

cleanlab 2.1 is a leap forward toward a standard open-source framework for Data-Centric AI that can be used by engineers and data scientists in diverse applications. cleanlab 2.1 extends cleanlab beyond classification with label errors to several new data-centric ML tasks including:
- Analysis of data labeled by multiple annotators
- Out of distribution detection
- Label error detection in token classification (NLP) tasks
CleanLearning for finding label issues and training robust ML models on datasets with label errors now works out-of-the-box with many data formats including pandas/pytorch/tensorflow datasets. Often in one line of code, CleanLearning enables dozens of data-centric AI workflows with almost any model and data format – an example using HuggingFace Transformers, Keras, and Tensorflow datasets is available here.

Advancing open-source Data-Centric AI:
Two newsworthy aspects of this release:
- cleanlab 2.1 is the most effective Python package to analyze multi-annotator (crowdsourcing) data for annotator and label quality (paper forthcoming).
- cleanlab has grown quickly over the last year. cleanlab is the first tool that detects data and label issues in most supervised learning datasets, including: image, text, audio, and token classification. cleanlab 2.1 is also useful for other core data-centric tasks like: out of distribution detection, dataset curation, and robust learning with noisy labels.
Major new functionalities added in 2.1:
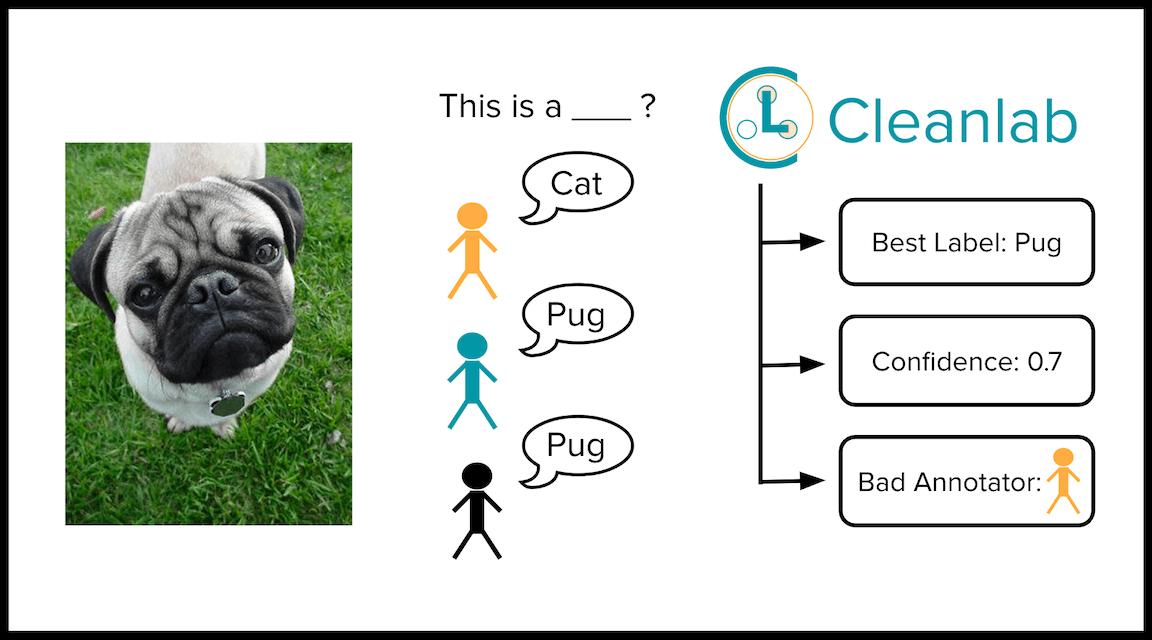
- CROWDLAB algorithms for analyzing data labeled by multiple annotators to:
- Accurately infer the best consensus label for each example in your dataset
- Estimate the quality of each consensus label (how likely is it correct)
- Estimate the quality of each annotator (how trustworthy are their suggested labels)
- Out of Distribution Detection based on either:
- Feature values/embeddings
- Predicted class probabilities
- Label error detection for Token Classification
- Supports NLP tasks like entity recognition
- CleanLearning can now:
- Run on non-array data types including: pandas Dataframe, pytorch/tensorflow Datasets
- Utilize any Keras model (supporting sequential and functional APIs)
Other developer-focused improvements:
- Added an FAQ with advice for common questions
- Added many additional tutorial and example notebooks at: docs.cleanlab.ai and github.com/cleanlab/examples
- Reduced dependencies: e.g.
scipyis no longer needed
Code Examples and New Workflows in cleanlab 2.1:
1. Detect out of distribution examples
Detect out of distribution examples in a dataset based on its numeric feature embeddings

Detect out of distribution examples in a dataset based on predicted class probabilities from a trained classifier
2. Multi-annotator data
For data labeled by multiple annotators (stored as matrix multiannotator_labels whose rows correspond to examples, columns to each annotator’s chosen labels), cleanlab 2.1 can: find improved consensus labels, score their quality, and assess annotators, all by leveraging predicted class probabilities pred_probs from any trained classifier.
3. Entity Recognition and Token Classification
cleanlab 2.1 can now find label issues in token classification (text) data, where each word in a sentence is labeled with one of K classes (eg. entity recognition).
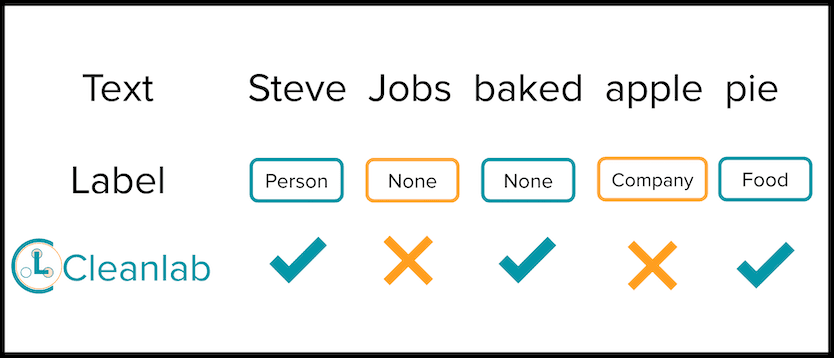
Example inputs (for dataset with K=2 classes) might look like this:
Running this code on the CoNLL-2003 named entity recognition dataset uncovers many label errors, such as the following sentence:
Little change from today’s weather expected.
where Little is wrongly labeled as a PERSON entity in CoNLL.
4. CleanLearning can now operate directly on non-array dataset formats like tensorflow/pytorch datasets and use Keras models
More details in the official release notes.
Beyond cleanlab v2.1
While cleanlab 2.1 finds data issues, an interface is needed to efficiently fix these issues your dataset. Cleanlab Studio finds and fixes errors automatically in a (very cool) no-code platform. Export your corrected dataset in a single click to train better ML models on better data.
Try Cleanlab Studio at https://studio.cleanlab.ai/.
Learn more about Cleanlab
- How Google, Tencent, and others use Cleanlab.
- Step-by-step tutorials to find issues in your data and train robust ML models:
- Image | Text | Audio | Outliers | Dataset Curation | Multi-annotator Data
- Ways to try out Cleanlab:
- Open-source: GitHub
- No-code, automatic platform (easy mode): Cleanlab Studio
- Documentation | Blogs | Research Publications | Cleanlab History | Team
Join our community of scientists and engineers to help build the future of open-source Data-Centric AI: Cleanlab Slack Community
Contributors
A big thank you to the data-centric jedi who contributed code for cleanlab 2.1 (in no particular order): Aravind Putrevu, Jonas Mueller, Anish Athalye, Johnson Kuan, Wei Jing Lok, Caleb Chiam, Hui Wen Goh, Ulyana Tkachenko, Curtis Northcutt, Rushi Chaudhari, Elías Snorrason, Shuangchi He, Eric Wang, and Mattia Sangermano.
We thank the individuals who contributed bug reports or feature requests. If you’re interested in contributing to cleanlab, check out our contributing guide!