
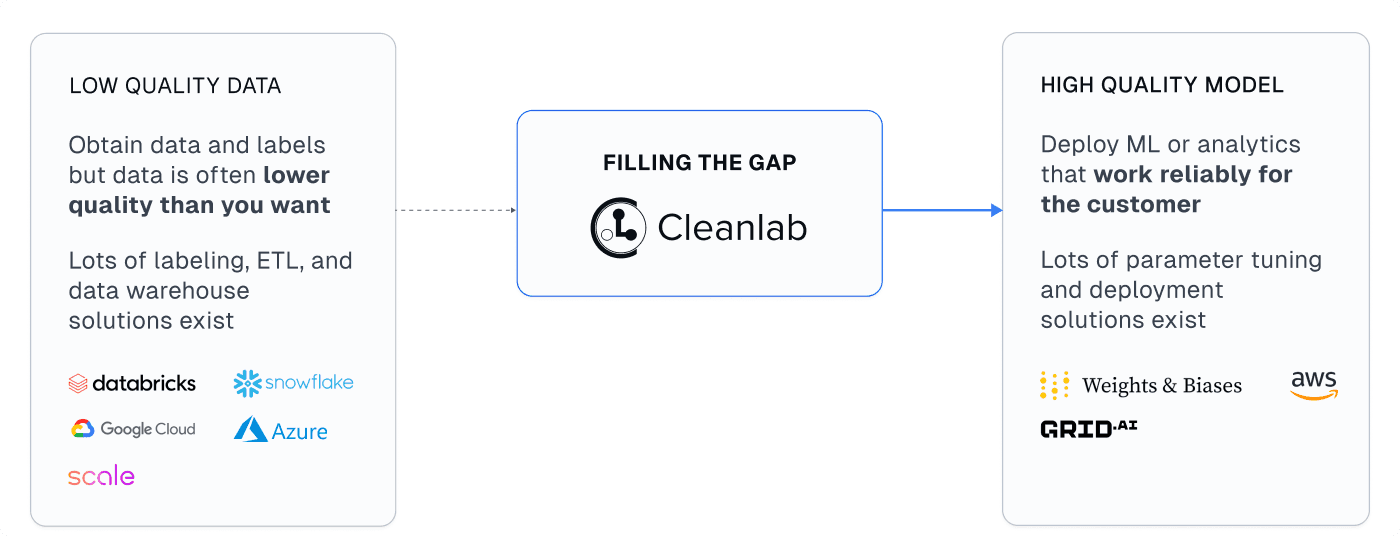
Data Science and AI are reshaping business, driven by new software to quickly translate data-driven ideas into impact. But even though there exist many tools for producing good models, most Data Science and AI projects are still falling short. Success critically relies on the quality of the available datasets (“garbage in, garbage out”). While companies are collecting more and more data, most of it is messy and full of problems. Surprisingly, many teams do not realize this and wonder why modeling efforts / AI products are falling short. Teams that do realize this (OpenAI, Google, Tesla, …) are investing massive amounts of labor to curate their datasets. 80% of a data scientist’s time is typically spent preparing data, and how well they do it affects project outcomes more than their modeling skills.
Since data is the currency of the modern enterprise, tools that maximize its value are growing popular. This article outlines how Cleanlab Studio, a novel data-centric AI platform, compares to other software for: data quality, data cleaning, data annotation, and machine learning.
Cleanlab Studio
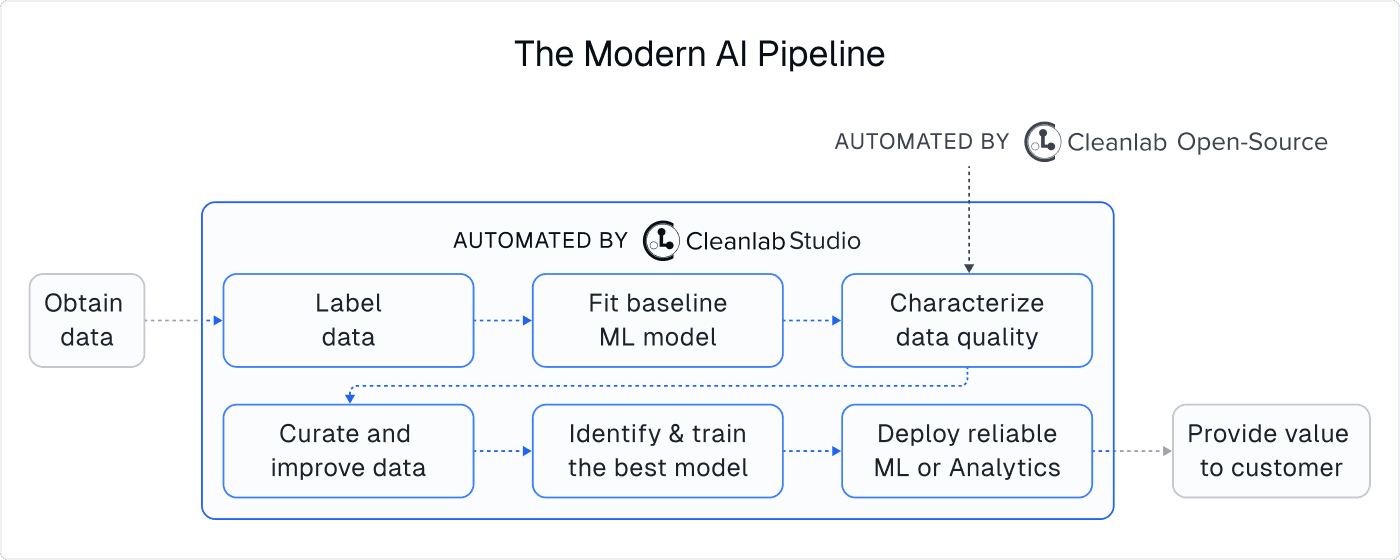
Cleanlab Studio is an easy-to-use tool that uses AI to automatically find and fix issues in raw datasets. Adopted at leading Fortune 500 companies across industries, this Data-Centric AI platform relies on novel algorithms our team previously invented as researchers at MIT. These algorithms automatically estimate which data is most useful (or informative to collect additional annotations for), as well as which data is bad (outliers, mislabeled instances, incorrect values, near duplicates, low-quality images/text, unsafe content, data drift, …). Additional human-in-the-loop algorithms and a data correction interface help you quickly fix the data detected to be bad. Cleanlab Studio is one of the only existing tools that addresses both Data Quality and Machine Learning. It can be used without writing code (offers both a no-code interface and a Python API), and works for image, text, and tabular (CSV, Excel, JSON, SQL) datasets.
A single data scientist can use this tool to fix millions of data points in a massive dataset, thanks to its AI system that helps detect and correct the right information. Beyond improving an existing dataset, the platform allows you to: auto-label data efficiently, generate other useful metadata, or deploy highly accurate ML models with just a few clicks.
Beyond quick model deployment or improving ML/Analytics + data quality, common applications of Cleanlab Studio include:
-
Detecting data entry errors in structured datasets or unsafe/low-quality content in unstructured image/text datasets like product catalogs.
-
Curating text datasets for LLMs to improve fine-tuning, retrieval-augmented generation, prompt engineering, or model evaluation.
-
Improving results and reducing costs in data annotation projects (via AI-automated labeling, active learning, automated quality assurance for labeling errors, annotator assessment).
Although it is internally powered by AI/ML, Cleanlab Studio is not just for AI/ML projects. Teams producing/organizing Data use this tool to deliver better results faster across applications that require accurate information: master data management, product information management, document/content curation, data analytics, … The platform is extremely general and used across many applications/industries (Data/AI consultants especially love it for this reason).
Data Quality Tools
Whether organizations realize it, most of their datasets are full of issues leading to unreliable: AI, Analytics, and information served to employees/customers. Over time, datasets inevitably degrade due to: data entry mistakes, broken data pipelines, anomalous data sources, corrupted measurements, and suboptimal human feedback/annotations. As the value of data increases in the modern age, so does the need for data quality tools that help ensure the information in a dataset is consistent, accurate, and valid. Thus a myriad of data quality tools are available today, some of which also address: data observability, data validation, or data monitoring. We contrast these tools against Cleanlab Studio, whose AI provides automated quality assurance for image, text, and tabular datasets.
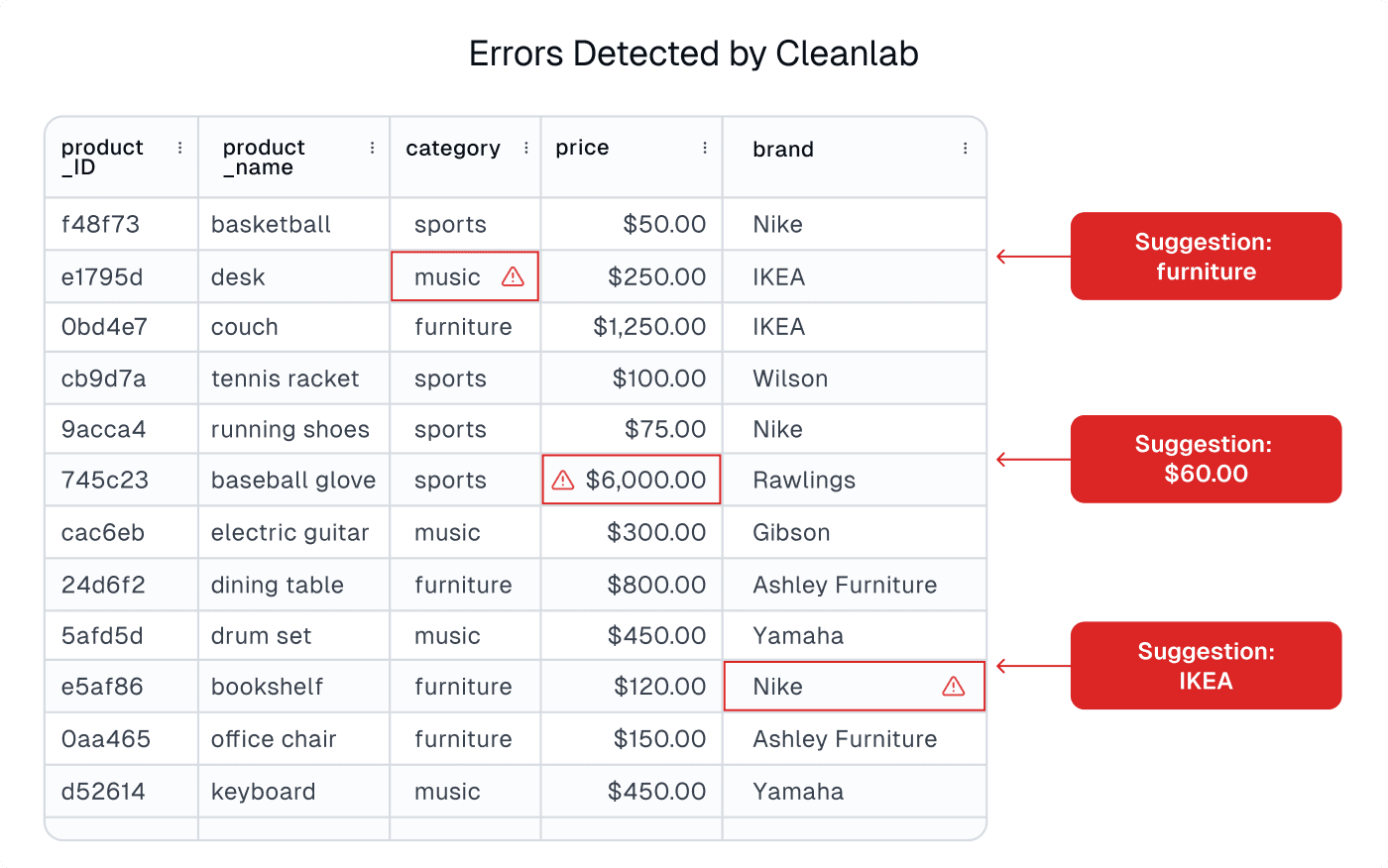
Enterprise datasets have traditionally been structured in a tabular format, and thus most data quality tools are designed for such tabular data, often analyzing it column by column. In contrast, Cleanlab Studio can ensure data quality for tabular and unstructured text/image datasets. Most unstructured image/text datasets remain messy and full of issues – ensuring their quality is just as vital in today’s AI age.
Most data tools today are based on manually-defined rules, in which a team must think of all possible data issues in advance and codify heuristics to detect these issues (e.g. that some column should only contain numbers greater than zero, or at most x% missing values). The data quality tool then runs these rules against data pipelines and flags violations. In contrast, Cleanlab Studio uses novel AI methods to automatically detect common data issues a team never thought of (or knew how to detect). Many of these data issues (label errors, outliers, near duplicates, drift, low-quality images/text, …) can only be auto-detected by understanding the information in each data point, which requires cutting-edge AI. Cleanlab Studio nicely complements rules-based data quality tools: the latter catching domain-specific data issues a team is specifically worried about, and the former catching more general issues the team did not think (or could not afford) to check for in their large datasets.
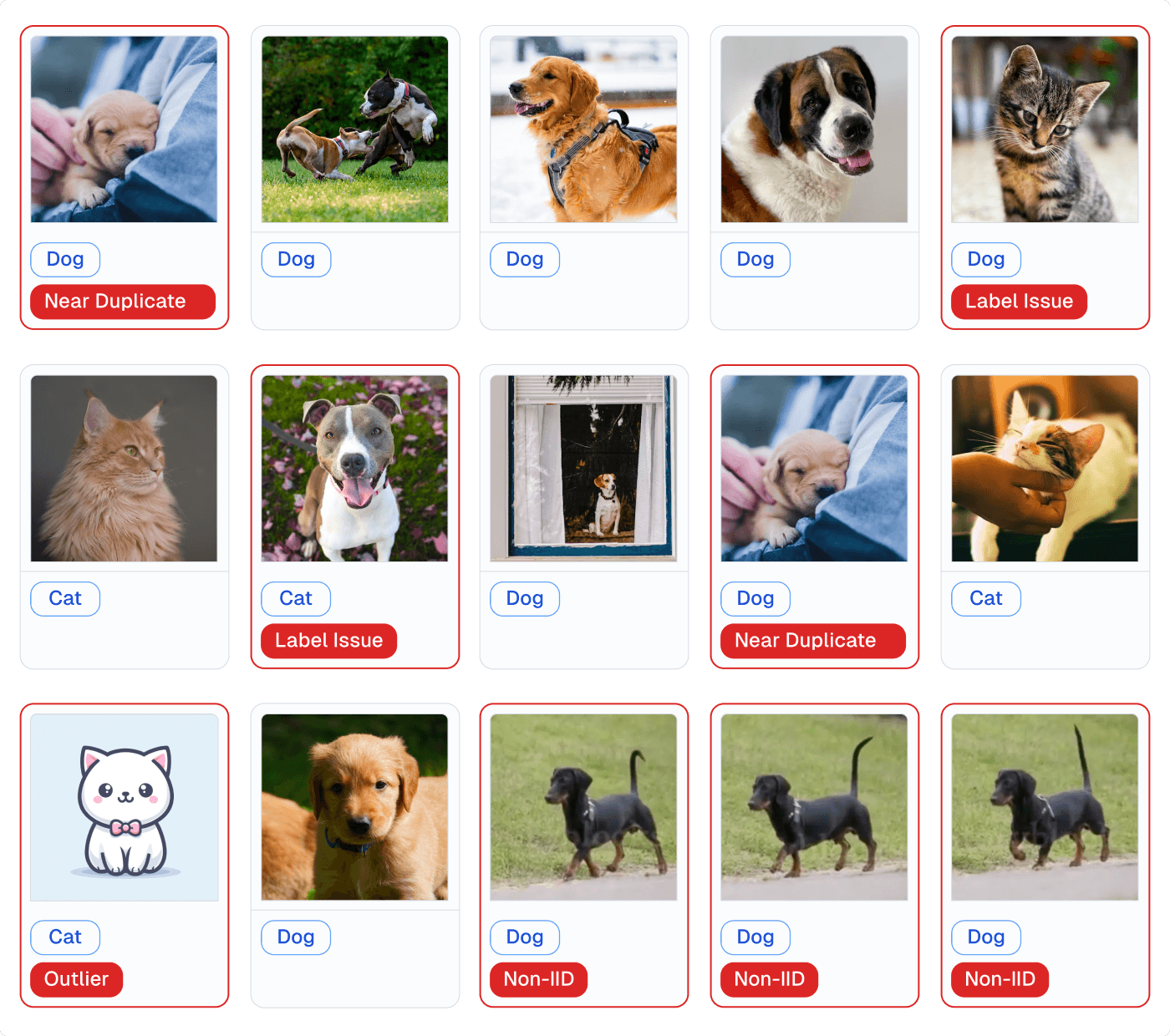
Because AI-based issue detection requires no effort from the user, Cleanlab Studio is significantly easier to use than other data quality tools. While most data quality tools require significant coding to integrate with data pipelines and define issue-detection rules, Cleanlab Studio can be used with just a few clicks via a simple user interface (no coding necessary).

Data Cleaning Tools
Data cleaning gets used as a catch-all phrase for the unglamorous data preparation work required for reliable AI/ML and Analytics. Software products however use this phrase more specifically to refer to specific data transformation capabilities, often performed during ELT/ETL jobs that move data from storage to an analytical compute engine for processing. Data cleaning tools today mostly focus on simple hard-coded data transformation rules applied to structured tabular datasets (e.g. filling missing values in a column, normalizing categories, …).
Cleanlab’s AI system automatically detects issues in structured + unstructured data and generates smart metadata about each data point (e.g. text that contains language which is: toxic, informal, not readable English, Personally Identifiable Information, …). This information can be used to adaptively transform datasets in a fine-grained manner that appropriately processes each individual data point based on the information it contains. Cleanlab Studio additionally provides human-in-the-loop user interfaces to quickly correct individual data points or large batches of data all at once via automatically-suggested actions. Say to curate a text dataset for LLM fine-tuning with Cleanlab Studio, we might automatically delete all text detected to be toxic/informal/unreadable/PII, but manually choose how to handle certain instances auto-detected to contain suboptimal human responses (i.e. data points where the supposedly gold standard output text is actually not so great).
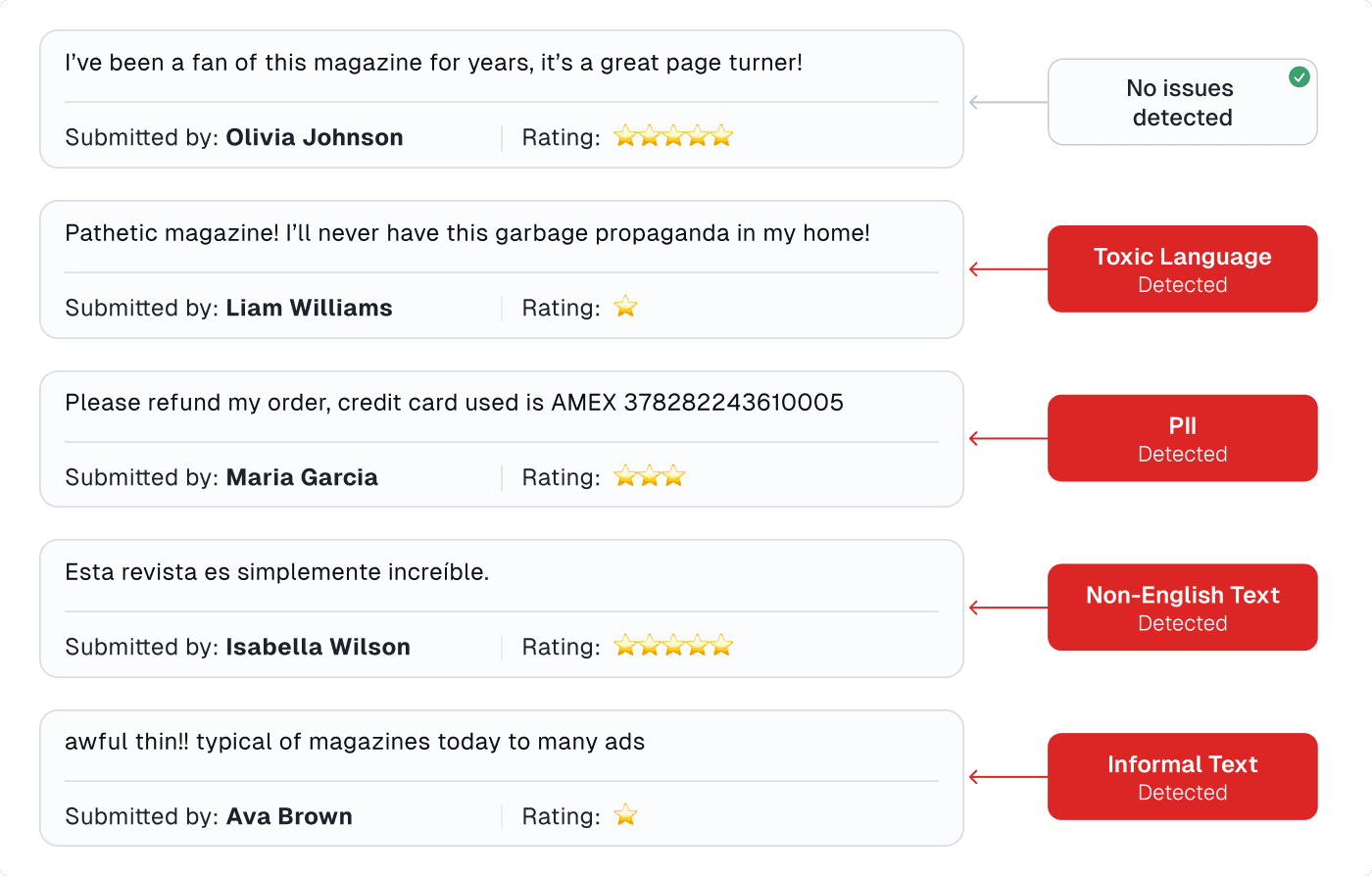
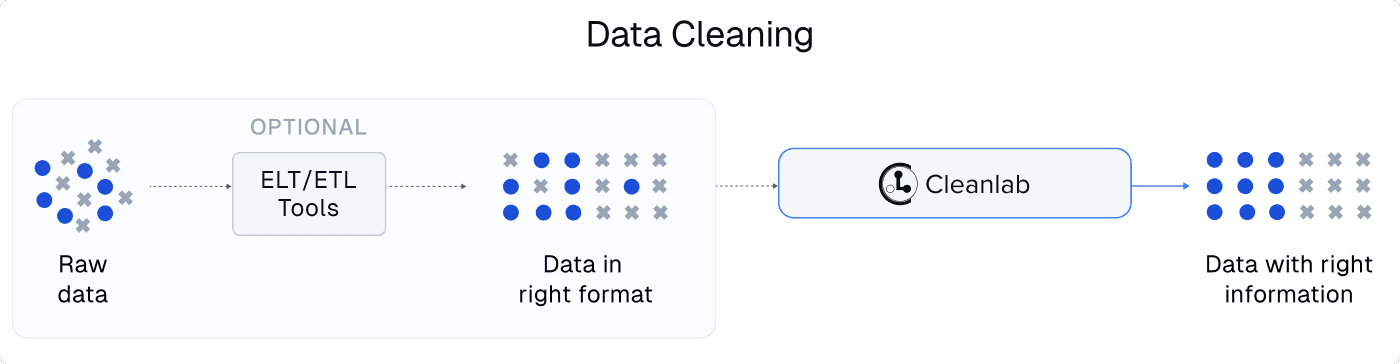
For structured tabular datasets, Cleanlab Studio is often complementary to traditional data cleaning tools. Traditional tools help you properly format a dataset, and Cleanlab helps improve the information in a dataset without changing its format (so that the improved dataset can be used as a plug-in replacement for your original dataset in downstream applications).
ML Platforms
As the impact of AI/ML surges, so does the number of tools for ML modeling. Today’s tools for ML are focused on training and deploying models for a particular dataset, and emphasize many modeling options that users can tinker with. The data preparation work is done separately.
In contrast, Cleanlab Studio is a data-centric AI platform that automatically trains ML models and uses these models to detect/correct the dataset itself, in a virtuous cycle that allows you to do multiple rounds of AI-assisted data preparation to deliver the best results. Cleanlab Studio is able to automatically detect data issues because of the strength of its AutoML system that works out-of-the-box for nearly all image/text/tabular datasets. Users of this platform focus on data curation and let the modeling be automatically handled instead. After a dataset has been cleaned in Cleanlab Studio, it only takes one click to retrain the ML system on the better-quality dataset, and one more click to deploy this ML for serving predictions in a business application. This is one of the fastest ways to go from raw data to highly-accurate deployed models. Even without data curation, ML deployed with Cleanlab Studio is generally as accurate than other ML platforms (via cutting-edge AutoML). With data curation, ML deployed with Cleanlab Studio can be significantly more accurate (for many real-world text datasets, it is superior, faster, and cheaper than fine-tuned OpenAI models).
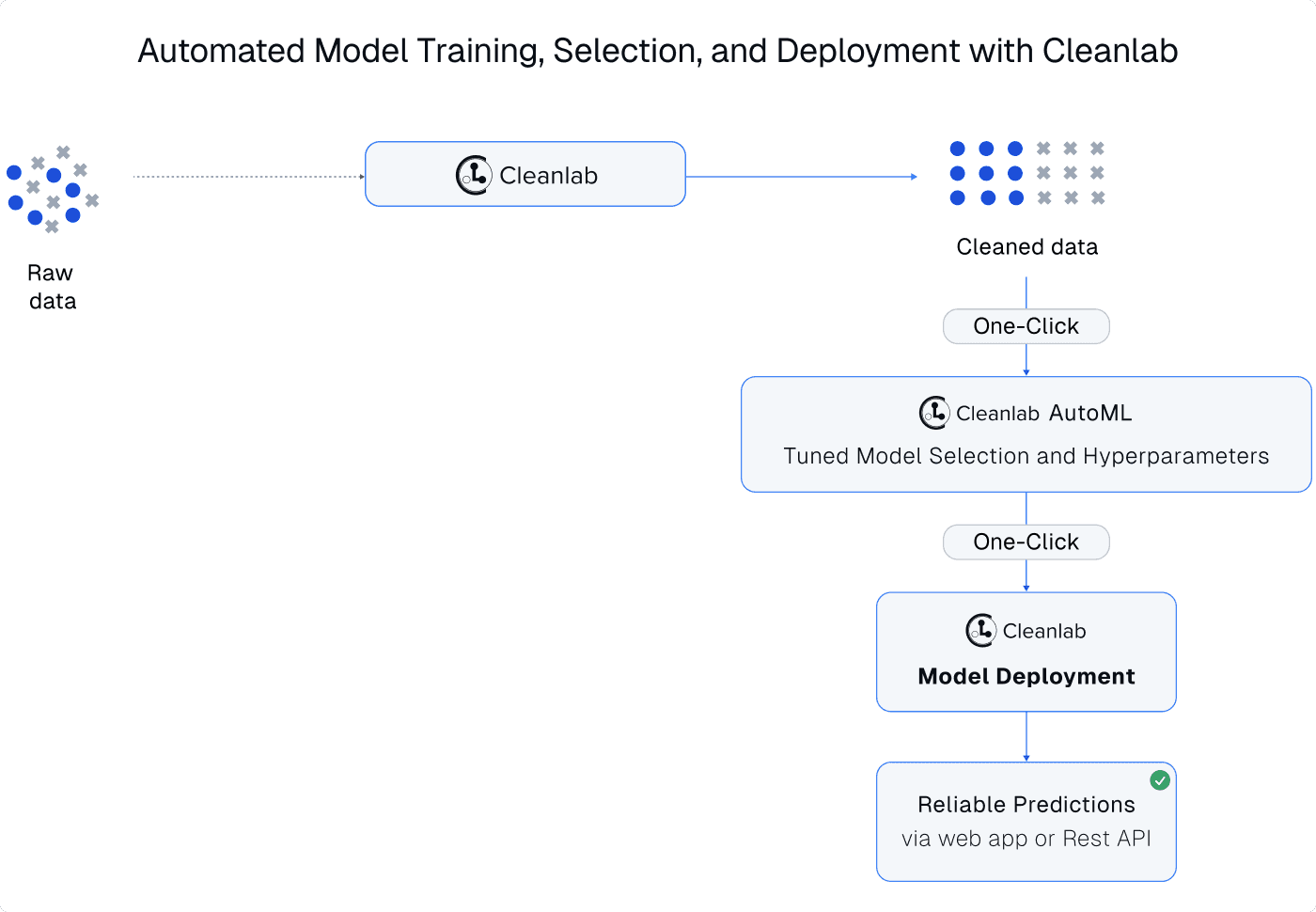
The AutoML deployment capabilities of Cleanlab Studio enable non-ML experts to produce their first AI applications, and are popular amongst understaffed data science & AI teams. If you already have your own ML model deployment, you can alternatively improve its performance by using Cleanlab Studio to improve the training data (no change needed in your existing model / ML stack).
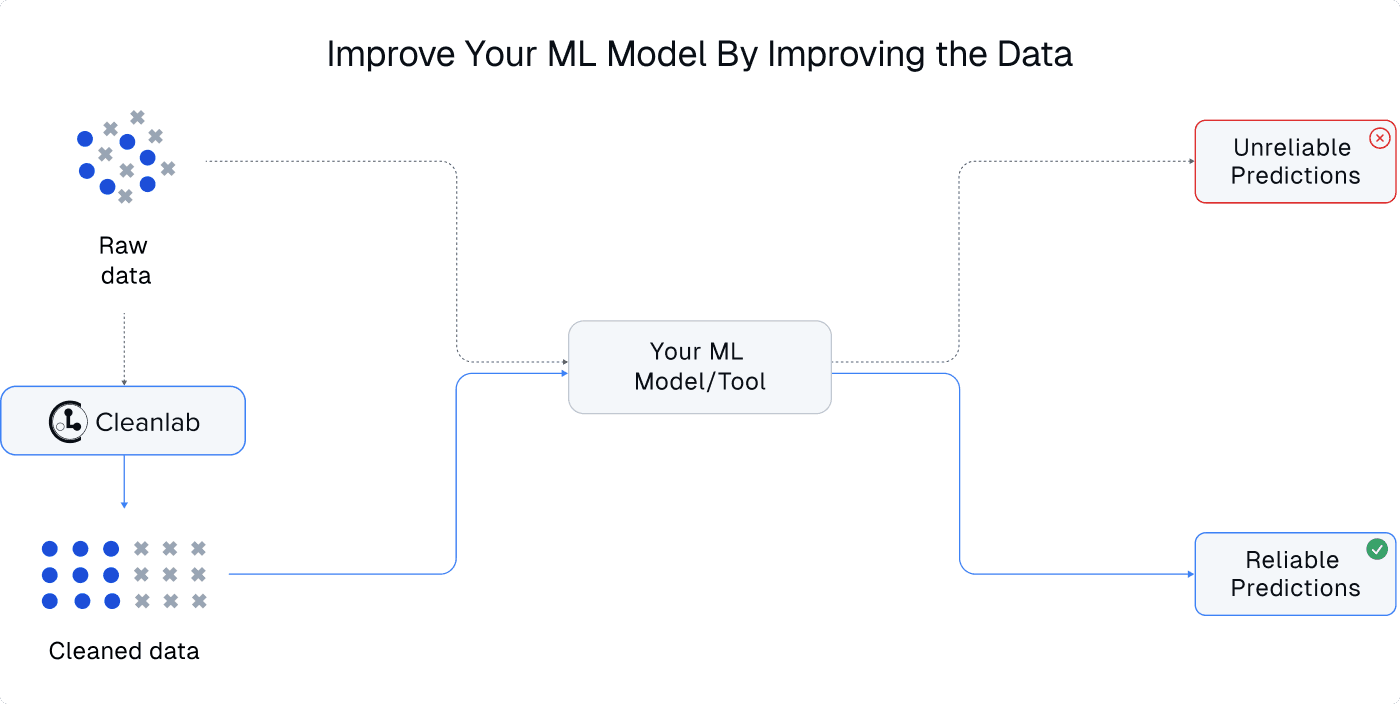
Many of Cleanlab Studio’s internal capabilities like data issue detection and auto-labeling require not only an accurate ML system, but also reliable confidence estimates in order to know which ML outputs are most/least trustworthy. Cleanlab Studio provides API access to these confidence estimates for a wide range of ML models, including LLMs like GPT4.
Data Annotation Tools
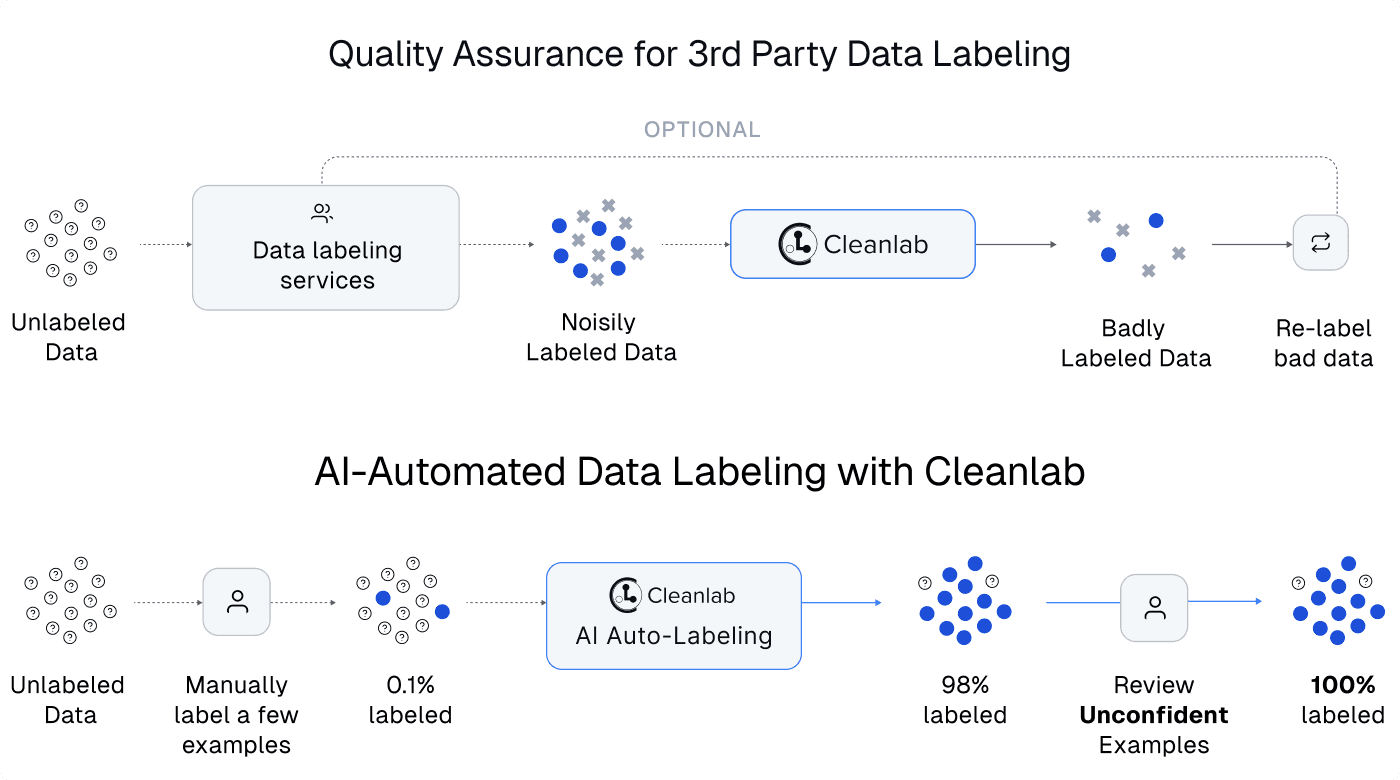
Beyond deploying the auto-trained ML models and using them to find & fix data issues, Cleanlab Studio can also use these models for automated data labeling. Unlike providers of data labeling services (sometimes based on teams of low-wage labor), Cleanlab solely offers software. But the AI-automated data labeling capability allows a single data scientist to annotate massive datasets, by letting the model provide suggested labels for the subsets of the data it can confidently handle.
Unlike many data annotation tools that are specific to one type of data, Cleanlab Studio can label data across different modalities and ML tasks (classification, tagging, regression, entity recognition, image segmentation, object detection, etc). The platform provides the most advanced AI automation and quality assurance to help you label data more quickly and accurately. Many teams using other data annotation platforms/providers still rely on Cleanlab Studio to quickly: assess annotation quality, decide what data needs re-labeling, and produce final data quality improvements before subsequent modeling.
Conclusion
In summary, Cleanlab Studio offers a single platform to handle: data annotation, data preparation (quality assessment and cleaning), and AI/ML modeling. This platform can handle any image, text, and tabular dataset, and can be run from a no-code interface or Python API. Reliable AI/ML requires ensuring reliable data, which is significantly easier to achieve with Cleanlab Studio. Applications of this tool beyond AI/ML include: reliable data analytics, quality assurance for master data management or product information management, document/content curation/organization, and other processes that rely on high-quality data.
Teams using Cleanlab Studio report:
- Much faster time to deployable AI/Analytics (days not months)
- Improvement of existing models via automated data curation (few hours to improve 10-50%)
- Countless long-term benefits after producing better-quality datasets (less confusion, happier customers, fewer delays in future Data/AI projects).
Your data is your competitive advantage. Now you can easily increase its value!
Resources
-
Try Cleanlab Studio for free! Reach out if your use-case is not supported: sales@cleanlab.ai. Enterprise versions of Cleanlab Studio support many more ML tasks and have much more company-specific functionality than the generally available version of the application.
-
Explore applications of Cleanlab Studio via blogs, tutorials, videos, and read the research that powers this next-generation platform.
-
Join the Cleanlab Slack Community to ask questions and see how scientists/engineers are practicing Data-Centric AI
