


cleanlab 2.0 is an open-source framework for machine learning and analytics with messy, real-world data. Based on research from MIT, cleanlab identifies errors in datasets, measures dataset quality, trains reliable models with noisy data, and helps curate quality datasets… each with just a few lines of code.


Cleanlab automates several such workflows to help you practice more data-centric AI. See these runnable tutorials.
The 80% of ML they don’t tell you about

Expectation:
- You spend your time learning cool insights from data, training models, and exploring advanced modeling techniques.
Reality:
- You spend your time cleaning data, because real-world data is messy and full of errors.
Data preparation is 80% of the work in data science and machine learning, and it’s cited as the most time-consuming and least enjoyable data science task. Bad data is a real problem: it costs US businesses trillions of dollars a year.
Why does bad data matter? Data errors (e.g., mislabeled examples in the training set) can reduce model performance, as can dataset-level issues like overlapping classes. Errors in test sets, common even in gold-standard benchmark datasets, can mislead data scientists into choosing inferior models for deployment. While exploring sophisticated modeling techniques sounds more enticing than manually inspecting and cleaning up individual datapoints, it is often the latter that provides a far greater payoff. cleanlab significantly reduces the pain in this process by automatically flagging only the small subset of the data that truly requires your attention.
cleanlab: towards automating the 80%
cleanlab helps data scientists and ML engineers with the 80% by providing a framework to streamline data-centric AI. cleanlab supports workflows for machine learning and analytics with messy real-world data by finding and fixing example-level, class-level, and dataset-level issues; measuring and tracking overall dataset quality; and providing cleaned data for machine learning pipelines.
The theory that powers cleanlab’s algorithms was inspired by quantum information theory while our CEO was doing his PhD research at MIT. Some of our users think cleanlab is black magic, but it’s mostly math and science published in top ML/AI conferences and journals.
Data scientists and engineers use cleanlab at companies like Google, Tesla, Amazon, Microsoft, Scale, and Uber to improve all modalities of datasets, including: tabular, text, image, and audio. Check out cleanlab on GitHub and start improving your own datasets in 5 minutes!
While cleanlab helps you automatically find data issues, an interface is needed to efficiently fix these issues your dataset. Cleanlab Studio finds and fixes errors automatically in a (very cool) no-code platform. Export your corrected dataset in a single click to train better ML models on better data. Try Cleanlab Studio at https://studio.cleanlab.ai/.
Workflows of data-centric AI
Here are a few examples of what cleanlab can do:
-
CleanLearning: clean learning = machine learning with cleaned data; train your model as if there are no errors in the dataset (in-depth tutorial)python -
find_label_issues: find and fix label issues (in-depth tutorial)python -
find_overlapping_classes: identify classes to consider merging (in-depth tutorial)python -
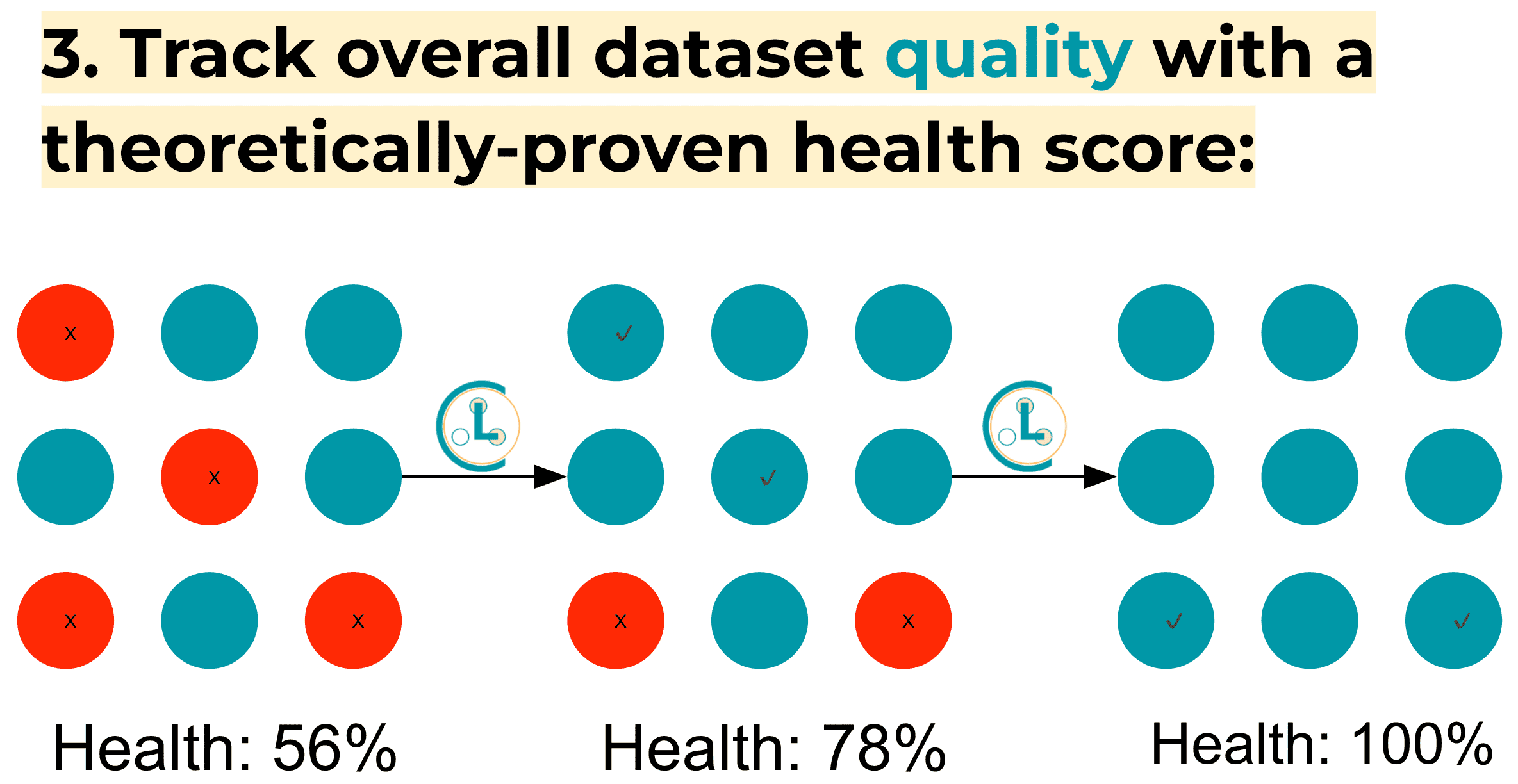
overall_label_health_score: get a single theoretically-proven health score to track overall dataset quality (in-depth tutorial)python
Testimonials
Cleanlab is well-designed, scalable and theoretically grounded: it accurately finds data errors, even on well-known and established datasets. After using it for a successful pilot project at Google, Cleanlab is now one of my go-to libraries for dataset cleanup.
— Patrick Violette, Senior Software Engineer at Google
We used Cleanlab to quickly validate one of our classifier models’ predictions for a dataset. This is typically a very time-consuming task since we would have to check thousands of examples by hand. However, since Cleanlab helped us identify the data points that were most likely to have label errors, we only had to inspect an eighth of our dataset to see that our model was problematic. We later realized that this was due to a post-processing error in the dataset — something that would otherwise have taken a much longer time to notice.
— Seah Bei Ying, Data Analyst at The Stakeholder Company
We explored the use of cleanlab to find label errors in speech recognition data and got promising results. I like the approach as it is driven by theory but also has the flexibility to adapt to specific domains.
— Dr. Niranjan Subrahmanya, Tech Lead at Google AI Speech
Resources
Check out all-new code, documentation, tutorials, and more for cleanlab 2.0:
- Join our Slack community
- Documentation, Tutorials, Examples, and Workflows
- Blog posts and publications
- Cleanlab Studio: no-code data improvement
If you’re coming from cleanlab 1.0, check out the migration guide and the v2.0.0 release notes.
Contributors
The following individuals contributed code for cleanlab 2.0: Curtis Northcutt, Jonas Mueller, Anish Athalye, Johnson Kuan, Wei Jing Lok, and Caleb Chiam.
We thank the individuals who contributed bug reports or feature requests. If you’re interested in contributing to cleanlab, check out our contributing guide!