just finding them.
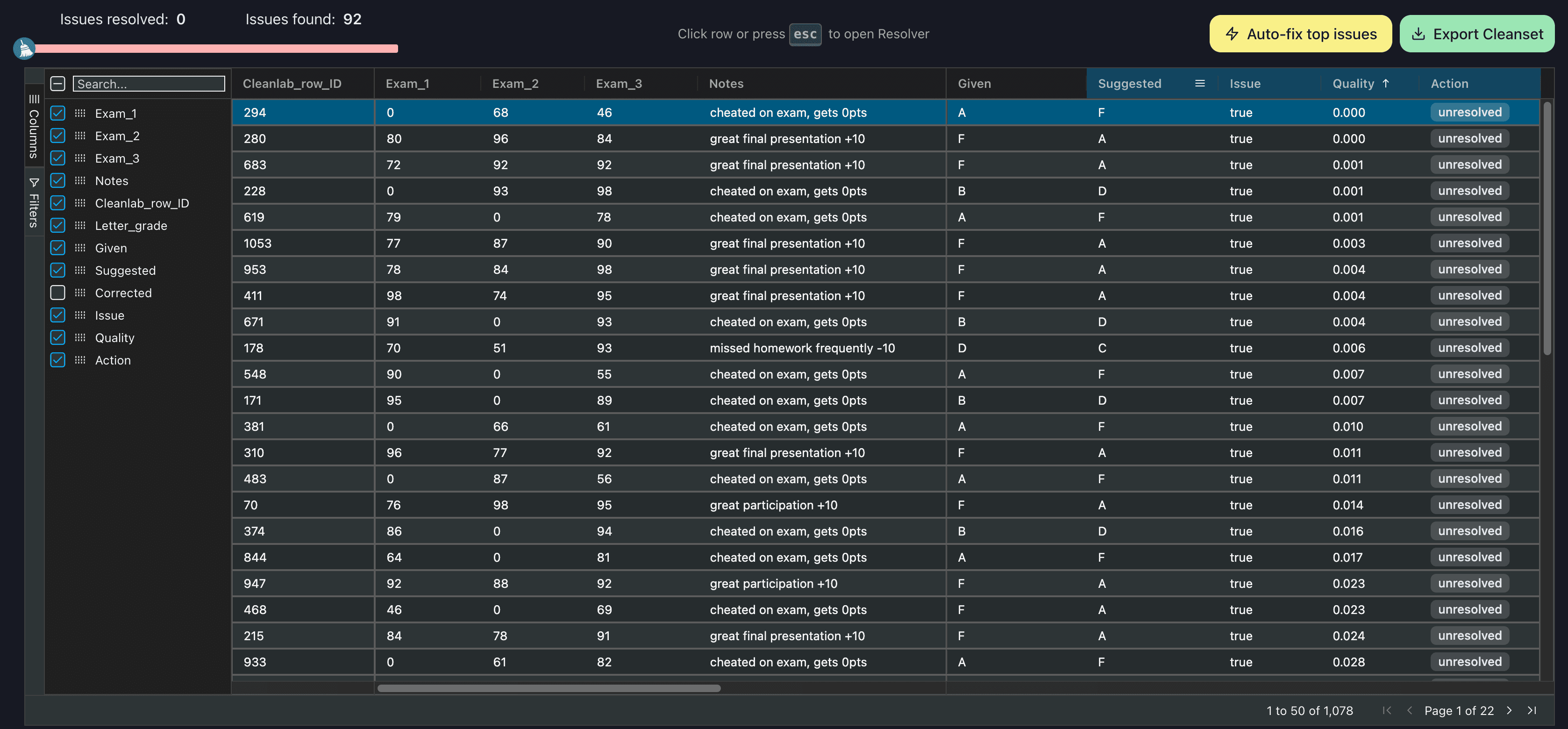
Cleanlab Studio automatically flags datapoints that it thinks are possible issues and provides suggested label corrections for them. Users have the flexibility to correct issues by hand or use the auto-fix feature which replaces all of the flagged errors with the suggested label.
Here, we use the auto-fix feature on this dataset and replace the Cleanlab Studio-detected label issues with the automatically-suggested label. From data upload to data export, the whole process took only 5 minutes.
You can download the corrected data exported from Cleanlab Studio here.
We then re-train the exact same XGBoost model on the dataset improved with Cleanlab Studio. After evaluation on the unmodified testing data, the resulting predictions achieve 94% accuracy, which is a 70% reduction in error from our original model and a 52% reduction in error from our model trained on the dataset auto-filtered using the find_label_issues method.
Conclusion
Cleanlab is an incredibly powerful and efficient tool for identifying and addressing label errors in your data that can be used to improve any ML model (not just XGBoost) for most types of data (not just tabular, but also images, text, audio, etc). By implementing just a few lines of open-source code, cleanlab can automatically detect and help you prioritize many potential issues within your data. With this insight, you’ll be able to improve the quality of your data and ultimately achieve better model performance.
For the student grades dataset, we found that simply dropping identified label errors and retraining the model resulted in a 36% reduction in prediction error on our classification problem (with accuracy improving from 79% to 87%).
Going one step further, we used Cleanlab Studio to automatically fix the incorrect labels,resulting in a 70% reduction in prediction error (with accuracy improving from 79% to 94%).
By using open-source libraries for data-centric AI like cleanlab to ensure the integrity of your data, you can mitigate costly labeling errors and boost the performance of your models.
To stay up-to-date on the latest cleanlab developments and learn more about how this tool can benefit your work, be sure to check out the resources listed below.
##0 Next Steps
-
Try Cleanlab Studio today, or get started with our quick Python API tutorial for tabular data.
-
Try cleanlab open-source and consider contributing code to support the future of open-source Data-Centric AI. Here’s a quick cleanlab tutorial for tabular data.
-
See how cleanlab also helps improve training data in Kaggle competitions.
-
Keep up with the latest in Data-Centric AI via our Cleanlab Community Slack, LinkedIn, and Twitter.