
The cleanlab library was originally open-sourced to accompany a research paper on label errors in classification tasks, to prove to skeptical researchers that it’s possible to utilize ML models to discover mislabeled data and then train even better versions of these same models. We’ve been hard at work since then, turning this into an industry-grade library that handles label errors in many ML tasks such as: entity recognition, image/document tagging, data labeled by multiple annotators, etc. While label errors are critical to deal with in real-world ML applications, data-centric AI involves utilizing trained ML models to improve the data in other ways as well.
With the newest release, cleanlab 2.3 can now automatically:
- find mislabeled data + train robust models
- detect outliers and out-of-distribution data
- estimate consensus + annotator-quality for multi-annotator datasets
- suggest which data is most informative to (re)label next
We have 5min tutorials to get started with any of these objectives and easily improve your data!
A core cleanlab principle is to take the outputs/representations from an already-trained ML model and apply algorithms that enable automatic estimation of various data issues, such that the data can be improved to train a better version of this model. This library works with almost any ML model (no matter how it was trained) and type of data (image, text, tabular, audio, etc).
We want this library to provide all the functionalities needed to practice data-centric AI. Much of this involves inventing new algorithms for data quality, and we transparently publish all of these algorithms in scientific papers. Read these to understand how particular cleanlab methods work under the hood and see extensive benchmarks of how effective they are on real data.
What’s new in cleanlab 2.3:
Here we only highlight major new aspects of the library. Many additional improvements have been made. A detailed change log is available in the release notes.
Active Learning with ActiveLab
For settings where you want to label more data to get better ML, active learning helps you train the best ML model with the least data labeling. Unfortunately data annotators often give imperfect labels, in which case we might sometimes prefer to have another annotator check an already-labeled example rather than labeling an entirely new example. ActiveLab is a new algorithm invented by our team that automatically answers the question: which new data should I label or which of my current labels should be checked again? ActiveLab is highly practical — it runs quickly and works with: any type of ML model, batch settings where many examples are (re)labeled before model retraining, and settings where one or multiple annotators can label an example.
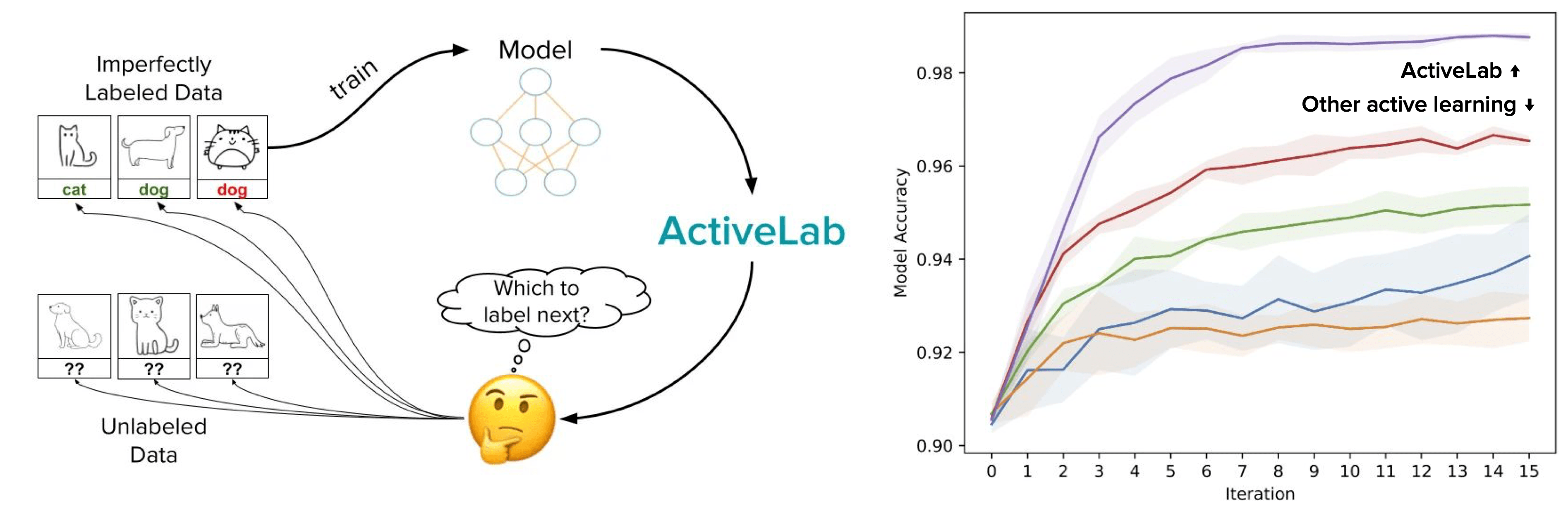
Here’s all the code needed to determine active learning scores for examples in your unlabeled pool (no annotations yet) and labeled pool (at least one annotation already collected).
The batch of examples with the lowest scores are those that are most informative to collect an additional label for (scores between labeled vs unlabeled pool are directly comparable). You can either have a new annotator label the batch of examples with lowest scores, or distribute them amongst your previous annotators as is most convenient. ActiveLab is also effective for: standard active learning where you collect at most one label per example (no re-labeling), as well as active label cleaning (with no unlabeled pool) where you only want to re-label examples to ensure 100% correct consensus labels (with the least amount of re-labeling).
Get started running ActiveLab with our tutorial notebook from our examples repository.
KerasWrapper
We’ve introduced one-line wrappers for TensorFlow/Keras models that enable you to use TensorFlow models within scikit-learn workflows with features like Pipeline, GridSearch and more. Just change one line of code to make your existing Tensorflow/Keras model compatible with scikit-learn’s rich ecosystem! All you have to do is swap out: keras.Model → KerasWrapperModel, or keras.Sequential → KerasSequentialWrapper. Imported from cleanlab.models.keras, the wrapper objects have all the same methods as their keras counterparts, plus you can use them with tons of handy scikit-learn methods.

Resources to get started include:
- Blog post and Jupyter notebook demonstrating how to make a HuggingFace Transformer (BERT model) sklearn-compatible.
- Jupyter notebook showing how to fit sklearn-compatible models to a Tensorflow Dataset.
- Revamped tutorial on label errors in text classification data, which has been updated to use this new wrapper.
Computational improvements for detecting label issues
Through extensive optimization of our multiprocessing code, the find_label_issues method has been made ~10x faster on Linux machines that have many CPU cores.
For massive datasets, find_label_issues may require too much memory to run our your machine. We’ve added new methods in cleanlab.experimental.label_issues_batched that can compute label issues with far less memory via mini-batch estimation. You can use these with billion-scale memmap arrays or Zarr arrays like this:
By choosing sufficiently small batch_size, you should be able to handle pretty much any dataset (set it as large as your memory will allow for best efficiency).
Contributors
A big thank you to the data-centric jedi who contributed new code for cleanlab 2.3: Aditya Thyagarajan, Anish Athalye, Chen Lu, Chris Mauck, Curtis Northcutt, Elías Snorrason, Hui Wen Goh, Ikko Ashimine, Jonas Mueller, Mayank Kumar, Sanjana Garg, Ulyana Tkachenko, unna97.
We thank the individuals who contributed bug reports or feature requests. If you’re interested in contributing to cleanlab to advance open-source AI, check out our contributing guide!
Beyond cleanlab 2.3
While cleanlab 2.3 finds data issues, an interface is needed to efficiently fix these issues your dataset. Cleanlab Studio finds and fixes errors automatically in a (very cool) no-code platform. Export your corrected dataset in a single click to train better ML models on better data.
Try Cleanlab Studio at https://studio.cleanlab.ai/.
Learn more
- How Google, Tencent, and others use Cleanlab.
- Ways to try out Cleanlab:
- Open-source: GitHub
- No-code, automatic platform (easy mode): Cleanlab Studio
- Documentation + Tutorials | Example Notebooks | Blog | Research Publications
Join our community of scientists and engineers to learn how folks are using cleanlab and help ensure the future of data-centric AI is open-source: Cleanlab Slack Community