Segmentation models automatically categorize all regions of an image, and are vital in applications like robotics or medical imaging (e.g. to highlight the location of a tumor/injury). Because each pixel in an image segmentation dataset receives its own class label, correctly annotating such data is painstaking. Many labeling mistakes are inevitably made.
This article summarizes our research paper that extends Confident Learning to develop effective algorithms for estimating annotation quality in semantic segmentation datasets. We have open-sourced these new methods in the cleanlab package for you to automatically find the mislabeled images in your own dataset via one line of code.

Our new algorithm scores each image based on how likely it is correctly labeled overall, as well as estimating which images contain annotation errors. Sorting by these label quality scores helps prioritize which images should be reviewed first. You can run cleanlab’s error detection procedure with any segmentation model that you have already trained for your data – this makes it generally applicable to all sorts of segmentation datasets. See our paper for details of our algorithm and benchmarks of its effectiveness:
Estimating label quality and errors in semantic segmentation data via any model
We ran cleanlab on the famous CityScapes segmentation dataset. Here are the images automatically estimated to have the worst annotations within this dataset:

When labeling each of these images, data annotators made major errors that were automatically detected by cleanlab. This allows you to avoid training your segmentation models on bad data! Training ML models with mis-annotated data is like trying to learn from a teacher who occasionally lies – you might get something useful but the results could definitely be improved without incorrect information damaging the process. Mis-annotated data not only harms model training but also model evaluation. Annotation errors don’t just hurt accuracy, they can also introduce bias in your data.
Using cleanlab for segmentation data
You can automatically detect the label errors in your segmentation dataset by training any segmentation model and providing its probabilitistic predictions (pred_probs) for each image to cleanlab. Here is the code we ran to find the above dataset errors and hundreds more:
Sort by the resulting image_scores to reveal the most likely mislabeled images in the dataset.
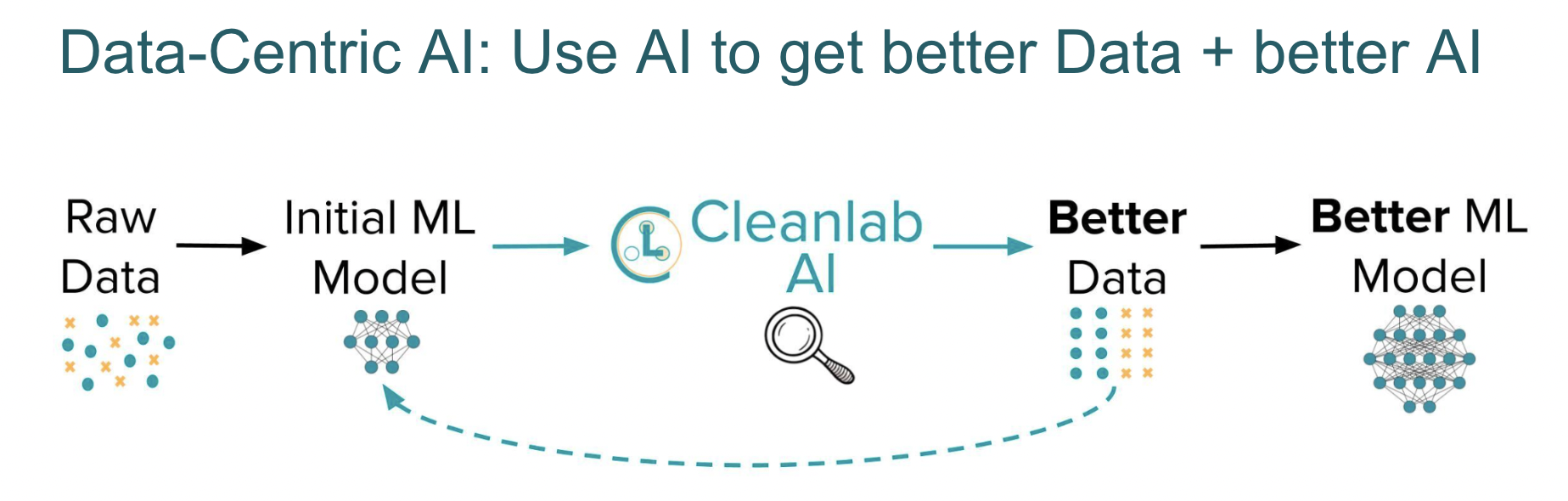
cleanlab.semantic_segmentation can be used with any segmentation model trained via any strategy. You can easily use whatever model is your most accurate with cleanlab to best identify issues in a dataset, and then fix these issues to train an even better version of the same model! After you’ve trained your baseline model, use it with cleanlab to improve your data before you dive into sophisticated modeling improvements. You can subsequently use your better model with cleanlab to better detect additional data issues – fix these issues to get even better models, in a virtuous cycle of data-centric AI.
Why is this method effective?
To flag an image as likely mislabeled, the Cleanlab method carefully considers how confident the segmentation model prediction is, how much it deviates from the original annotation for this image, and how good predictions from the model tend to be. Because per-pixel predicted class probabilities tend to be quite noisy from segmentation models trained on limited data, our method ignores nuisance variation in these probabilities for pixels whose annotations seem ok to more reliably score the overall labeling quality of an image.
Extensive benchmarks reveal that the Cleanlab method detects mislabeled images with higher precision/recall than alternative error detection algorithms, consistently across multiple segmentation models (DeepLabV3+ and FPN). Refer to our paper for more details about benchmarks and our algorithm.
The table below shows the Area under the Precision-Recall curve (higher values are better) for detecting mislabeled images achieved by various label quality scoring methods (across two semantic segmentation datasets, using predictions from either a FPN or DeepLabV3+ model).
| Method | Model | Dataset 1 | Dataset 2 |
|---|---|---|---|
| Cleanlab | FPN | 0.875 | 0.461 |
| Prediction Error | FPN | 0.814 | 0.399 |
| Balanced Prediction | FPN | 0.681 | 0.440 |
| Label Likelihood | FPN | 0.814 | 0.398 |
| IoU | FPN | 0.749 | 0.320 |
| Cleanlab | DeepLab | 0.888 | 0.545 |
| Prediction Error | DeepLab | 0.814 | 0.474 |
| Balanced Prediction | DeepLab | 0.684 | 0.526 |
| Label Likelihood | DeepLab | 0.813 | 0.472 |
| IoU | DeepLab | 0.808 | 0.440 |
Resources
- 5min tutorial on how to apply cleanlab to your segmentation dataset.
- Example notebook that trains a modern segmentation model for use with cleanlab.
- cleanlab open-source package containing the source code of our methods for you to understand their inner workings (and to contribute if you spot opportunities).
- Slack community to provide feedback and see how others are using Cleanlab.
Easy mode: Cleanlab Studio is a no-code tool for curation of image, text, and structured/tabular datasets. Automatically find and fix dataset issues with a few clicks, no machine learning model required! There’s no easier way to improve the quality of your data.