

Guess what? The Fashion MNIST Dataset (cited in 2000+ papers) contains hundreds of erroneous label and data issues found using Cleanlab Studio — an automated solution to find and fix data issues using AI. This Cleanlab Studio Audit (CSA) is our way to inform the community about issues in popular datasets.
Understanding these issues helps you improve the quality of your data, which for dataset analyzed in this article, directly benefits product categorization and product identification efforts common in e-commerce analytics and business intelligence.
Product Classification with the Fashion MNIST Dataset
Below the first two images are correctly labeled examples (randomly chosen from the dataset) while the latter two are images that Cleanlab Studio automatically identified as mislabeled (also suggesting a more appropriate label to use instead).

Cleanlab Studio suggested the t-shirt/top label to more than 100 images labeled as shirt, and suggested the dress label to more than 40 images labeled as shirt. The t-shirt/top class encompases both t-shirts and tops, so mislabeling images of this class as shirt can lead to inconsistent model training.
Miscategorized Items
Apart from apparel images, Cleanlab Studio also found several footwear images annotated with the incorrect category. We show two examples where a sneaker and an ankle boot are mislabeled. We also show the correctly labeled images for each class. Cleanlab Studio automatically identified the incorrectly labeled examples and suggested the correct label.
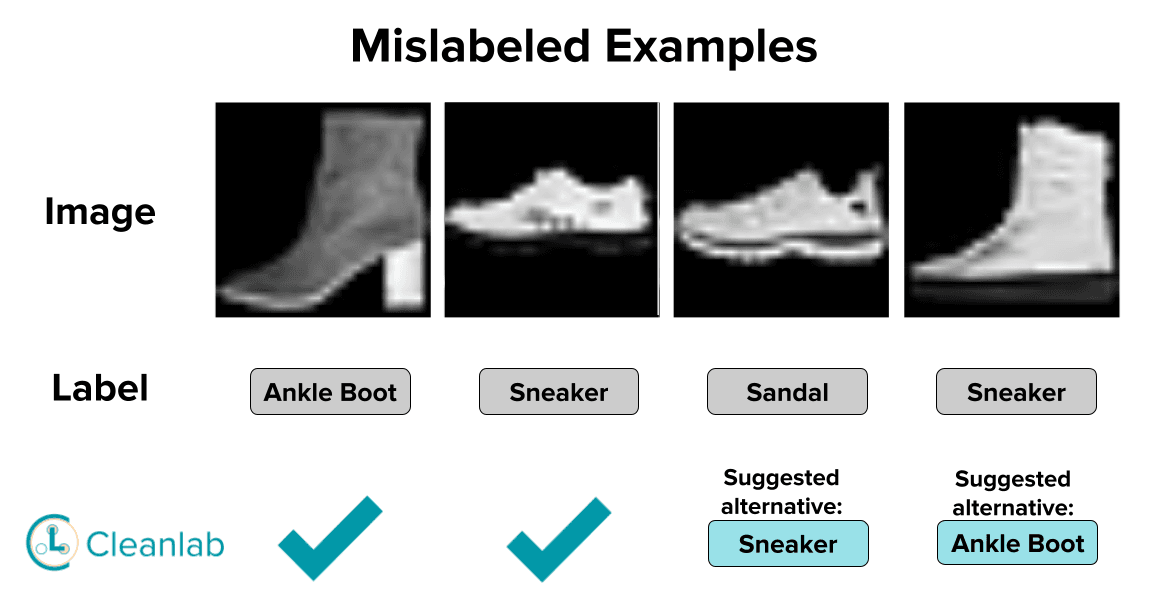
Though there are fewer mislabeled footwear-type images in comparison to apparel-type images, the quality of the dataset and the predictions of a trained classifier can be improved by correcting these labels.
Ambiguous Examples and Outliers
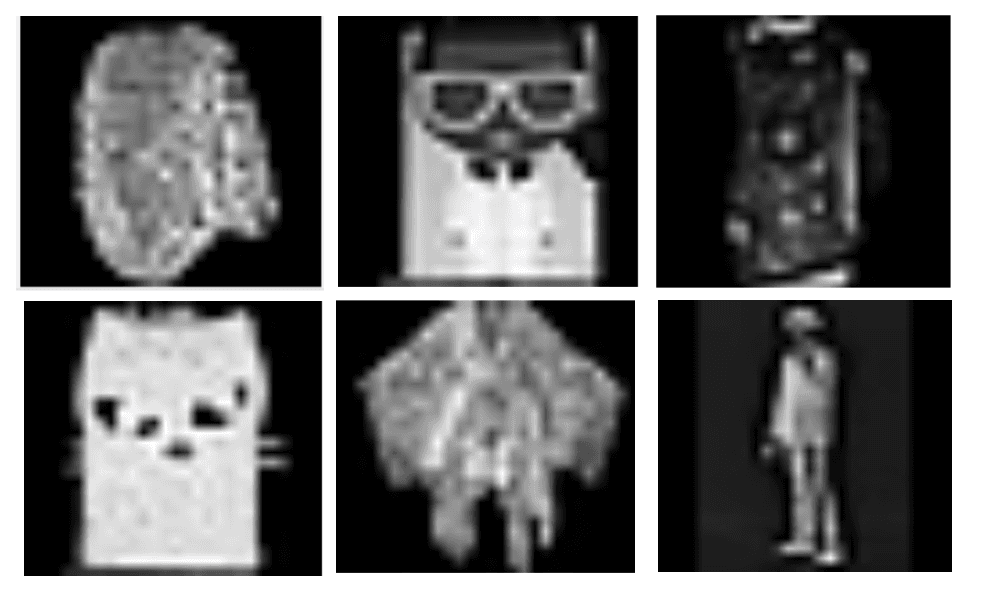
Sometimes images aren’t just mislabeled, they should be removed from the dataset entirely as they do not belong to any of the classes of interest. In this dataset, Cleanlab Studio automatically detects many images that are outliers and are too ambiguous to be labeled as any of the classes.
Fix data with Cleanlab Studio
Clearly, these data errors detected by the AI in Cleanlab Studio could be detrimental to your modeling and analytics efforts. It’s important to know about such errors in your data and correct them, in order to train the best models and draw the most accurate conclusions.
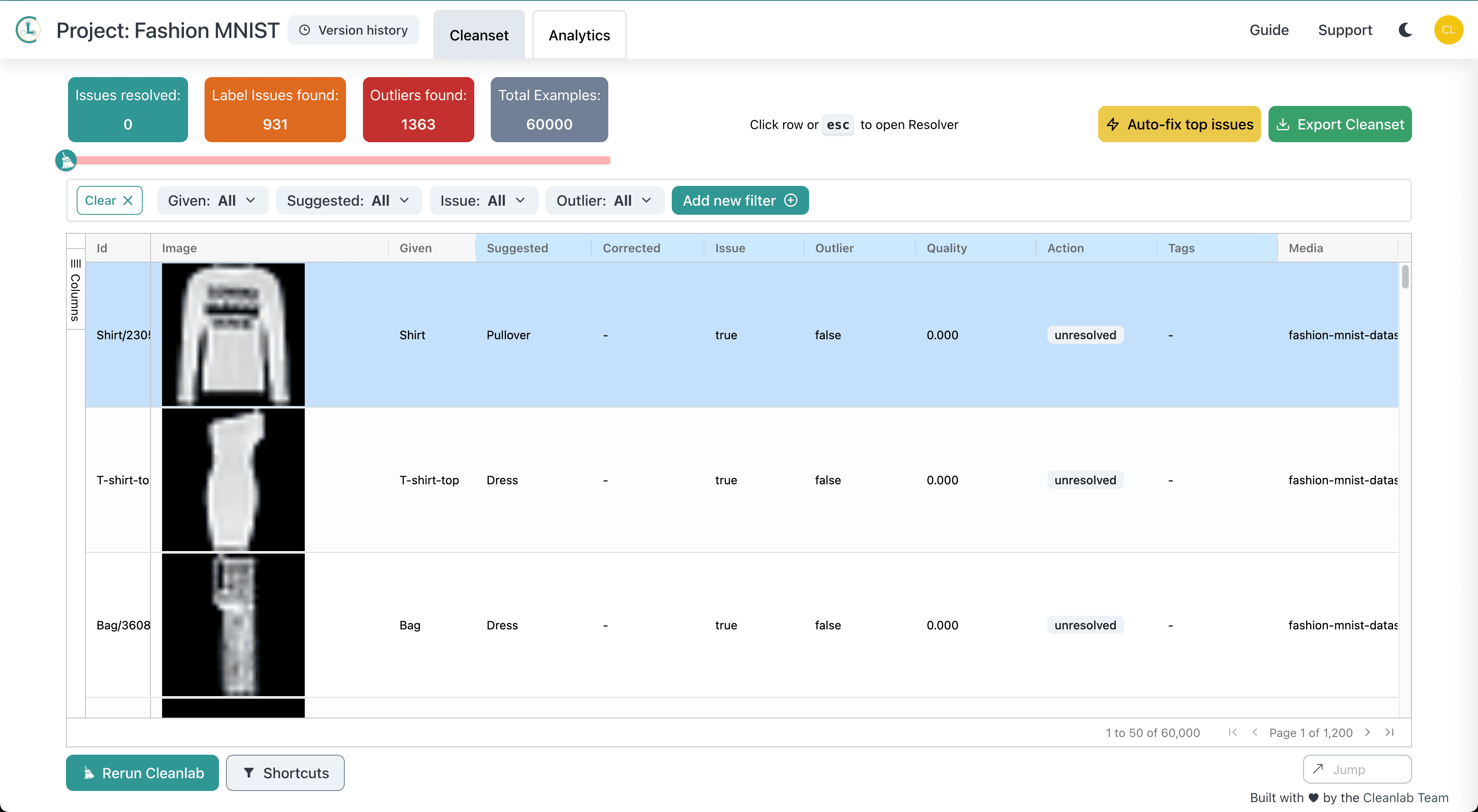
To find & fix such issues in almost any dataset (text, image, table/CSV/Excel, etc), just run it through Cleanlab Studio. Try this no-code Data-Centric AI tool for free!
Want to get featured?
We would like to send a huge thank you to Ganesh Tata for using Cleanlab Studio to find all of these issue in Fashion MNIST!
If you’ve found interesting issues in any dataset, your findings can be featured in future CSAs just like Ganesh! Just fill out this form.