

Cleanlab is an unusual startup. On paper we’re a few months old, but Cleanlab spun out of a decade (2013-2021) of my PhD research. The bulk of the foundational work was done at MIT with Isaac Chuang (the inventor of the first working quantum computer) — we rigorously and passionately invented a new field to solve a challenging problem in modern computing: automatically find and fix label errors in any dataset. Our approach was data-centric and our mission singular: make AI actually work reliably with noisy, real-world data and labels.
A decade later, I co-founded Cleanlab with two of my close MIT friends who inspire me every day. My friend and Cleanlab’s Chief Scientist, Jonas Mueller, did his PhD at MIT in CS/ML. Jonas built Amazon AWS’s auto-ML solution, led their open-source, and published tens of papers in top machine learning venues. My other friend and Cleanlab’s CTO, Anish Athalye, is finishing his PhD at MIT in CS/Systems. Anish has over 30,000 stars across his GitHub projects, won the best paper award at ICML 2018 (even though his field isn’t ML), has taught lectures with half a million views on YouTube, and runs a fantastic blog. I am honored to be their co-founder and CEO.
The caliber of our founding team is a humbling reminder that we must use our roles at Cleanlab to create something good for the world. The privilege to work together is a rare opportunity. We must be sure not to do less than anyone else would if they had the same opportunity.
In this post, I share how Cleanlab went from a graduate research project to a company with tech used by Google, Tesla, Amazon, Microsoft, Scale, Uber, and engineers and data scientists at companies around the world; where we are today; and the future we are building.
The History: A decade climb to Cleanlab
Our vision to make AI work for people and their messy, real-world data is inspired by experiences from our history. Here are some of the steps that got us to where we are today:
2013-2016

- I built MIT and Harvard’s cheating detection system for their online courses and found tens of thousands of label errors (course certificates earned by cheating), ultimately banning thousands and validating hundreds of thousands of edX certificates.
- I spent time at Microsoft Research India identifying cheating at scale in their online courses.
- It turned out we could not train machine learning models to detect cheaters because the labels were too noisy.
- Originally motivated by the goal of democratizing education, but blocked by these noisy labels, I started building the first version of what would later become cleanlab to validate cheating labels. I started to see how Cleanlab could empower AI to work with real-world data to solve human-centric AI problems that previously seemed unsolvable.
2016

- That summer, I worked in Yann LeCun’s group in NYC at FAIR (Facebook AI Research) where I automated the correction of biased label errors in comment rankings on facebook.com.
- I saw first-hand the negative impact of messy, human data on ranking algorithms for billions of comments and the lack of an enterprise solution for dealing with label errors.
2017
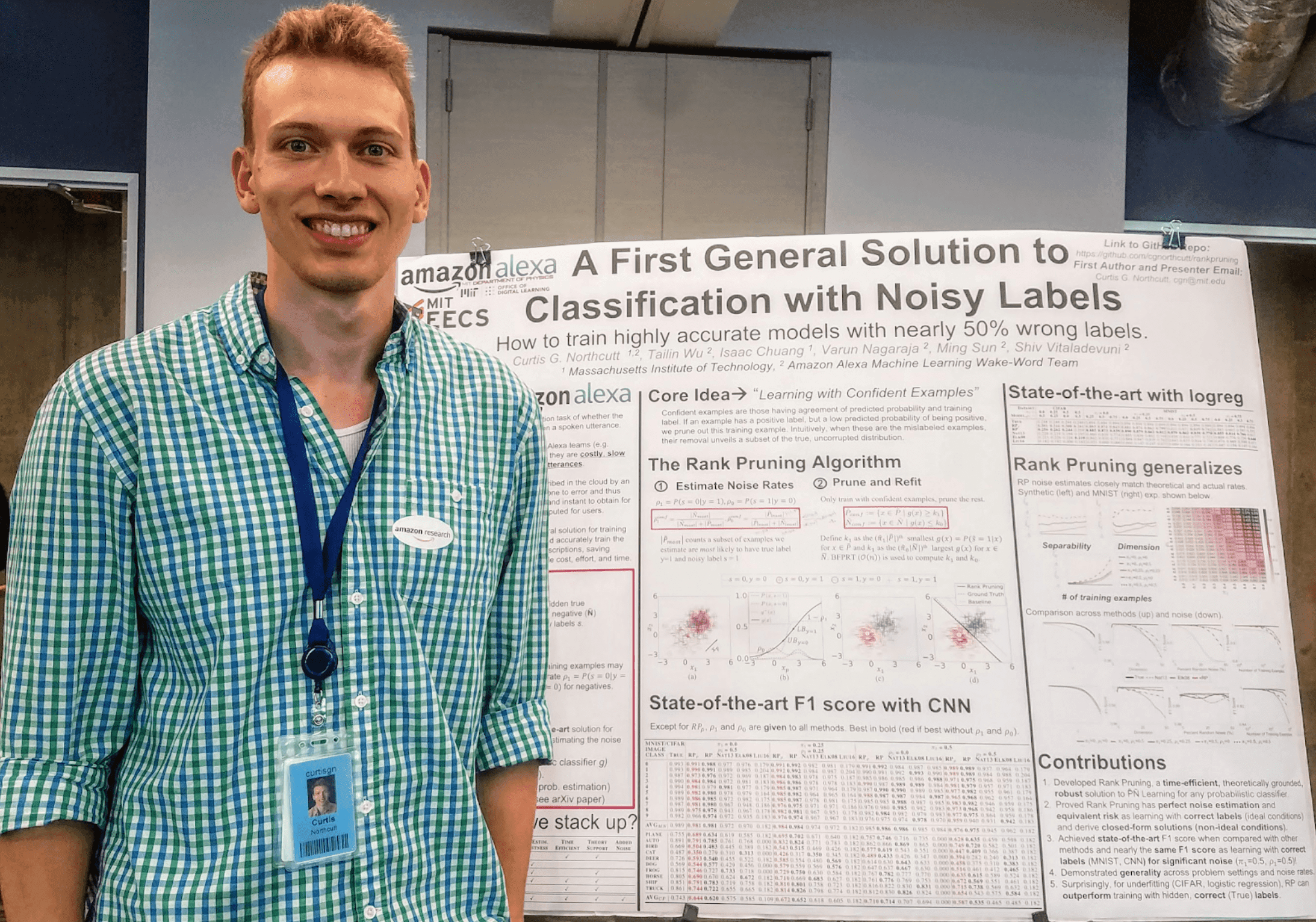
- I spent the summer working in the Alexa AI group at Amazon using cleanlab algorithms to quantify how frequently Alexa devices don’t wake up even though you said ‘Alexa’.
- I saw how Cleanlab tech helped Amazon measure and improve the false negative rates for a device used by hundreds of millions of people.
2018-2020

- I created Oculus Research’s first embodied AI conversations dataset (video, audio, and text transcripts). I open-sourced the data and published some neat things you can do with it.
2019

- I integrated cleanlab into Google’s code base and used it to provide cleaned data to train their ‘Hey Google’ and ‘OK Google’ models across millions of samples and 50+ languages.
- I saw the importance of Cleanlab for Google when working with massive datasets too large to check by hand, even for a team of hundreds of employees.
2020
- I co-founded ChipBrain and used the cleanlab open-source repo to improve and more-accurately label their large-scale emotion dataset.
- Using this dataset, we trained one of the world’s most accurate emotion detection models.
2021
- In late 2021, we incorporated Cleanlab Inc.
- Working with Cleanlab co-founders Jonas and Anish, we launched labelerrors.com.
- We showed that using cleanlab, you can find millions of label errors in the 10 most commonly used datasets in machine learning.
- We published this in NeurIPS 2021 and we were nominated for best paper.
- Our work was featured in several news outlets.
- I ended the year with an invited talk about Cleanlab at NeurIPS (the premier conference in machine learning) during Andrew Ng’s Data-centric AI workshop.
2022
- Over the past year, dozens of tech, healthcare, finance, and data-related companies (e.g. Tesla, JP Morgan, Chase, Microsoft, etc.) have started to use cleanlab:

How Cleanlab makes AI work for real-world data
Cleanlab might be based on fancy PhD research, but it’s actually pretty easy to understand.
Imagine you’re learning English by looking at pictures of objects while a teacher tells you the corresponding English word, but 10% of the time, they teach you the wrong word! So, sometimes your teacher shows you a “dog”, but calls it a “pencil” — this happens (a lot) in real-world data. That’s where Cleanlab comes in. Cleanlab lets you (the ML model) rewind time, find the times when the teacher made mistakes, and remove/fix them so it’s as if you had a teacher who makes considerably fewer mistakes. cleanlab provides clean labels.
If you have several teachers (annotators), Cleanlab tells you which ones make the most mistakes. We also provide a label quality score for every example and data quality score for every dataset. We automatically rank every example so you know which data is the hardest to learn from, which are most likely to be mislabeled, and which data don’t belong in your dataset.
Some of our users think that cleanlab is black magic, but it’s mostly math and a little science published in top peer-reviewed conferences and journals in machine learning and AI.
The theory behind Cleanlab took inspiration from quantum information
During my PhD at MIT, I was advised by my mentor and friend, Isaac Chuang. You may have heard of Ike: he invented the first working quantum computer and co-authored “the book” on quantum computation and information theory. Ike is one of our technical advisors at Cleanlab.
One of the pitfalls of NMR quantum computing is that information is perturbed by a noisy channel (a process that flips information bits) making scaling multiple qubits challenging. We realized that we can view label errors in datasets similarly — it’s just information that has been perturbed. If we can uncover the noisy channel (the conditional matrix of flipping rates from every label to every other label) then we can reverse engineer the data to uncover clean data from noisy data. And that’s exactly what we did. You can read more about the underlying algorithms and theory of Cleanlab in the confident learning paper.
Why open-source?
At Cleanlab, we believe in free dissemination of ideas and information, including code, which is why we make all our research contributions public and open-access, including algorithms, code, and datasets.
I open-sourced the first version of cleanlab back in 2017 and not purely for altruistic reasons. It was necessary… to convince the world that we could do something that hadn’t been done before. When I shared the initial theory of Cleanlab at UAI, I was met with skepticism, “How can you automatically find label errors in image, text, audio, and tabular datasets in a few lines of code? Sounds impossible.” I responded by open-sourcing the code. I found a ton of bugs at first, but after several iterations, a reliable tool emerged.
We’ve come a long a way since 2017. Today, anyone can use cleanlab to automatically improve the quality of their data for free at https://github.com/cleanlab/cleanlab. It works with multi-label or single-labeled data, with almost any dataset or model.
The Present: Where we are Today
I created the first version of Cleanlab to make AI work for people and their messy, human data in an effort to democratize education. It turned out most tech companies struggle with label quality, but no enterprise solution existed. Today, Cleanlab fills that gap. Our (incredible) team has quadrupled in size over the last half year and continues to grow quickly.
Our mission at Cleanlab is to make AI work for people and their messy, real-world data. AI has the potential to empower humanity more than any prior technology. But AI algorithms were created assuming perfect labels and data, not messy, human, real-world data. So, most of the work required for AI to fulfill its promise ends up being curating, cleaning, and preparing data.
Today, Cleanlab automates that work for you. You can sign up for Cleanlab Studio, our no-code automated enterprise AI platform for data correction, 👉 here.
The Future: A world where AI works for people
A startup founder can’t tell you their company’s future with precision. If they could, they should probably switch to venture capital. Instead, I’ll share a future that is possible with Cleanlab.
I envision a future where AI can fulfill its promise to empower humanity, even though human data is messy. One where medical practitioners can trust machine learning models to make reliable diagnoses by using Cleanlab to train on cleaned data. Where data and label quality issues across healthcare, manufacturing, online education, and other human-centric industries are flagged and corrected in real-time by Cleanlab. Bad data costs U.S. businesses $3.1 trillion per year and growing. We’re reversing that trend and building a world where your time is spent solving the problems you care about, not fighting data quality issues. A world where AI actually works for people and their real-world, messy data. That’s day one at Cleanlab.
An academic perspective on Cleanlab’s journey and future is considered in the confident learning thesis (Chapter 8).
Interested in Cleanlab?
-
Sign up here for Cleanlab Studio, our no-code AI platform for automated data and label correction.
-
If you are interested in building AI Assistants connected to your company’s data sources and other Retrieval-Augmented Generation applications, reach out to learn how Cleanlab can help.
-
Use Cleanlab Open-Source for free: https://github.com/cleanlab/cleanlab.
-
About us: https://cleanlab.ai/about.
-
Build the future of data-centric AI with us at: https://cleanlab.ai/careers
ABOUT THE AUTHOR
Curtis Northcutt is the Co-Founder and CEO of Cleanlab, an open-source data quality company that makes AI work with real-world, messy data. Curtis was born and raised in rural Kentucky. His father, grandfather, and great-grandfather were postal workers and his mother worked low-wage jobs in the service industry. After graduating valedictorian at Vanderbilt (2013), Curtis completed his PhD at MIT (2021) where he invented Cleanlab’s algorithms for automatically finding and fixing label issues in any dataset. He is the recipient of the MIT Morris Levin Thesis Award, the NSF Fellowship, and the Goldwater Scholarship and has worked at several leading AI research groups, including Google, Oculus, Amazon, Facebook, Microsoft, MIT Lincoln Lab, and NASA.