HOW IT WORKS

Facilitate Customer Service Tasks
Supported ML tasks where Cleanlab is particularly effective include: intent recognition, conversational AI, multi-label classification, entity/product recognition, predicting sentiment or emotions.
Train and Produce Reliable Models
Practice data-centric AI to produce accurate ML models for messy real-world tabular or text data. Cleanlab offers powerful automated Machine Learning capabilities so you can focus on what matters — the data.
Boost LLM Reliability
Find and fix problems in any instruction-tuning dataset and fine-tune better LLMs. Audit LLM inputs/outputs and get confidence scores for how trustworthy any LLM response is in order to mitigate hallucination.
CASE STUDIES

Gavagai provides multilingual text analytics for customer insights. Analyzing reviews, surveys, call transcripts, support tickets, and social media, their platform helps discover, track, and act on customer data to improve Customer Experience.
Gavagai relies on labeled data to train our models, and the quality of the data is paramount when it comes to creating machine learning models that can produce business value for our customers. Cleanlab allowed the Gavagai team to upload a dataset and obtain a ranked list of all the potential label issues in the data and assess and fix them in the GUI.
“Cleanlab Studio is a very effective solution to calm my nerves when it comes to label noise [and] should be a go-to tool in every ML practitioners toolbox!”
Head of Data Science at Gavagai
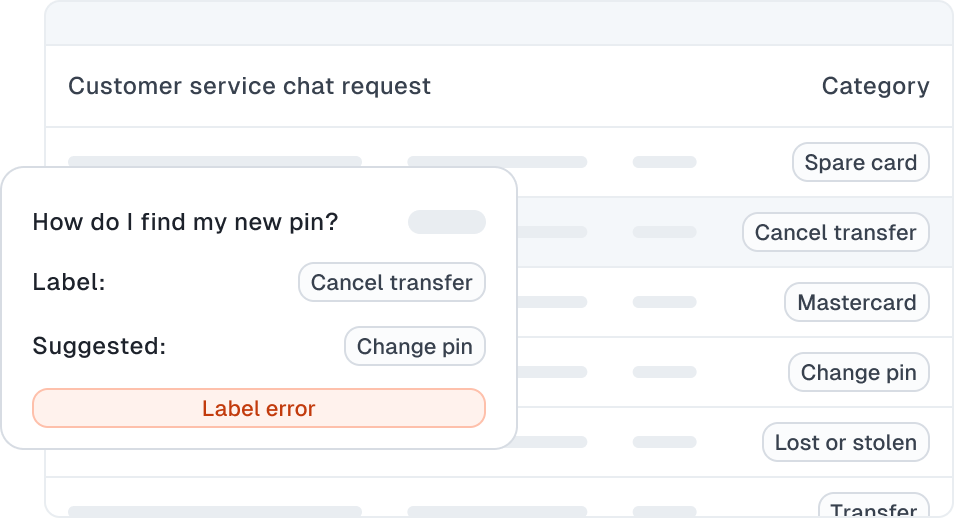
To automatically triage future customer requests, intent classification is a standard Machine Learning task in customer service applications that requires well-labeled data.
A customer at an online bank used Cleanlab on a dataset of customer requests (text) annotated with 10 different intents. Cleanlab Studio found over 5% of dataset labels were incorrect and detected out-of-scope queries (outliers) like “how much is 1 share of aapl” and “is android better than iphone.” The dataset underwent customer analytics to discern the frequency of various customer requests and identify the most prevalent types, but inaccuracies stemmed from mislabeling and out-of-scope issues within the original dataset. A cleaned version from Cleanlab Studio yielded significantly more precise conclusions, resulting in a 16% reduction in prediction error without modifications to the existing LLM Transformer model or training code. Further improvements in accuracy were achieved by addressing additional data issues without altering the model.
5%
of dataset labels found to be incorrect
16%
reduction in prediction error
“Using Cleanlab Studio to auto-fix label issues in this dataset led to a 16% improvement in prediction error without altering the existing LLM Transformer model or training code.”

