




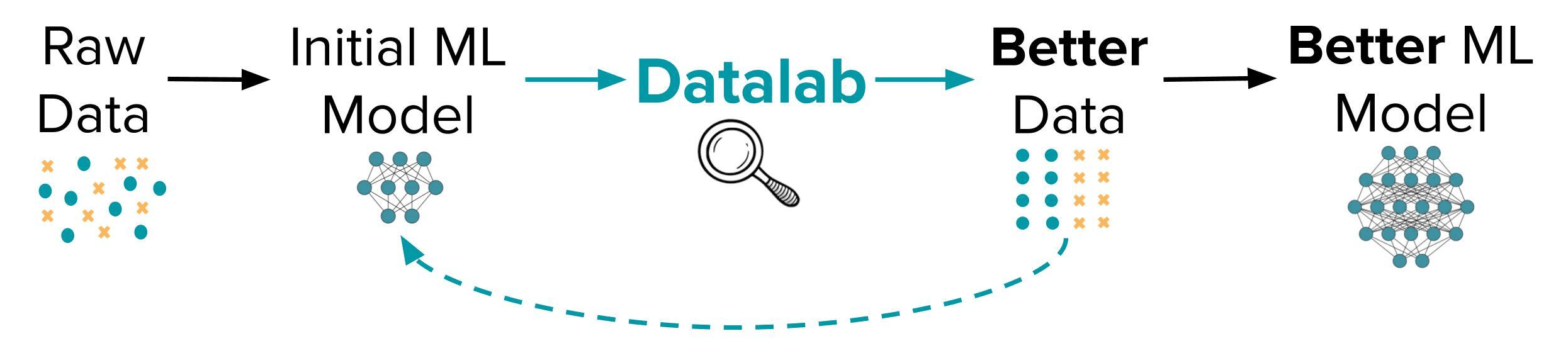
TL;DR – Introducing Datalab, an audit for your dataset and labels that automatically detects common real-world issues like: label errors, outliers, (near) duplicates, low-quality/ambiguous examples, or non-IID sampling. Datalab utilizes any trained Machine Learning model to diagnose dataset problems that can be fixed to produce a better version of this model – all without any change in the modeling/training code.
In Software 2.0, data is the new code, models are the new compiler, and manually-defined data validation is the new unit test. Datalab takes any ML model and combines it with novel data quality algorithms to provide a linter for this Software 2.0 stack that automatically analyzes a dataset for bugs and suspicious entries. Unlike data validation, which runs checks that you manually define via domain knowledge, Datalab adaptively checks for the issues that most commonly occur in real-world ML datasets without you having to specify their potential form. Whereas traditional dataset checks are based on simple statistics/histograms, Datalab’s checks consider all the pertinent information learned by your trained ML model.
Datalab checks a dataset for many issues that may negatively impact subsequent Analytics or trained Models, all without requiring you to have prior knowledge of these potential issues. With one line of code, you can quickly apply Datalab to any dataset (image, text, tabular, audio, etc.) that you’ve fit a ML model to. For instance, Datalab automatically reveals issues like these in a Cat-Dog image classification dataset:

Overview
For ML tasks, the quality of the dataset directly impacts the real-world performance of a trained model – often more than most modeling decisions and fancy training techniques. Today, data scientists just manually inspect a new dataset for issues which is tedious and lacks coverage.
This is made easier and more systematic with Datalab: A unified open-source platform that brings together cleanlab’s algorithms for automatically detecting many sorts of data quality issues. Use your existing models + cleanlab algorithms to help you curate your dataset, rather than doing it all manually!
In this post, we’ll analyze a small variant of the popular Caltech-256 image classification dataset. Below, you can see the 5 classes of our dataset, along with random examples of each class.

Using Datalab
Datalab can operate on predictions and/or representations from any ML model you have already trained (specifically, predicted class probabilities: pred_probs, and vector data representations: feature_embeddings, which may be hidden activations in a neural network or preprocessed features from a simple data transformation/normalization). Here we employ predictions and embeddings from a Swin Transformer model fit to our image dataset.
Inspecting your dataset with Datalab merely requires the code below.
Here is a notebook to reproduce all results presented in this article.
What can Datalab do?
Datalab automatically checks for common types of real-world issues in your dataset:
- Outliers
- Label errors
- (Near) duplicate examples
- Non-IID sampling (drift, autocorrelation, …)
- Low-quality/ambiguous examples
- Your own custom issue types can be easily added to the set that Datalab checks for
This article focuses on the types of issues detected in our animal image classification dataset. Upcoming blogposts will cover the remaining issue types. For each type of issue, Datalab automatically estimates: which examples in the dataset suffer from this issue, how severe this issue is in each example (via a numeric quality score), and how severe overall the issue is across the dataset. Below we dive into the Datalab results for each issue type, all of which were obtained just by running the above code once on our image dataset.
Detect Outliers
Outliers are examples that are fundamentally very different from the rest of the dataset, perhaps because they:
- Stem from a different distribution than the other data.
- Are rare or anomalous events with extreme values.
- Have measurement or data-collection errors.
Remember that not all outliers are necessarily hurtful to a model. Some outliers might represent rare but important events that the model should learn to recognize. Use your domain knowledge and the context of your specific use case to decide whether or not an outlier is irrelevant and should be removed from the dataset. We’ve published the algorithms used to detect outliers based on either numerical features/embeddings or predicted class probabilities.

The figure above showcases instances that Datalab identified as outliers in our dataset. Each row in the image grid consists of one detected outlier (highlighted in orange) and a set of typical images with the same class label (highlighted in blue).
Many of the worst outliers according to Datalab appear to be images that don’t actually depict any of our 5 classes (“frog”, “ibis”, “penguin”, “swan”, “toad”). Such dirty data is often lurking in real-world datasets and can have an outsized impact on models. Carefully consider whether certain outliers should be excluded from your dataset!
Detect Label Issues
In most real-world data used for supervised learning, many examples are actually mislabeled due to annotator error. Training a model to predict incorrect labels is highly detrimental for obvious reasons, less apparent is that evaluating models on data with label errors is harmful as well.
cleanlab originally became widely adopted as a tool to detect such label errors via Confident Learning algorithms. Since then, we’ve built this package into a broader framework for data-centric AI, culminating with the new Datalab platform. With one line of code, Datalab detects label errors (via Confident Learning) as well as many other important issues (via other algorithms also invented by our scientists).

The above figure depicts some of the label issues Datalab detected in our image dataset. For each example flagged with a label issue, Datalab suggests a predicted class that appears more appropriate.
For example, the “frog” and “toad” classes can sometimes be difficult to distinguish by eye, so it’s not surprising that some examples happened to be mislabeled. A frog’s skin is typically smooth and moist, whereas a toad’s skin is typically dry and bumpy. Nevertheless, there are always exceptions to this rule that may be difficult to spot.
Detect (Near) Duplicates
A (near) duplicate issue refers to two or more examples in a dataset that are extremely similar to each other, relative to the rest of the dataset. The examples flagged with this issue may be exactly duplicated, or lie atypically close together when represented as vectors (i.e. feature embeddings). Including (near) duplicates in a dataset may negatively impact a model’s generalization performance and lead to overfitting. Be especially wary of splitting (near) duplicates across training/test sets. Near duplicated examples may record the same information with different:
- Abbreviations, misspellings, typos, formatting, etc. in text data.
- Compression formats in audio, image, and video data.
- Minor variations which naturally occur (e.g. translated versions of an image).

The above figure shows exact and near duplicates detected by Datalab in our dataset. The near duplicates are highlighted with a difference map between the two images. Beyond flagging which examples suffer from each type of issue and how badly, Datalab also returns additional useful information about some issues, e.g. which sets of examples are duplicates in this case.
Conclusion
Running the simple Datalab code snippet above, we discovered all of these diverse issues lurking within our image classification dataset. The exact same code works for data from other modalities like text, tables, audio, etc. for which you have trained a ML model, because Datalab only depends on its predictions and/or embeddings. Before diving into improving your model via architecture/training alterations, use it with Datalab to see if easy dataset improvements exist that can improve your initial model without changing its code!
By automatically flagging data issues like outliers, label errors, (near) duplicates, non-IID sampling, and low-quality/ambiguous examples, Datalab enables data scientists to build reliable models from unreliable datasets. Using predictions and/or embeddings from a better initial model will allow Datalab to more accurately estimate issues, such that you can get an even better dataset, which in turn can train an even better model. Iterate this virtuous cycle of data and model improvement, and witness the power of data-centric AI in real-world applications.
Datalab is open-sourced in the cleanlab package (as of version 2.4.0), which is growing into a general-purpose library like scikit-learn but for improving datasets rather than models. Today, a single line of Datalab code allows you to run many important types of data quality algorithms on your dataset. Tomorrow, the Datalab platform will simultaneously apply all of cleanlab’s data-centric AI capabilities, as well as effective methods from the latest research in this area. It’s easy to add custom data quality checks into the Datalab platform, so they can be automatically run with the rest of the dataset audit. Reach out (or open Pull Requests) to help build the future of data-centric AI and ensure it remains open-source!
Resources
- Quickstart Tutorial for using Datalab to inspect your own datasets.
- Example Notebook on how to find the data issues shown in this article by running Datalab on our dataset.
- Datalab Documentation to understand the APIs of this platform and the types of data issues.
- Cleanlab Slack Community: See how others are using Datalab, discuss ideas for further automating data-quality, and decide which algorithms should be added to this open-source platform.
Easy Mode
While Datalab finds data issues (via your own ML model), an interface is needed to efficiently fix these issues in your dataset. Cleanlab Studio is a no-code platform to find and fix issues in real-world datasets (no ML model required). Cleanlab Studio automatically runs optimized versions of Datalab’s algorithms on top of AutoML & Foundation models fit to your data, and presents detected issues in a smart data editing interface. Think of it like a data curation assistant that helps you quickly improve the quality of your data (via AI/automation + streamlined UX).
See how easy it is to detect all sorts of issues in the famous ImageNet dataset with Cleanlab Studio.
