Model training and deployment only requires a few clicks (no technical knowledge necessary). Cleanlab models produced in this seamless manner are more accurate than fine-tuned OpenAI LLMs (the state-of-the-art for text prediction) when applied to predict legal outcomes from court case descriptions.
Details in article: Improving Legal Judgement Prediction with Cleanlab Studio
Read more about Leveraging AI for Enhanced E-Discovery

HOW IT WORKS
Auto-detect Issues
Autonomously detect miscategorized legal documents to enhance the accuracy of your relevance determination. Learn more.
Minimize Human Review
Efficiently prioritize which content should receive a second (or even third) human review, when necessary to ensure reliable annotations. Learn more.
Built With AI
Provides unbiased software evaluation of diverse forms of evidence via state-of-the-art AI algorithms.
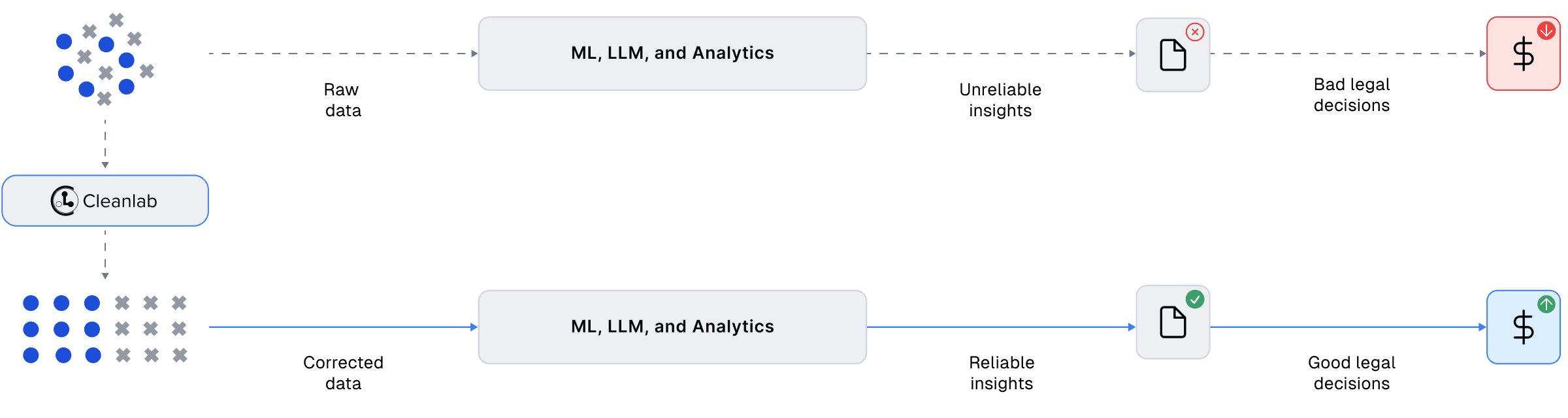
Train and Produce Reliable Models
Train and deploy state-of-the-art text/document classification models in one click (including Foundation models like GPT Transformers).
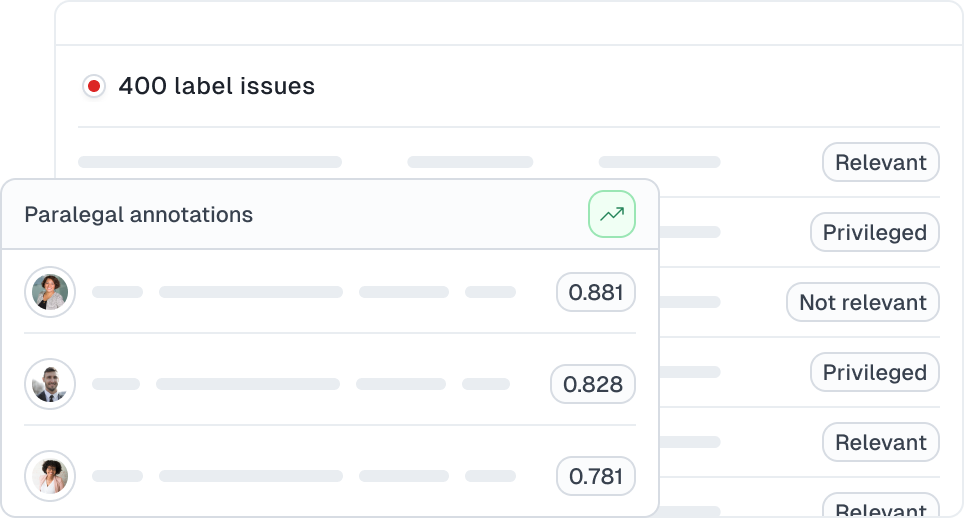
Assessing Multiple Data Annotators
Determine which of your data annotators (i.e. paralegals) is performing best/worst overall. Learn more.
Resources and Tutorials
Videos on using Cleanlab Studio to find and fix incorrect labels for: text data, tabular data, and image data
CASE STUDY
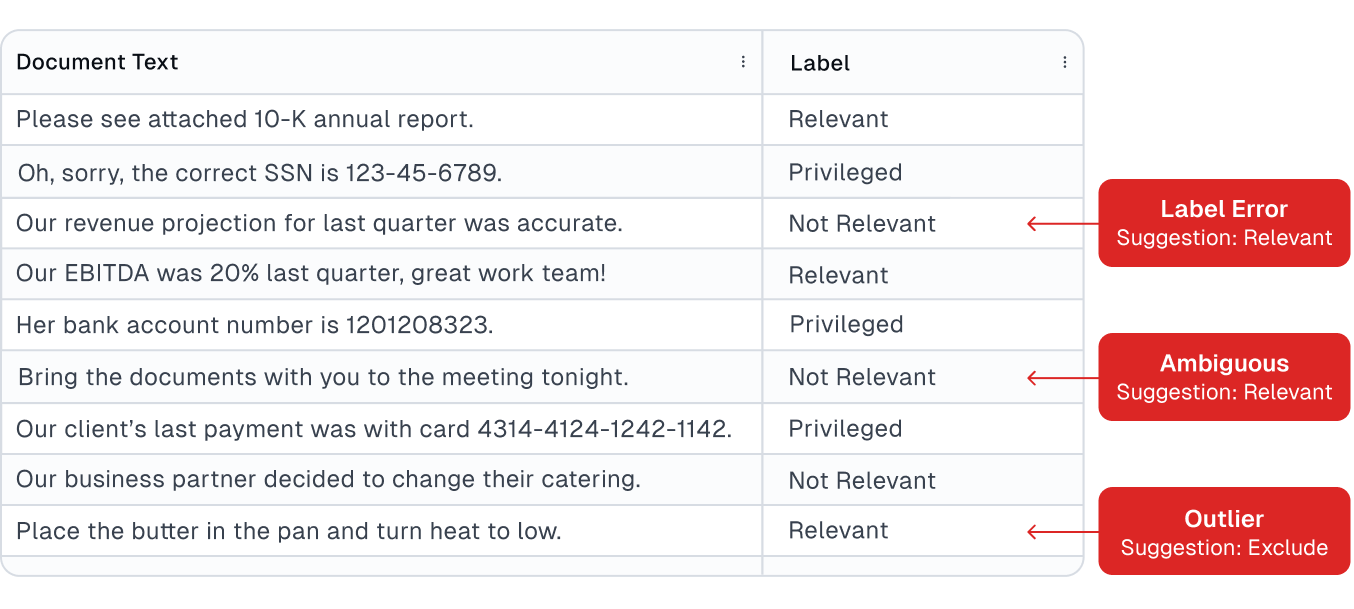
Cleanlab Studio was used by a customer to identify errors in relevance annotations for documents during the e-discovery phase of a legal proceeding. Cleanlab automatically identified a vast number of important documents that paralegals accidentally failed to annotate as relevant.
Relevance-prediction models trained inside Cleanlab Studio were 15% more accurate than the customer’s own models. Similar benefits were observed for dealing with annotations for privileged content.
Audit with error-estimation software based on published research with theoretical guarantees was encouraged for compliance reasons and objectivity.
15%
improvement in ML model accuracy
10x
reduction in time spent on litigation discovery
“I rely on you guys to be my level of scrutiny. Using Cleanlab in litigation discovery, we can accomplish with 5 lawyers what previously required 50 lawyers.”
who now uses Cleanlab in every case.

