
It is critical to check the quality of synthetic data before using it for modeling/analysis, but this can be hard to do precisely. Able to assess most image, text, and tabular datasets, Cleanlab Studio is an AI platform that can automatically diagnose: which synthetic examples do not look realistic, which modes/tails of the real data distribution are poorly represented amongst the synthetic data, as well as which synthetic examples are high-fidelity resembling real data. This article demonstrates how to quickly audit LLM-generated text data with Cleanlab Studio, to prevent bad data from damaging your business!

The demand for synthetic data has grown due to its potential in enhancing model performance, especially when real data is scarce or expensive to collect. However, the quality of this synthetic data is crucial and is not guaranteed even by state-of-the-art generative AI systems. Poor-quality synthetic data may harm model performance, bias the predictions, or even propagate misinformation. Using a case study involving the Rotten Tomatoes dataset where we used Gretel.ai’s synthetic data platform to generate the synthetic data via LLMs, we’ll demonstrate how Cleanlab Studio automtically identifies low-quality synthetic examples and other shortcomings of the synthetic dataset.
This blog studies the use of synthetic data from LLMs in text-based applications, but the same principles apply broadly across other types of synthetic data. You can quantitatively contrast your own synthetic image/text/tabular data against some real data by following this tutorial.
Blending Real & Synthetic: Rotten Tomatoes Dataset
Here we use the Rotten Tomatoes dataset, which consists of positive and negative movie reviews. We generate 8,350 synthetic examples from the training set of the original dataset. For our analysis, we sample only 1,000 examples from the original dataset, equally divided between positive and negative reviews (500 each). We combine these 1,000 real examples with the 8,350 synthetic examples to create a hybrid dataset of 9,350 examples. This is to replicate scenarios where the real data is scarce, and the artificially generated data is added in an attempt to increase diversity and volume of the dataset.
More details on the process of generating synthetic data is at the end of this blog.
Using Cleanlab Studio
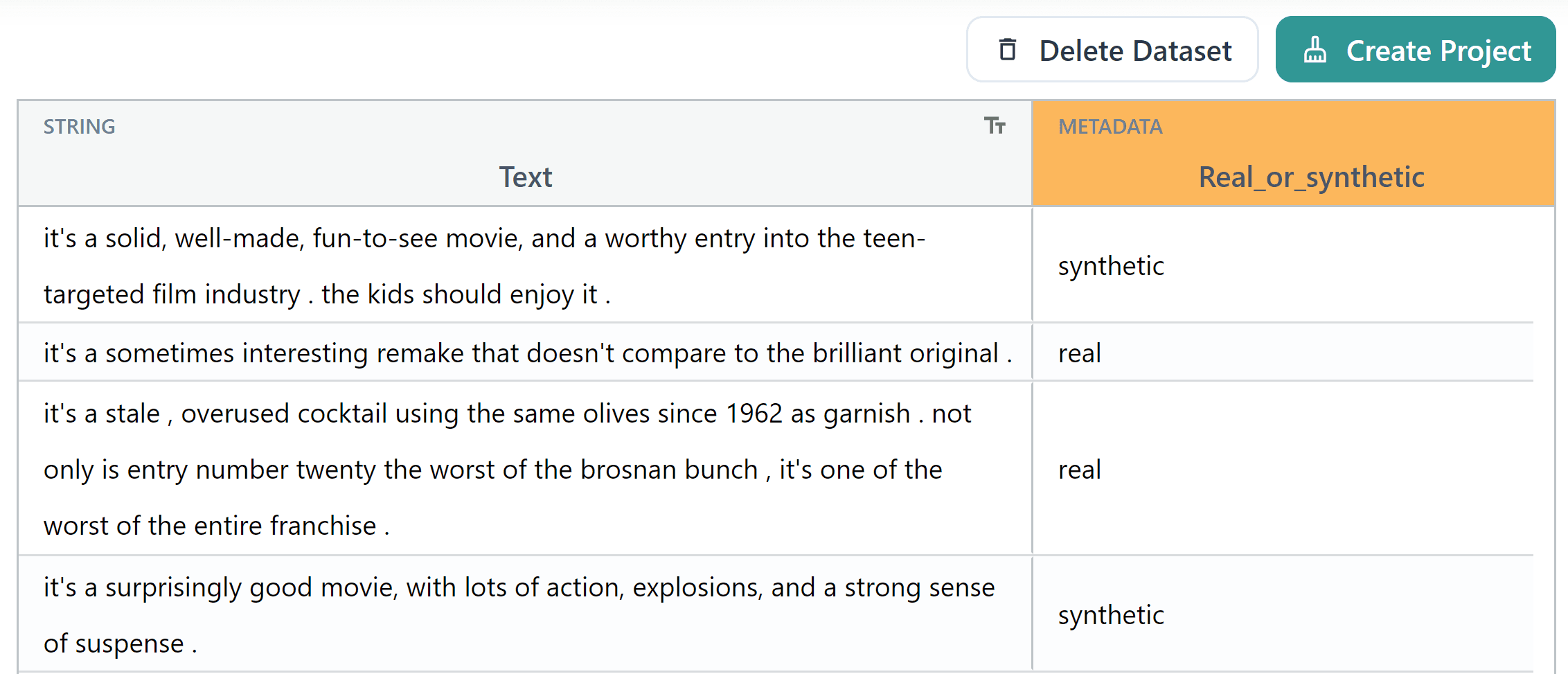
Before uploading the dataset to Cleanlab Studio, we add a new column to the dataset to denote whether the example is real or synthetic (here called Real_or_synthetic) for our analysis.
This Real_or_synthetic column, while used as a label within Cleanlab Studio for the purpose of training a model, is not intended to be used as a predictive feature for any downstream tasks.
Instead, it serves as a descriptor to help us segregate our data for quality analysis. Its primary function is to help us discern the quality differences between data that is real and artificially generated.
In Cleanlab Studio, you can effortlessly perform text classification on your uploaded dataset without writing any code. After uploading your dataset, simply choose Real_or_synthetic as the label column, and click on Create Project. This will instantly initiate the training process.
After training is completed and the project is Ready for Review, Cleanlab Studio assigns a label issue score to each example with a value between 0 and 1.
The issue score is based on the confidence of the models predictions on whether the example is correctly labeled as real or synthetic.
Note that for this analysis, the issue score of an example carries a different interpretation depending on whether it is real or synthetic. We’ll discuss this in more detail for several examples in the sections below.
Cleanlab Studio also flags outliers based on whether the model is uncertain about which label the example should have, but this generally applies to examples that seem out of place in the dataset.
In short, once you have added a Real_or_synthetic column to your data and selected it as the label, then you can use Cleanlab Studio to identify:
- Poor synthetic data as the examples which are synthetic and either receive low label issue score (because these examples are confidently classified as synthetic and are thus obviously unrealistic) or are flagged as outliers (because no similar analogs exist amongst the real data).
- Real data underrepresented in the synthetic samples as the examples which are real and either receive low label issue score (because these examples are confidently classified as real and thus obviously stand out from the synthetic samples) or are flagged as outliers (because no similar analogs exist amongst the synthetic data).
The below table presents different types of examples from the combined dataset, which we categorized based on this strategy.
| Category | Text | Label Issue Score | Is Outlier |
|---|---|---|---|
| Real Data underrepresented in Synthetic Data | follows the original film virtually scene for scene and yet manages to bleed it almost completely dry of humor , verve and fun . | Low | False |
| Synthetic Data that looks realistic | a terrific ensemble cast, great performances by all three leads, and terrific production values . | High | False |
| Synthetic Data that looks unrealistic | a dreary, pointless film . and it’s a waste of all its potential . it’s a mess . it’s a mess . it’s a mess . it’s a mess . | Low | False |
| Real Data underrepresented in Synthetic Data | execrable . | Any | True |
| Synthetic Data that looks unrealistic | a little too rote, a little too earnest, and a little too much too much too soon . | Any | True |
Identifying Bad Synthetic Data
In our scenario, the label issue score helps us pinpoint synthetic instances that fall short in terms of quality. Counterintuitively, a low label issue score for synthetic data is not a good thing. Put simply, these examples stand out as being so obviously artificial that they may lack the depth and detail typical of high-quality, real data. These examples may be unsuitable for training a model, and it may be worth investigating the synthetic data generation process to understand why these examples are so different from the real data. Below are some of these instances where our generated data deviates from the natural language:
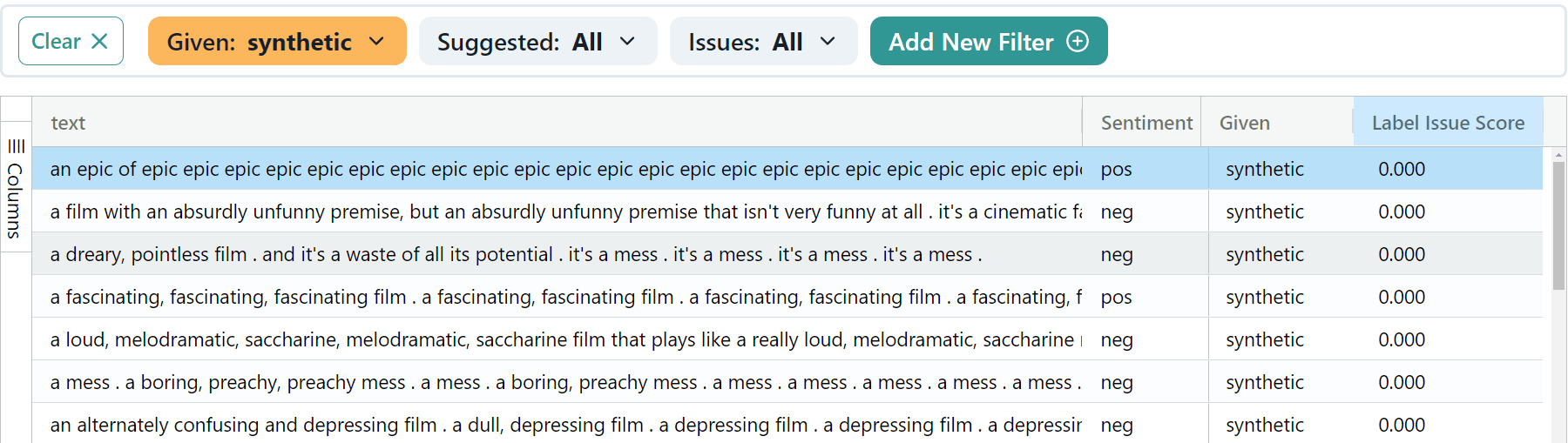
In this case, the worst synthetic examples have the following issues:
-
Redundancy: The synthetic examples often regurgitate the same phrases or opinions, leading to excessive redundancy.
a dreary, pointless film . and it’s a waste of all its potential . it’s a mess . it’s a mess . it’s a mess . it’s a mess .
This not only makes the text feel artificial, but it also fails to introduce new, valuable information.
-
Incoherent Outputs: Some examples contain sentences that are logically inconsistent or nonsensical.
an epic of epic epic epic epic epic …
While the examples may be grammatically correct, they lack semantic coherence or meaningful context.
Finding High-Quality Real Data
On the contrary, low label issue scores for real data mean the exact opposite. These real examples are good, typical examples that we can trust or be more confident about in the original dataset. Consider the examples below that give us a natural feel and appear as something written on a review aggregation site like Rotten Tomatoes. It would be valuable to have more of these kinds examples in our dataset, even if they are synthetic.
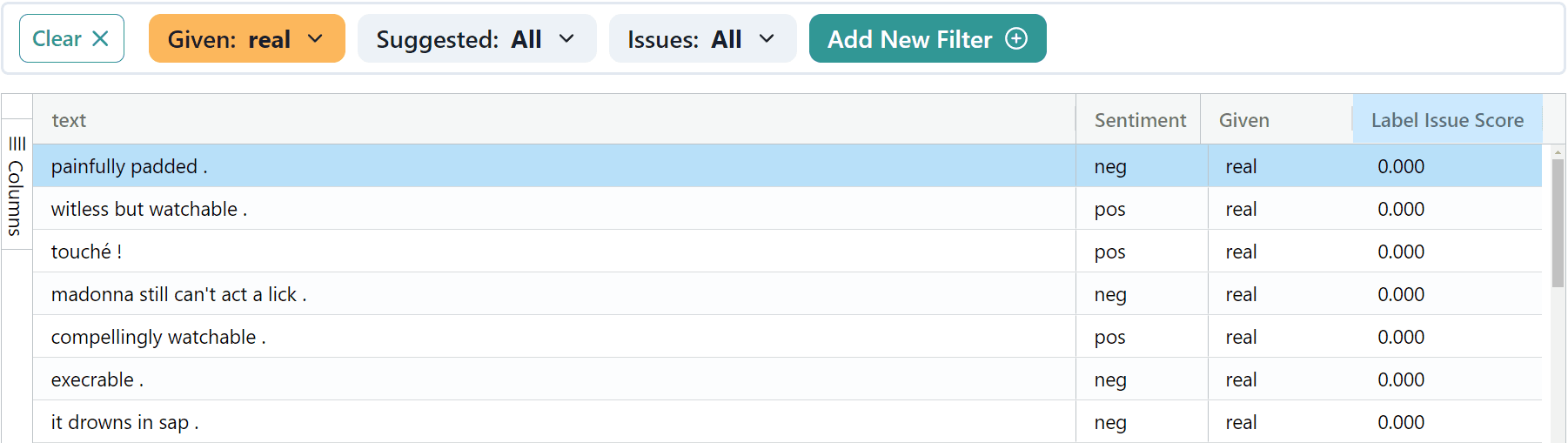
The top real examples (not all shown above) have the following characteristics:
- Clear Sentiment: The examples express a clear tone or attitude towards the movie, whether positive or negative.
execrable .
- Rich Vocabulary: The examples become more expressive and nuanced by using a diverse vocabulary.
hilarious , acidic brit comedy .
- Conciseness: The examples are brief and make their point quickly, while delivering impactful information. They don’t suffer from redundancy like the synthetic examples.
witless but watchable .
- Structural Variability: The examples use different sentence structures and vary in length.
follows the original film virtually scene for scene and yet manages to bleed it almost completely dry of humor , verve and fun .
Walking the Line Between Real and Synthetic
High label issue scores present a different kind of challenge. Whether the example is real or synthetic, if the issue score is high, it becomes challenging for an ML model to distinguish between them.
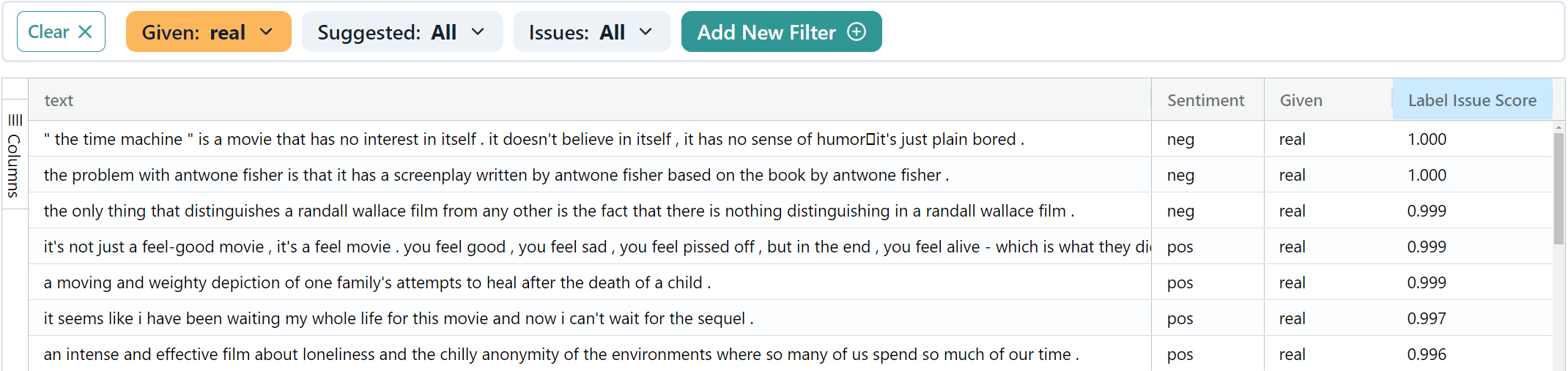
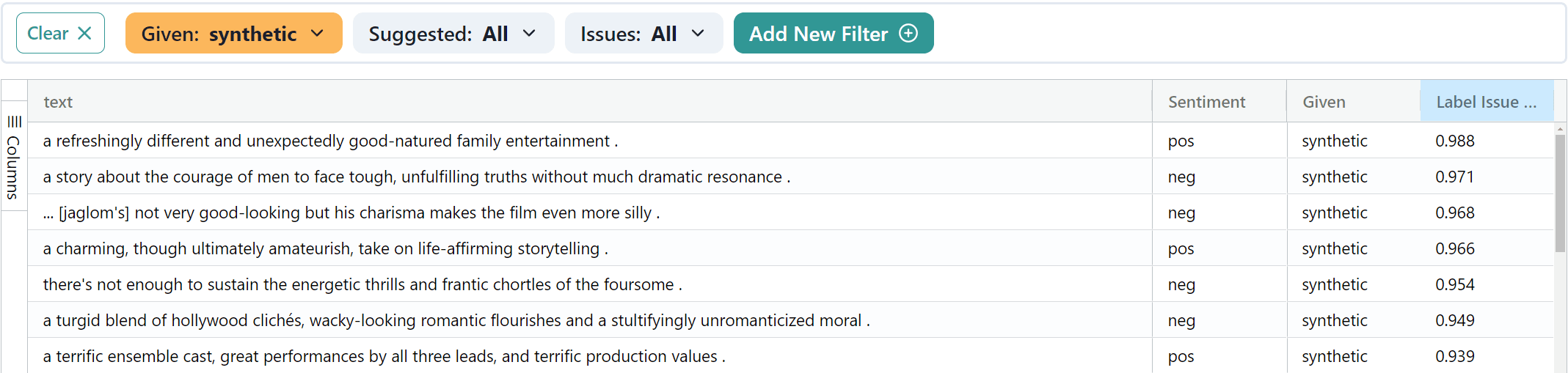
The high label issue examples (whether real or synthetic) have the following attributes:
-
Mixed Sentiment: The class label is less straightforward as the examples express different emotions/tones in the same sentence.
a charming, though ultimately amateurish, take on life-affirming storytelling .
-
More Complex Language: The examples involve more advanced sentence structures and vocabulary.
a moving and weighty depiction of one family’s attempts to heal after the death of a child .
-
Specificity: Some of the examples reference specific entities that may be uncommon, which the models may find difficult to classify.
the problem with antwone fisher is that it has a screenplay written by antwone fisher based on the book by antwone fisher .
-
Natural Language: The synthetic examples with high label issue scores appear more “natural” than the bad synthetic examples.
it seems like i have been waiting my whole life for this movie and now i can’t wait for the sequel .
They don’t suffer from the same issues of redundancy or incoherence, so the model is more likely to consider them as real.
Detecting Outliers
Outliers are examples that diverge significantly from the rest of the data, and Cleanlab Studio automatically detects these based on the predicted probabilities and the overall uncertainty of the classes. Outliers can be found in both real and synthetic data, each posing unique challenges and opportunities for analysis. Cleanlab Studio flags outliers and provides a filter option to show only these examples. Below are both types of outliers shown, the first image showing real outliers and the second showing synthetic outliers.
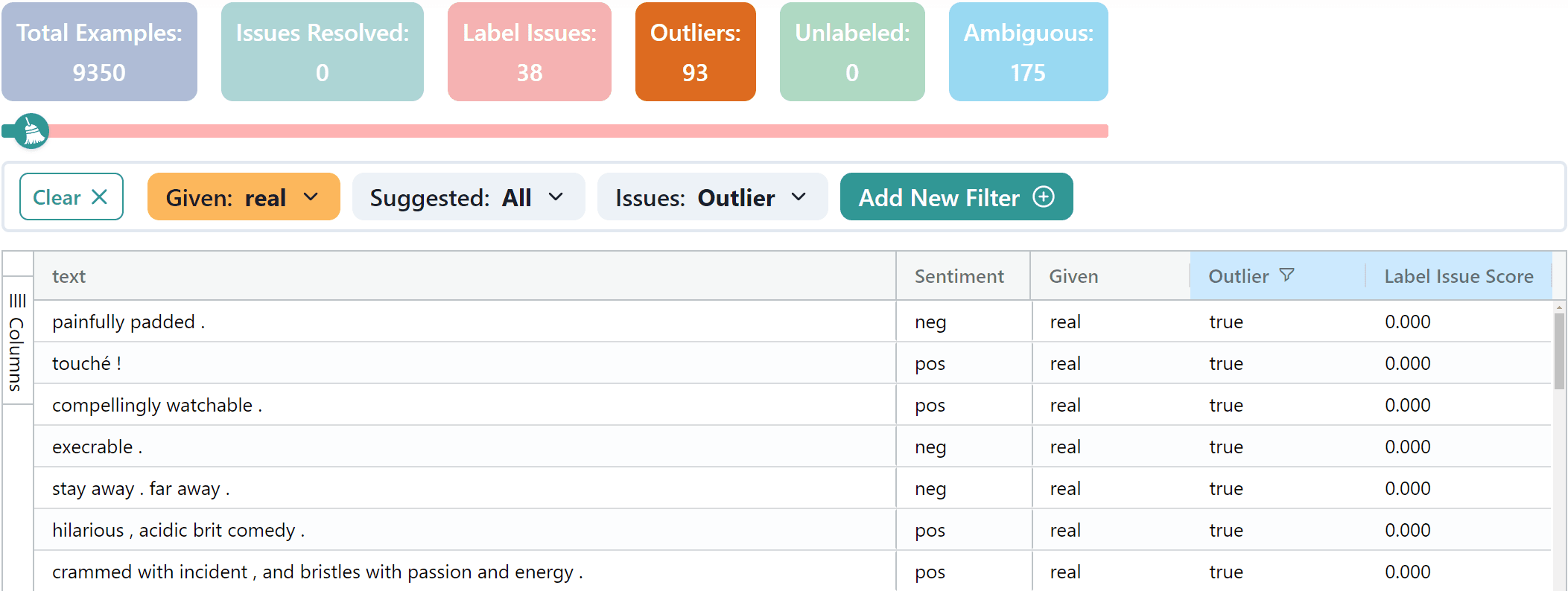

In the real dataset, outliers present a mix of different language styles and expressive sentiments. The diversity of these examples hints at the areas where the synthetic data generation process may be lacking. These real examples are underrepresented in the original dataset, so focusing on generating data similar to these examples may produce a more diverse dataset.
a film with a great premise but only a great premise .
However, synthetic outliers represent the extreme end of LLMs limitations for data generation. This is often due to the excessive repetition of patterns and nonsensical text. In fact, synthetic outliers can introduce noise and potentially misleading signals into the training set. Using these examples allows us to pinpoint the areas that need refinement in the synthetic data generation process.
an epic of epic epic epic epic epic …
Why is clean synthetic data important?
The world of machine learning and data science revolves around data - the more, the better our models tend to perform in the real world. However, in many practical scenarios, gathering enough real-world data to feed these data-hungry models can be challenging, expensive, or even impossible due to privacy concerns.
Synthetic data is leveraged in all kinds of domains, with goals such as:
- Anonymization and Bias Correction in Healthcare.
- Efficient Fraud Detection in Finance.
- Improved Risk Assessment and Fairness in Insurance.
- Quality Assurance and Testing in Software Development.
The broad goal of synthetic data is to boost the performance of machine learning models by providing more data to train on.
The main concern when handling synthetic data is ensuring its quality and accuracy to avoid any unintended consequences. Some common challenges faced when using synthetic data include:
- Avoiding Overfitting: The synthetic data is too similar to the real data, and the model fails to generalize to unseen data.
- Propagating Biases: The synthetic data may contain biases that are present in the real data, and the model may learn to propagate these biases.
- Handling the Domain Gap: Models trained only on synthetic data may not perform well on real data, due to the differences in the underlying distributions.
- Maintaining Textual Coherence and Context: Ensuring factual correctness and preserving the context of the text is crucial for text-based applications.
- Addressing Artifacts and Realism in Images: Synthetic images may contain artifacts or unrealistic features that are not present in real images.
With a tool like Cleanlab Studio, you may more easily diagnose and address these kinds of issues.
Conclusion
Synthetic data holds great promise in reshaping the machine learning landscape, addressing challenges related to data scarcity, privacy, and more. However, the effectiveness of synthetic data hinges on its quality and accuracy in reflecting the structure and patterns in real-world data. Cleanlab Studio makes this process much easier, allowing us to automatically identify and address all sorts of issues with our data, whether real or synthetic.
Resources
-
Cleanlab Studio - Use AI to systematically assess your own synthetic data.
-
Tutorial Notebook - Learn how to quantitatively evaluate any synthetic dataset.
-
Blogpost with Image Data - See how to similarly assess a synthetic computer vision dataset.
-
Slack Community - Discuss ways to use and evaluate synthetic data in this changing field.