


Many of us obtain multiple annotations per datapoint to ensure higher quality labels, yet there doesn’t seem to be a standard open-source python package for dealing with multi-annotator classification data. After months of work, we’re excited to share a new open-source module – cleanlab.multiannotator – for measuring the quality of such multi-annotator data via novel CROWDLAB algorithms we just published.
CROWDLAB (Classifier
Refinement Of croWDsourced LABels) is a straightforward and efficient method that can utilize any classifier to estimate:
- A consensus label for each example that aggregates the individual annotations (more accurately than majority-vote or algorithms used in crowdsourcing like Dawid-Skene).
- A quality score for each consensus label which measures our confidence that this label is correct by considering the number of provided annotations and their agreement, prediction-confidence from a trained classifier, and trustworthiness of each annotator vs. the classifier.
- A quality score for each annotator which estimates the overall correctness of their labels.
Surprise! All 3 of these tasks can be estimated in one line of code with cleanlab.multiannotator (shown further below). On real-world data, this one line of code produces significantly better estimates for all 3 tasks than existing solutions (see figure below). This post describes how the underlying algorithms work, and why they are so effective.
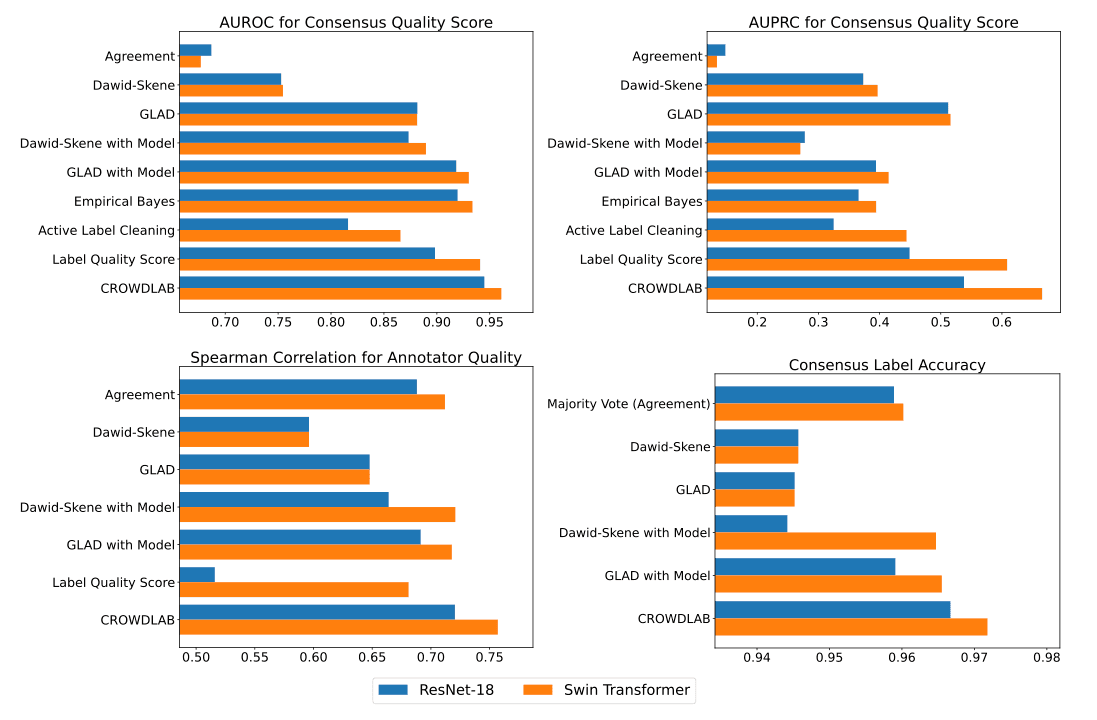
The figure above evaluates estimates for each of the 3 tasks on a version of CIFAR-10 in which each image is labeled by multiple human annotators. We repeated the evaluation with two different classifier models. Consensus labels (i.e. truth inference) estimated by different algorithms are evaluated via their accuracy against ground-truth labels, consensus quality scores via their AUROC/AUPRC (i.e. precision/recall) for determining which consensus labels are incorrect, and annotator quality scores via their Spearman correlation with each annotator’s overall accuracy against ground truth labels (i.e. how well these scores rank annotators from best-to-worst). On real data, CROWDLAB provides significantly better estimates for the 3 tasks than existing popular algorithms like majority-vote, GLAD, Dawid-Skene, as well as more sophisticated variants of these augmented with a classifier model and recently-published approaches like Active Label Cleaning. Label Quality Score here represents a direct multi-annotator adaption of older cleanlab methods, showing how the library has improved with the addition of CROWDLAB through cleanlab.multiannotator.
Developing accurate estimates involved substantial research detailed in our paper: CROWDLAB: Supervised learning to infer consensus labels and quality scores for data with multiple annotators. Our paper extensively benchmarks CROWDLAB against popular methods on real multi-annotator datasets, and contains more details about the above figure plus many others that show CROWDLAB estimates are also better than existing solutions for other datasets.
How do I use CROWDLAB?
Our 5min tutorial shows how a single line of code can produce CROWDLAB estimates for the 3 tasks based on two inputs:
- Dataset labels stored as matrix
multiannotator_labelswhose rows correspond to examples, columns to each annotator’s chosen labels (NArepresenting missing labels) - Predicted class probabilities
pred_probsfrom any trained classifier
This code returns estimates for the 3 tasks as well as other useful information shown below.
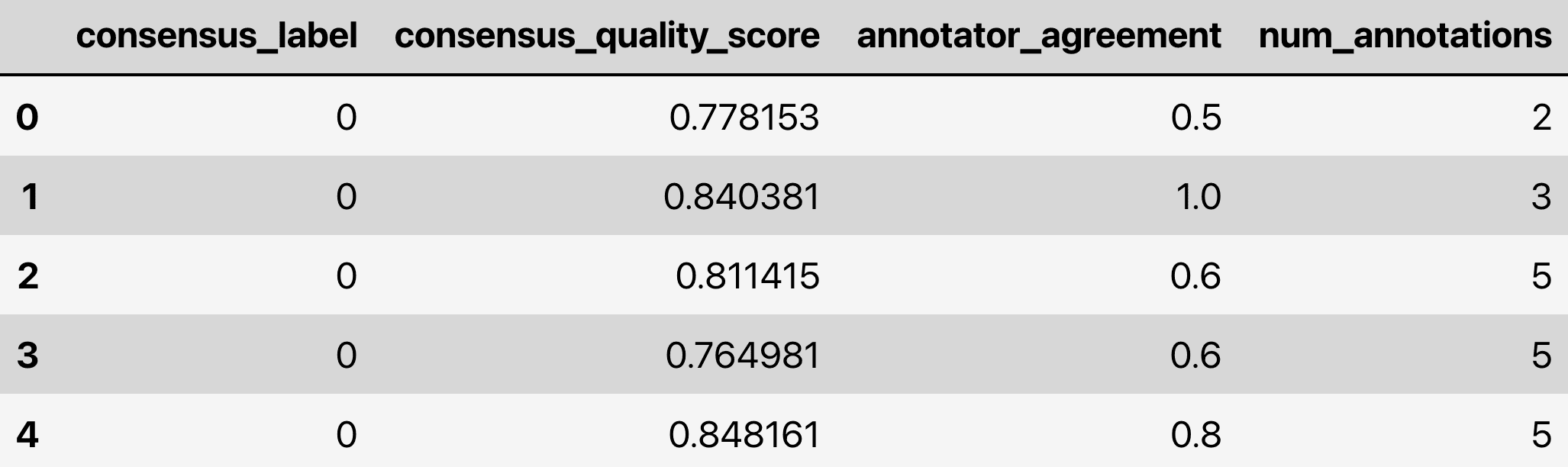
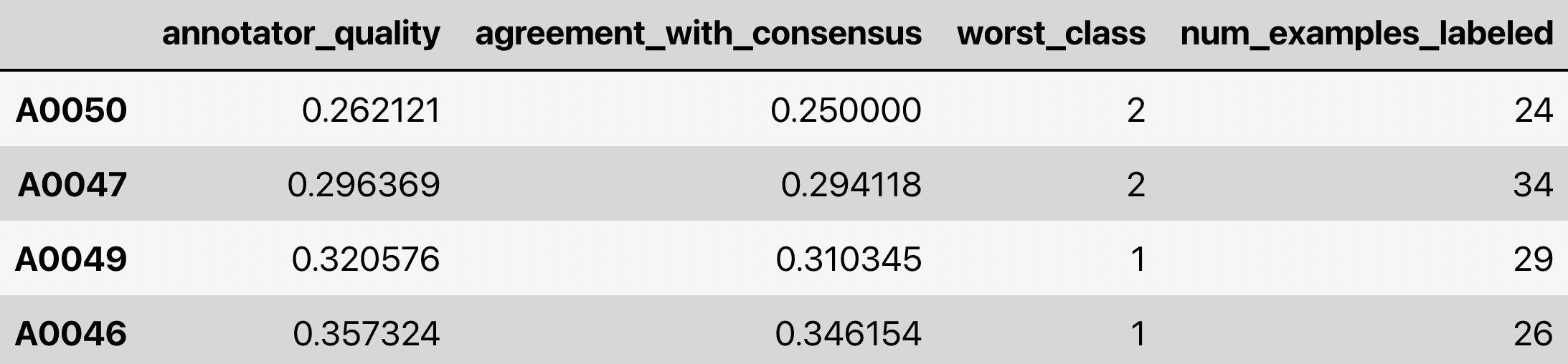
Such estimates can be produced for any classification dataset in which some examples are labeled by multiple annotators, but not every annotator labels every example (in practice, many examples may only be labeled by one annotator).
How does it work?
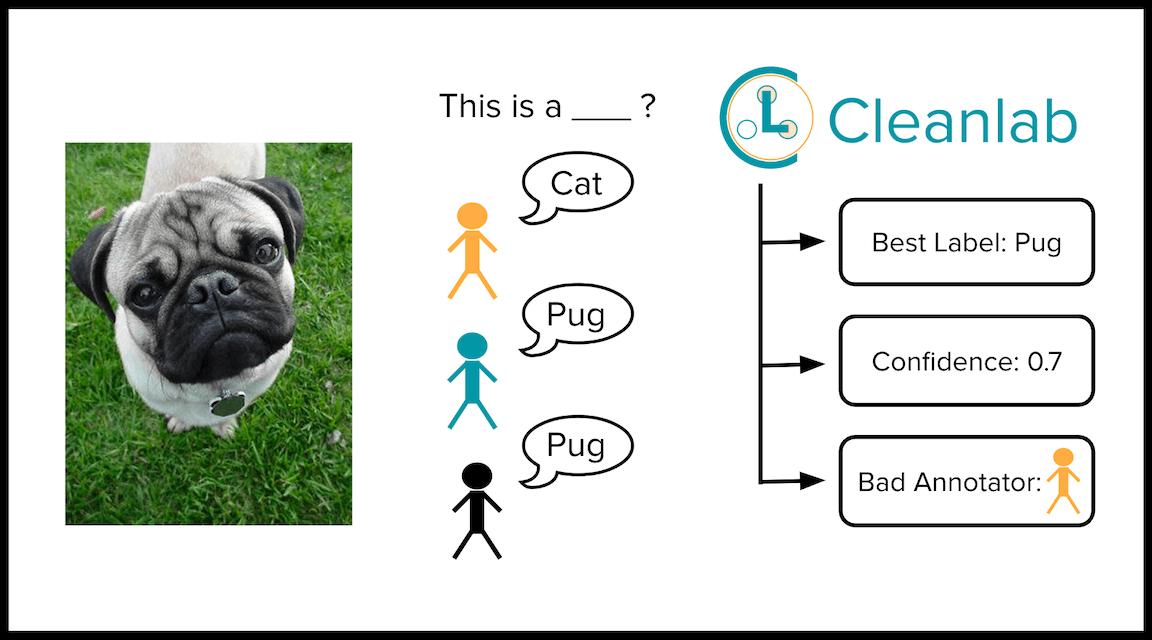
Some of the most accurate ML predictions are produced via weighted ensembling of the outputs from different individual predictors. Inspired by this, CROWDLAB takes predictions from any trained classifier model and forms a probabilistic ensemble prediction by considering the labels assigned by each annotator as if they were outputs from other predictors:
Here weights are assigned according to an estimate of how trustworthy the model is vs. each individual annotator, which allows CROWDLAB to still perform effectively even when the classifier is suboptimal or a few of the annotators often give incorrect labels.
Intuitively, the weighted ensemble prediction for a particular example becomes more heavily influenced by the annotators the more of them have labeled this example. The inter-annotator agreement should serve as a good proxy for consensus label quality when many annotators were involved, whereas this quantity is unreliable for examples labeled by few annotators, for which CROWDLAB relies more on the classifier (which can generalize to these examples if there were other examples with similar feature values in the dataset). CROWDLAB also accounts for the classifier’s prediction confidence, its accuracy against the annotators, and per-annotator deviations from the majority to even better assess which estimates are least reliable. After obtaining the ensemble prediction that represents our best calibrated estimate of the true label, CROWDLAB then applies cleanlab’s existing label quality score. We found just initially training the classifier using majority-vote labels works well, but you could train it however you like.
All the fun mathematical details can be found in our paper.
Why is it effective?
CROWDLAB can generalize across examples based on their feature values.
In commonly-encountered settings with few (or only one) labels for some examples, estimates based on crowdsourcing algorithms like majority-vote/GLAD/Dawid-Skene become unreliable because these methods infer complex generative models based solely on annotator statistics. CROWDLAB utilizes additional information provided by a classifier that may be able to generalize to this example (especially if other dataset examples with similar feature values have more trustworthy labels).
CROWDLAB properly accounts for the number of annotators and their agreement.
For examples that received a large number of annotations, CROWDLAB assigns less relative weight
to the classifier predictions and its consensus quality score converges toward the observed annotator
agreement. This quantity becomes more reliable when based on a large number of annotations, in which case relying on other sources of information becomes less vital. For examples where all annotations agree, an increase in the number of such annotations will typically correspond to an increased CROWDLAB consensus quality score. In contrast, other cleanlab methods like the label quality score only consider a single set of predictions and thus do not exhibit this desirable property.
CROWDLAB is data efficient (estimates few per-annotator quantities).
Crowdsourcing aggregation algorithms like Dawid-Skene estimate confusion matrices per annotator, which may be statistically challenging when some annotators provide few labels. CROWDLAB merely infers one scalar trustworthiness weight for each annotator, which can be better estimated from a limited number of observations.
CROWDLAB is easy to understand, efficient, and reproducible.
Popular crowd-sourcing methods like Dawid-Skene or GLAD are iterative algorithms, with high
computational costs when their convergence is slow, whereas CROWDLAB does not require iterative updates and is fully deterministic (for a given classifier).
We believe CROWDLAB to be the most straightforward method that properly accounts for:
- the features from which annotations derive (utilized by our trained classifier)
- the number of annotators that review an example
- how much these annotators agree
- how good each annotator is
- how good our trained classifier is
- how confident our trained classifier is
Resources to learn more
- Tutorial to run CROWDLAB on your own multi-annotator data in 5min
- CROWDLAB paper containing all the mathematical details and extensive comparisons against other methods
- Code to reproduce our multiannotator benchmarks
- Example on how to run CROWDLAB iteratively for even better results than described here
- cleanlab open-source library
Join our community of scientists/engineers to ask questions, see how others used CROWDLAB, and help build the future of open-source Data-Centric AI: Cleanlab Slack Community
Easy Mode
Don’t have an awesome ML model yet, or want to instantly curate your multi-annotator data with CROWDLAB?
Try Cleanlab Studio via our multi-annotator data quickstart tutorial.
While the cleanlab package helps you automatically find data issues, you’ll need ML expertise as well as an interface to efficiently fix these issues your dataset. Providing all these pieces, Cleanlab Studio finds and fixes errors automatically in a no-code platform (no ML expertise required). There’s no faster way to increase the value of your existing data and develop reliable ML.
