


Data is the food for AI, and producing today’s most advanced AI systems (ChatGPT, StableDiffusion, Autopilot, …) required immense labor to ensure a healthy data diet. Even more mundane data science projects require an expert to spend time exploring the data for issues and fixing them. This article describes new algorithms/software that instead automatically ensure your data is high-quality and free of common real-world issues. We also describe how Cleanlab’s open-source and Studio SaaS offerings fit into the picture and what the future holds.

5–10 years ago, the best ML models were produced by experts inventing novel architectures and training strategies. Today, the best ML models are produced via established modeling techniques (eg. Transformers for text, XGBoost for tables, etc.) by master data curators who instead invest in systematically improving the data itself. Our vision is that tomorrow, you won’t need to spend so much time manually fixing the data, instead using automated data improvement software that frees you to focus on how data/models are incorporated into business applications. This article outlines our plan to get there.
“In my experience, the phrase ‘you are what you eat’ is exponentially more applicable to AI than to humans.”
– Tweet from @WirelessPuppet
Data-Centric AI?
Everybody knows “Garbage in, garbage out” and that clean data is essential to reliable Machine Learning & Analytics. To many, data-centric AI is a superfluous term in the age of ML, but these folks do not realize you can now use AI to systematically improve the data itself to get even better AI! Learn more via the first-ever class on Data-Centric AI that we recently taught at MIT.

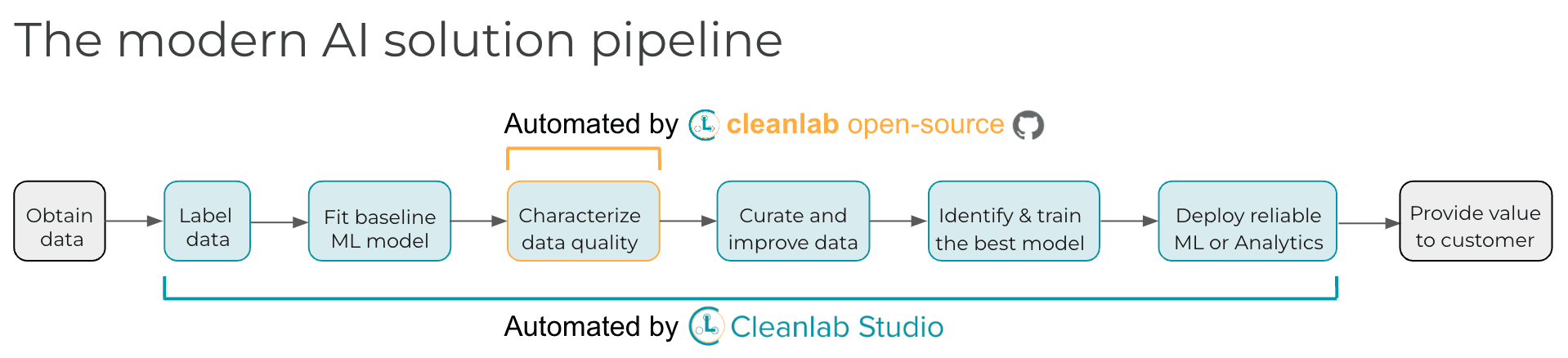
An effective pipeline to produce a good ML model looks like this:
- Explore and transform the raw data to a suitable format to apply ML.
- Train a baseline ML model on the formatted dataset.
- Utilize this model to automatically detect data issues and improve the dataset (via data-centric AI algorithms/software covered in this article).
- Try different modeling techniques to improve the model on the improved dataset and obtain the best model.
Step 3 is where we’re inventing exciting new science and tools. Most folks think all data issues must be manually found and fixed in Step 1, skipping Step 3 to jump straight into modeling improvements (like changing loss functions, optimizers, hyperparameter values).
However even a simple baseline ML model knows a lot of information about its training data, knowledge that can be used to find and fix issues in this data if accessed via the right algorithms. By systematically engineering better data with these algorithms, you can then retrain a new copy of this same baseline model and see large performance improvements without any change to the existing modeling code. This is the promise of data-centric AI!
Of course after improving the data, you can subsequently improve the model via the usual exploration of modeling tricks. Since a better ML model will better detect data issues, you can iterate data & model improvement steps 2-4 in a virtuous cycle (called the Data Engine in tech firms). The remainder of this article demonstrates how you can easily build your own Data Engine thanks to two new types of software: our open-source cleanlab library, and automated data curation application Cleanlab Studio.
Cleanlab Open-Source Library
Our cleanlab open-source package is the most popular software framework for practicing Data-Centric AI today. At a high-level, cleanlab open-source is used like this:
- You provide a ML model trained in a reasonable manner on your dataset.
- cleanlab open-source runs data quality algorithms on the outputs from your model to automatically detect various common issues in your dataset (label errors, outliers, near duplicates, drift, etc).
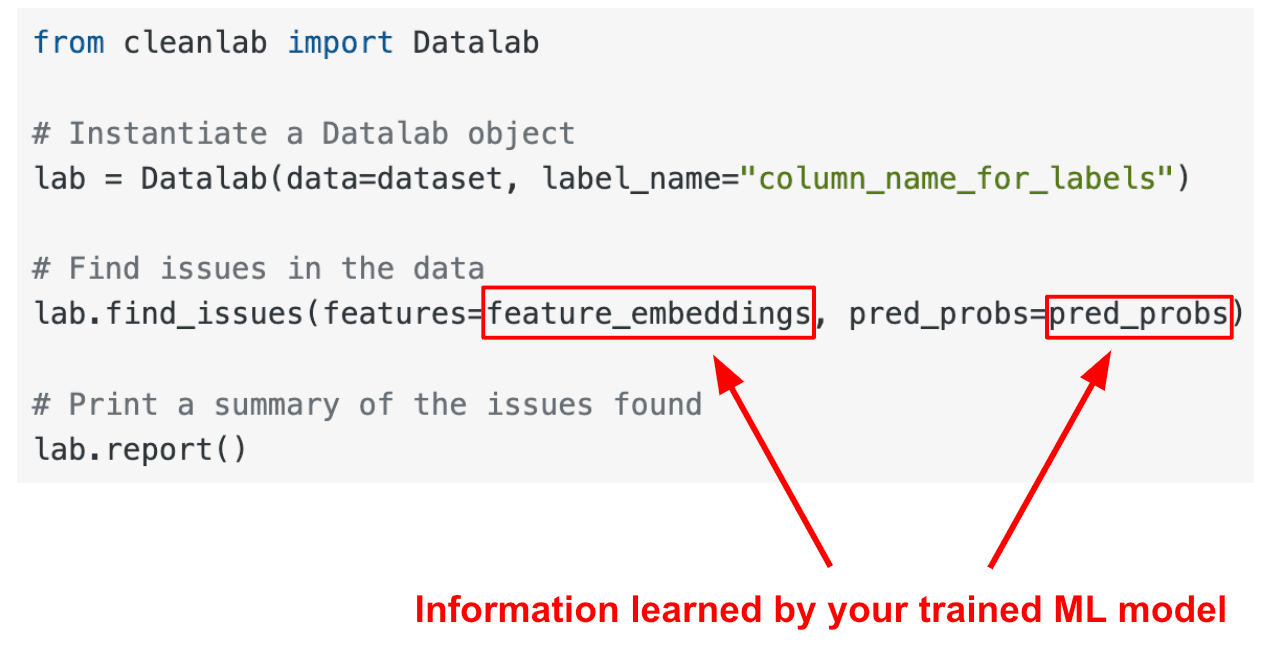
For a Cat-Dog classification dataset and embeddings/predictions from a trained neural network model, the above 3 lines of cleanlab code automatically detect all of these issues:

Based on the cleanlab outputs, you can decide how to improve your dataset and model. This library is extremely flexible and can be used with almost any type of data (image, text, tabular, audio, etc) as long as you’ve fit some standard type of ML model to it. After you’ve improved your dataset, you can re-train the same ML model and see its performance improve without any change to your modeling code!
Most cleanlab open-source functionality comes from novel data quality algorithms invented by our team and published in research papers for transparency and scientific rigor.
Cleanlab Studio
While our open-source library finds issues in your dataset via your own ML model, its utility depends on you having a proper ML model and efficient interface to fix these data issues. Providing all of these pieces, Cleanlab Studio is a no-code platform to find and fix problems in real-world datasets. Beyond data curation & correction, Cleanlab Studio additionally automates almost all of the hard parts of turning raw data into reliable ML or Analytics:
- Labeling (and re-labeling) data
- Training a baseline ML model
- Diagnosing and correcting data issues via an efficient interface
- Identifying the best ML model for your data and training it
- Deploying the model to serve predictions in a business application
All of these steps are easily completed with a few clicks in the Cleanlab Studio application for image, text, and tabular datasets. Behind the scenes is an AI system that automates all of these steps wherever it confidently can. Here’s an overview of Cleanlab Studio applied to correct an image classification dataset:
Labeled data is a prerequisite for most enterprise ML applications. The Cleanlab Studio AI automatically labels much of your data and saves annotation teams time by only asking for help with the most informative examples to label or review.
To automatically detect data issues, Cleanlab Studio runs optimized versions of the same cleanlab open-source data quality algorithms. Unlike cleanlab open-source, it does so on top of an highly performant baseline ML model which is fit to your data using a cutting-edge AutoML system combined with pretrained Foundation models. After correcting the detected data issues, Cleanlab Studio automatically trains an even better ML model using this system which can be seamlessly deployed for real-time or batch inference.
While the cleanlab open-source library auto-detects data issues, addressing the detected problems can be nontrivial. Cleanlab Studio provides an intuitive interface that allows you to employ just the right amount of automation to produce high-quality data quickly. Some data issues can be completely resolved via the app’s Auto-Fix button, whereas others might require your domain knowledge and more manual oversight (you can even correct individual datapoints or batches thereof via a streamlined data correction interface).
Using the no-code version of the application, you can accomplish all of this in your web browser. For developers, Cleanlab Studio offers a Python API that unlocks even greater capabilities. Whether used through Python or the browser, Cleanlab Studio serves as a co-pilot for data scientists to turn raw enterprise data into reliable models, faster.

Comparing Data-Centric AI solutions
An alternate way to convey the difference between cleanlab open-source and Cleanlab Studio software is via analogy: cleanlab open-source is like a doctor for your data that diagnoses issues. To effectively improve data health, the doctor requires lab tests/imaging (trained ML models) and medicine (data correction interface). Either you can provide these yourself (make sure they are good enough), or use Cleanlab Studio which serves as a complete health clinic for your data. Anybody can copy a new ML algorithm, but nobody can copy your company’s data – this is your competitive advantage and investments in its quality will pay off tremendously over the long term.

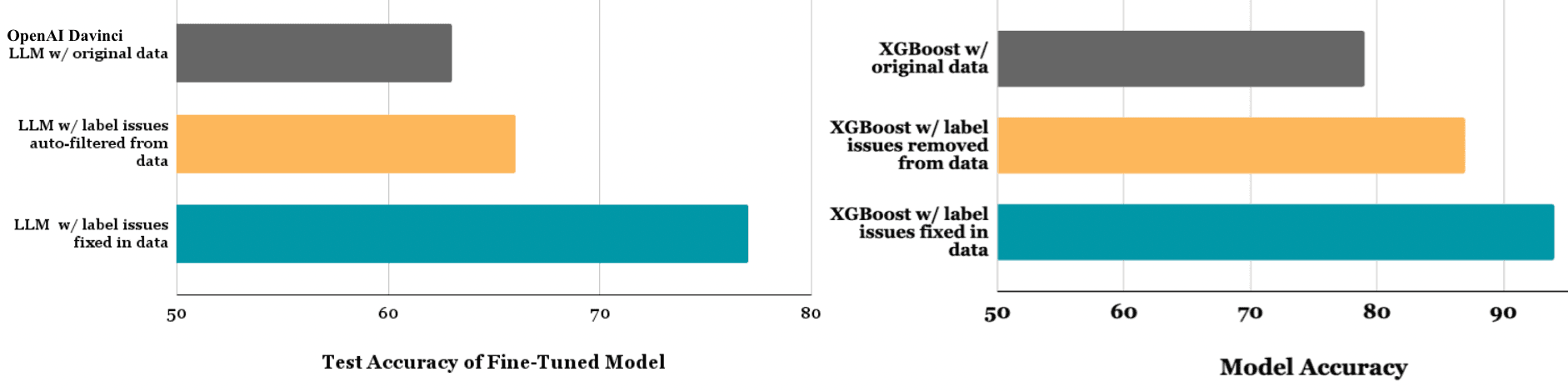
To compare differences in actual ML applications, check out our articles on improving OpenAI LLMs for text data and XGBoost models for tabular data. In both applications, we improve the accuracy of the ML model solely by fixing issues in its training data (no change in modeling code). We train 3 versions of the same ML model and evaluate each on the same high-quality test data:
- one model fit to the original raw data
- one model fit to an auto-filtered dataset (produced by running cleanlab open-source to detect issues in the data and filtering all of the datapoints flagged with issues from the dataset)
- one model fit to an auto-fixed dataset (produced by running Cleanlab Studio to detect issues in the data and automatically fixing them all in its interface).
In both applications, simply filtering all of the data auto-detected with issues by cleanlab open-source does improve the model. But much greater gains are produced by auto-fixing these data issues using Cleanlab Studio.




The future of AI is Data-Centric
AI has never been bigger, but its reliability needs to be improved and that boils down to the data. Today, ML projects often take weeks/months to go from raw data to a successful model deployment producing business value, with 80% of the time often being spent discovering and correcting data issues. This manual data refinement is not only cumbersome, but also requires an expert data scientist to do effectively.
Companies using Cleanlab software can instead automate much of this 80%, achieving not only much faster model deployment, but also allowing their less experienced engineers/analysts to generate business impact via ML on auto-corrected data. This type of software is exactly what folks asked for in a survey of enterprise data science & AI needs from the 2022 AI Infrastructure Ecosystem Report:

This need has only grown with the rise of Generative AI, but an opportunity has also emerged. LLMs and Foundation models are not only hungry for high-quality data, they are also extremely useful for refining data! By combining the immense knowledge from pretrained models together with statistical data patterns revealed by fine-tuned models, Cleanlab Studio automatically diagnoses all sorts of data issues and recommends effective fixes. Cleanlab software can also be applied to the outputs of Generative AI to automatically assess their quality and mitigate issues.
And of course, Generative AI is no exception to “Garbage in, garbage out” – feeding in healthier data produces healthier versions of these LLMs and Foundation models, ensuring a healther world as their impact grows. At Cleanlab, we believe automation is necessary to ensure the health of ever-increasing amounts of data. Join us in our mission!

Recap: What can I get from Cleanlab software?
-
Automated validation of your data sources (quality assurance for your data team). Your company’s data is your competitive advantage, don’t let noise dilute its value.
-
Better version of your dataset. Use the auto-corrected dataset produced by Cleanlab in place of your original dataset to get more reliable ML and analytics, without any change in your existing code!
-
Better ML deployment (reduced time to deployment and more reliable predictions). Let Cleanlab automatically handle the full ML stack for you (produces more accurate models than fine-tuned OpenAI LLMs for text data and the state-of-art for tabular/image data).
Resources
-
Try Cleanlab Studio for free! If your use-case is not supported or if you’re interested in building AI Assistants connected to your company’s data sources and other Retrieval-Augmented Generation applications, reach out to our sales team. Enterprise versions of Cleanlab Studio support many more ML tasks and have much more company-specific functionality than the generally available version of the application.
-
While the cleanlab open-source library is widely applicable, its utility depends on you providing a proper ML model and interpretation of the results. Many of the world’s biggest tech companies (as well as small/medium businesses) have purchased commercial licenses with professional support to optimally integrate cleanlab open-source into their data/AI workflows. If you want to run cleanlab in production but cannot open-source your code to comply with AGPL, reach out to discuss licensing options: sales@cleanlab.ai
-
Join the Cleanlab Slack Community to ask questions and see how scientists/engineers are practicing Data-Centric AI!