

Ensuring factual accuracy in Large Language Models is critical, but models can hallucinate incorrect answers. OpenAI recently open-sourced the SimpleQA benchmark of over 4000 fact-based questions with a single/clear answer that remain challenging for LLMs. This diverse dataset is designed for evaluating the factual correctness of LLMs as well as their ability to abstain from answering (not attempt) when unable to answer accurately. In this article, we run SimpleQA benchmarks to demonstrate how the Trustworthy Language Model (TLM) can improve the performance of any LLM along both of these axes.
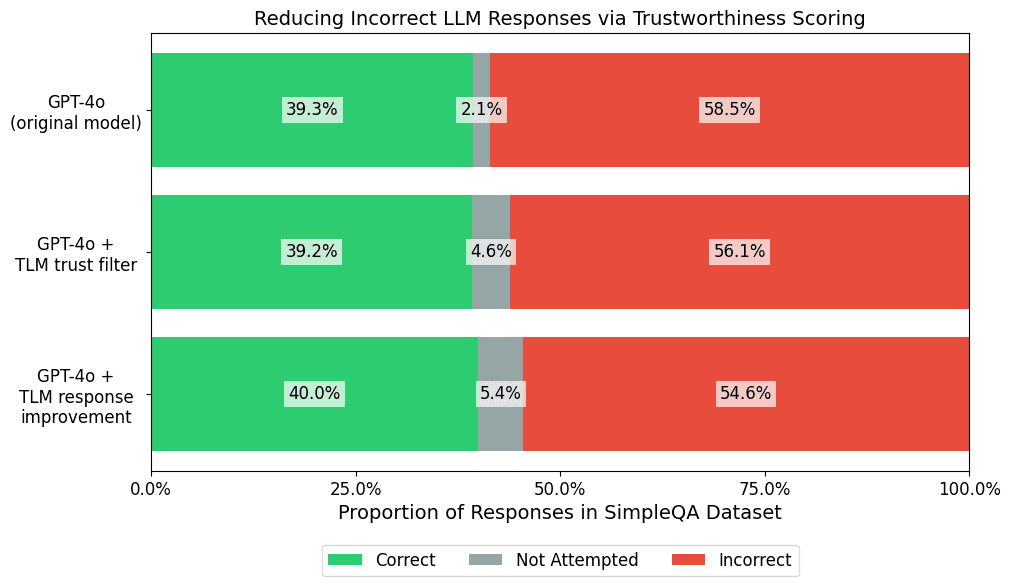
For 2.1% of the queries this challenging dataset, OpenAI’s GPT-4o model directly verbalizes “I don’t know” to not attempt an answer, yet the model still answers incorrectly for 58.5% of the queries. We used TLM’s real-time trustworthiness scoring to automatically flag an additional 2.4% of GPT-4o responses which we can override with a fallback “I don’t know” answer. It turns out over 95% of these flagged responses were originally incorrect (TLM only has access to the query and LLM response, no ground-truth). Beyond trustworthiness scoring, TLM also offers an automated response improvement capability, which further decreased the rate of incorrect responses from GPT-4o (without utilizing other LLMs or prompt alterations).
To reproduce our benchmark results, refer to our published code which mirrors OpenAI’s original SimpleQA benchmarking.
Reduce Hallucinations with Trustworthiness Filtering
To establish a baseline for the benchmark, we run OpenAI’s flagship model: GPT-4o. GPT-4o answers 39.3% of the queries correctly, 58.5% incorrectly, and did not attempt to answer the remaining 2.1%. While we ran OpenAI’s exact SimpleQA benchmarking code, the accuracy numbers we obtained vary slightly from OpenAI’s reported result due to inherent nondeterminism in LLM outputs.
In question-answering applications, one aims to maximize the number of correct LLM responses while minimizing incorrect ones. Beyond using better LLMs/prompts, incorrect responses can be reduced either by explicitly directing the model to not attempt to answer when it is unsure, or by overriding untrustworthy responses with a generic fallback answer. This appproach can be used to maintain high accuracy for questions with an attempted answer, ensuring that only confident answers are provided to users.
To automatically determine which responses are untrustworthy, we use the Trustworthy Language Model to score the trustworthiness of each LLM response. As the leading general-purpose real-time hallucination/error detection system, TLM can be powered using any LLM and assess responses from any LLM (or humans). Here we use a version of TLM powered by GPT-4o. For responses whose trustworthiness score fall below a threshold value of 0.25, we override them with a fallback response: “I’m sorry, I don’t know the answer to that question”.
This trustworthiness score filtering improves GPT-4o’s accuracy by increasing the Not Attempted response rate to 4.6%, while keeping the Correct response rate steady at 39.2% and reducing the Incorrect rate to 56.1%. This shows how automatically flagging untrustworthy responses can lower the risk of incorrect responses in LLM applications.
Automated Response Improvement with TLM
TLM offers various quality presets, including a best preset that utilizes trustworthiness scoring to automatically improve generated responses. We additionally benchmark this variant of TLM, still powered by GPT-4o as the sole LLM model involved in producing these results. We again apply trustworthiness score filtering with the same 0.25 threshold to defer to fallback responses in certain automatically-flagged cases. TLM’s automated response improvement increases the rate of correct responses to 40.0%, while further reducing the rate of incorrect responses down to 54.6%. These improvements are automatically achieved via the TLM system, without any changes in LLM model or prompts.
Limiting Incorrect Responses with a High Trustworthiness Threshold
High-stakes applications demand limiting the error-rate of LLM responses by having the model not attempt to answer as much as is necessary to maintain an acceptable accuracy. While SimpleQA is intentionally designed to be too challenging for today’s frontier LLMs, we can nonetheless explore just how much abstention would be required to achieve a low error-rate (say under 10%) in this benchmark. We additionally apply a stringent trustworthiness score threshold of 0.8 on GPT-4o responses, overriding those whose trustworthiness does not meet the threshold with our generic fallback.
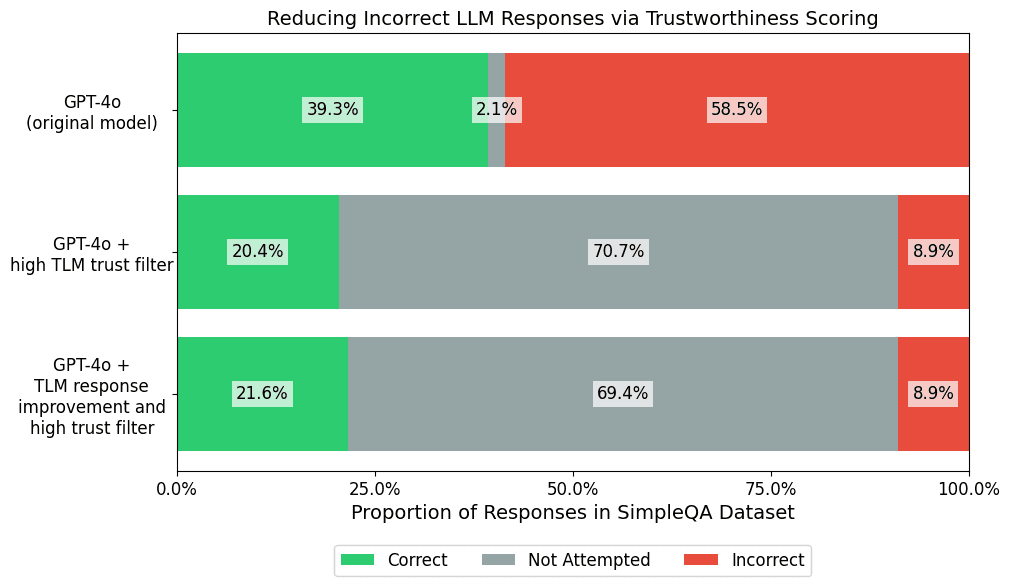
Using this stringent fallback filter dramatically reduces the rate of incorrect responses by over 84%, while reducing the rate of correct responses by under 50%. While achieving low error-rates for the challenging SimpleQA benchmark requires models to abstain too much to be useful, this section demonstrates a general recipe to achieve low LLM error-rates in applications where models are nearly production-ready.
Conclusion
These SimpleQA benchmarks demonstrate a general recipe to reduce incorrect responses in any LLM application. Use automated trustworthiness scoring to flag low-confidence responses and automated response improvement to boost accuracy. The Trustworthy Language Model offers a state-of-the-art system to accomplish this with any LLM model and build reliable AI applications.
Get started with the TLM API.