

Multi-label classification utilizes data where each example can belong to multiple (or none) of the K classes. One example of this could be an image of a face that is labeled with wearing_glasses and wearing_necklace as opposed to standard multi-class classification where each example has only one label. Ensuring high quality labels in multi-label classification datasets is really hard, as they often contain tons of tagging errors because annotating such data requires many decisions per example. In this article, we explore the challenges of multi-label data quality and demonstrate how to automatically identify and rectify problems with Cleanlab Studio, a no-code AI data correction tool.

Above are two examples from a variant of the famous CelebA multi-label dataset. The example on the left was labeled correctly, while the one on the right was given an incorrect label and is missing a correct label. Cleanlab Studio confirms the first example is correct while automatically detecting incorrect and missing labels and suggesting the additions for the second example.
It is quite common to find applications of multi-label data that stretch beyond the obvious. For instance, practical business applications like content moderation, document curation, and image tagging might require multiple labels or tags per example to enrich decision making and modeling efforts. Even a simple Yes/No survey can be formatted for multi-label classification. By considering each question as a distinct label and integrating features about the customer providing the responses, a single survey can present a myriad of data points.
How Does Multi-Label Differ from Multi-Class?

Multi-class classification: A single image belongs to exactly one of the classes – the classes are mutually exclusive.
Multi-label classification: A single image can belong to one or more classes simultaneously or none of the classes at all – the classes are not mutually exclusive (each class either applies to the image or not).
Let’s see how Cleanlab Studio can automatically identify the issues in your multi-label dataset – without you having to write any code at all! While this article considers image data, Cleanlab Studio can also analyze multi-label text and tabular datasets just as easily.
Using Cleanlab Studio to quickly improve the CelebA image tagging dataset
The CelebA multi-label dataset contains images of faces with associated labels like eyeglasses,wearing_earrings, wearing_necklace, no_beard, and smiling. Each of the images can have multiple labels depending on what is (not) present. Note that some of the labels are attributed to an example when there is an absence of something, like a beard. This means that if an image does NOT contain a beard, yet the labels don’t include no_beard, this can also be considered a mislabeled example. For multi-label datasets in general, “label errors” can be defined as a label that is present but incorrect or a label that is not present but should be for a specific example.
After creating a project with the “CelebA” dataset, Cleanlab Studio was able to automatically find:
- hundreds of missing and incorrect labels
- many possibly ambiguous examples
- a handful of outliers
Issues in CelebA
Let’s take a closer look at all of the issues listed above that Cleanlab Studio found automatically in the CelebA dataset.
Missing and Incorrect Labels
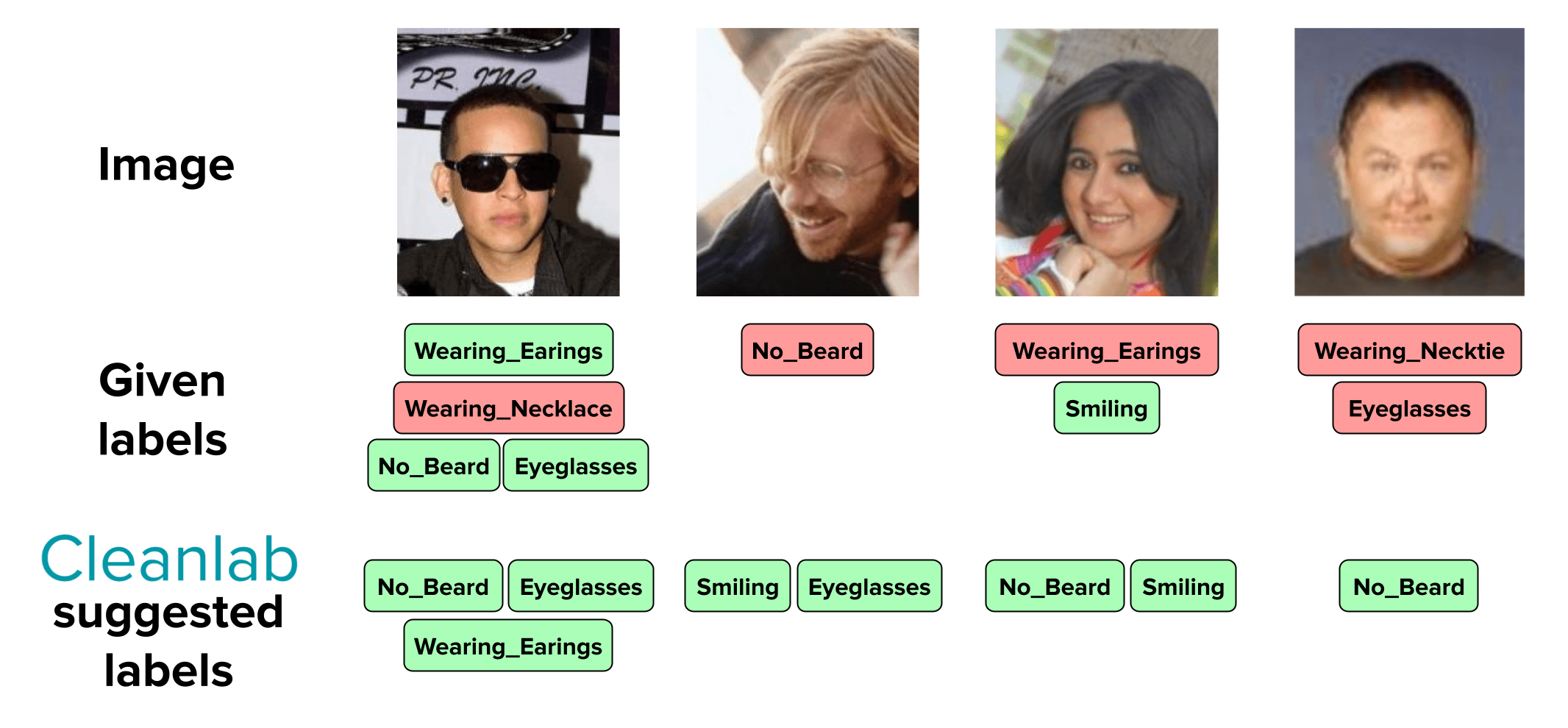
Here are mistagged images from the original CelebA dataset automatically detected by Cleanlab Studio. Can you see why each one is incorrect?
You can easily imagine how these issues would affect model training. Data inconsistencies like these lead to unreliable models, untrustworthy analytics, and harm downstream processes that rely on accurate information.
Ambiguous Examples

Another common issue in multi-label datasets is ambiguous examples. These are images that may or may not contain a given label. Oftentimes with human-labeled data, some may choose to include a given label while another annotator may not.
We can see in the example above that this person appears to not be smiling, but are we certain? Cleanlab Studio highlights these ambiguous examples so that you can decide how you want your data labeled ensuring consistency.
Outliers
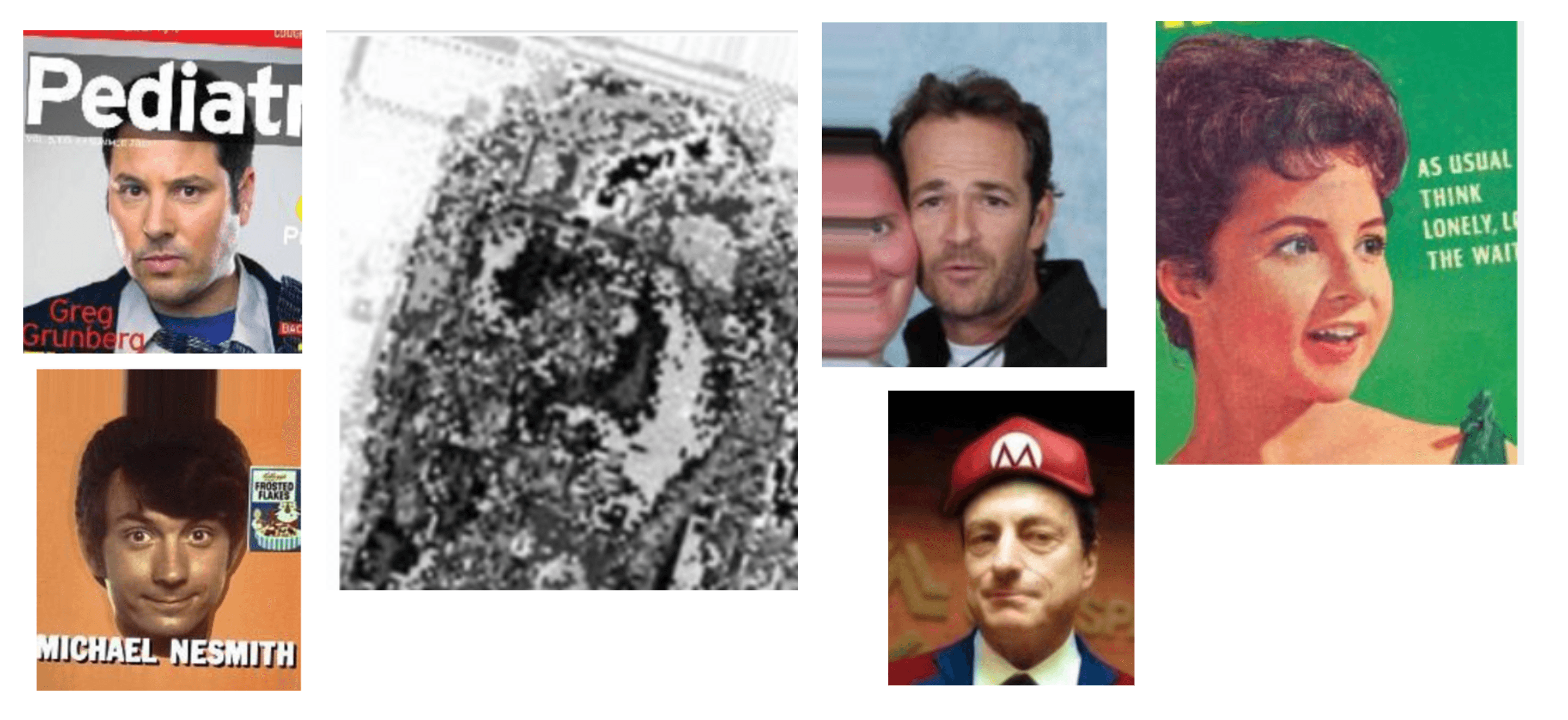
Outliers are images in your dataset that don’t belong and should be removed entirely. They can be introduced in many different ways like human-error or automated-scraping mistakes but regardless of how they made it into your data, they need to be removed to ensure optimal model training and performance.
These are a few examples that Cleanlab Studio marked as outliers. You can easily see that many of these “faces” should not have been included in the first place as they are distorted or pulled from printed media and should be removed. Others like the random gray image are not even recognizable and definitely should be removed.
No matter what the issue is, Cleanlab Studio provides you with all the information you need to curate higher-quality datasets.
Using Cleanlab Studio’s Multi-Label Interface
It only takes a few clicks for you to improve your data and train more robust models with Cleanlab Studio. Check out the detailed multi-label tutorial that explains everything you need to know.
Utilizing Your New Data
You can use the corrected multi-label dataset in place of your original dataset to produce more reliable machine learning and analytics without any change in your existing pipelines/code. Or with just a few clicks, you can deploy the cutting-edge ML that Cleanlab Studio originally used to audit your dataset to predict the tags of new data with high accuracy.
Next Steps
Data-centric AI tools like Cleanlab Studio can help you efficiently improve unreliable real-world data to build more robust models.
- Get started with Cleanlab Studio!
- Learn how to quickly improve the quality of your multi-label data (or how you can instantly train + deploy ML models for multi-label prediction/tagging)
- Read about the multi-label data quality algorithms pioneered by our Cleanlab scientists.
- Join our Community Slack to talk about your multi-label datasets and clarify any questions.
- Follow us on LinkedIn or Twitter for new techniques to systematically improve your data.