

This article surveys Evaluation models to automatically detect hallucinations in Retrieval-Augmented Generation (RAG), and presents a comprehensive benchmark of their performance across six RAG applications. While hallucination sometimes refers to specific types of LLM errors, we use this term synonymously with incorrect response (i.e. what matters to users of your RAG system). Code to reproduce our benchmark is available here.
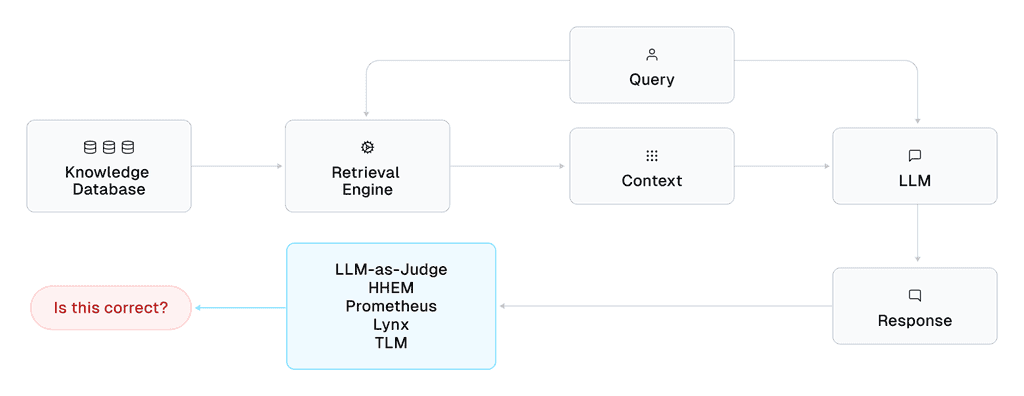
Retrieval-Augmented Generation enables AI to rely on company-specific knowledge when answering user requests. While RAG reduces LLM hallucinations, they still remain a critical concern that limits trust in RAG-based AI. Unlike traditional Search systems, RAG systems occasionally generate misleading/incorrect answers. This unreliability poses risks for companies that deploy RAG externally, and limits how much internal RAG applications get used.
Real-time Evaluation Models offer a solution, by providing a confidence score for every RAG response. Recall that for every user query: a RAG system retrieves relevant context from its knowledge base and then feeds this context along with the query into a LLM that generates a response for the user. Evaluation models take in the response, query, and context (or equivalently, the actual LLM prompt used to generate the response), and then output a score between 0 and 1 indicating how confident we can be that the response is correct. The challenge for Evaluation models is to provide reference-free evaluation (i.e. with no ground-truth answers/labels available) that runs in real-time.
Popular Real-Time Evaluation Models
LLM as a Judge
LLM-as-a-judge (also called Self-Evaluation) is a straightforward approach, in which the LLM is directly asked to evaluate the correctness/confidence of the response. Often, the same LLM model is used as the model that generated the response. One might run LLM-as-a-judge using a Likert-scale scoring prompt.
The main issue with LLM-as-a-judge is that hallucination stems from the unreliability of LLMs, so directly relying on the LLM once again might not close the reliability gap as much as we’d like. That said, simple approaches can be surprisingly effective and LLM capabilities are ever-increasing.
HHEM
Vectara’s Hughes Hallucination Evaluation Model (HHEM) focuses on factual consistency between the AI response and retrieved context. Here we specifically consider HHEM version 2.1. This model’s scores have a probabilistic interpretation, where a score of 0.8 indicates an 80% probability that the response is factually consistent with the context.
These scores are produced by a Transformer model that Vectara trained to distinguish between hallucinated vs. correct responses from various LLMs over various context/response data. More specifically, this model processes (premise, hypothesis) inputs and outputs a score.
In our study, including the question within the premise improved HHEM results over just using the context alone.
Prometheus
Prometheus (specifically the recent Prometheus 2 upgrade) is a fine-tuned LLM model that was trained on direct assessment annotations of responses from various LLMs over various context/response data. This model is available in various sizes, such as 7B and 8 x 7B (mixture of experts), which are fine-tunes of Mistral models. Here we focus on the Prometheus2 8x7B (mixture of experts) model, as the authors reported that it performs better in direct assessment tasks. One can think of Prometheus as an LLM-as-a-judge that has been fine-tuned to align with human ratings of LLM responses.
The instruction in the above prompt template expects both the context and the question which is prepared by concatenating the retrieved context and the query strings:
In addition to a prompt template, Prometheus also requires a scoring rubric. This model is trained to work best with a 5-point Likert scale. In our study, we used the original scoring rubric format recommended by the Prometheus developers, and minimally modified the descriptions of each rating to suit each RAG use-case.
Patronus Lynx
Like the Prometheus model, Lynx is a LLM fine-tuned by Patronus AI to generate a PASS/FAIL score for LLM responses, trained on datasets with annotated responses. Lynx utilizes chain-of-thought to enable better reasoning by the LLM when evaluating a response. This model is available in 2 sizes, 8B and 70B, both of which are fine-tuned from the Llama 3 Instruct model. Here we focus on the Patronus-Lynx-70B-Instruct model because it outperforms the smaller 8B variant in our experiments.
This model was trained on various RAG datasets with correctness annotations for responses from various LLMs. The training datasets included CovidQA, PubmedQA, DROP, FinanceBench, which are also present in our benchmark study. In our benchmark, we omit Lynx results for these datasets that it already saw during its training.
Trustworthy Language Model (TLM)
Unlike HHEM, Prometheus, and Lynx: Cleanlab’s Trustworthy Language Model (TLM) does not involve a custom-trained model. The TLM system is more similar to LLM-as-a-judge in that it can utilize any LLM model, including the latest frontier LLMs as soon as they are released. TLM is a wrapper framework on top of any base LLM that uses an efficient combination of self-reflection, consistency across sampled responses, and probabilistic measures to comprehensively quantify the trustworthiness of a LLM response.
Unlike the other Evaluation models, TLM does not require a special prompt template. Instead you simply use the same prompt you provided to your RAG LLM that generated the response being evaluated.
Benchmark Methodology
To study the real-world hallucination detection performance of these Evaluation models/techniques, we apply them to RAG datasets from different domains. Each dataset is composed of entries containing: a user query, retrieved context that the LLM should rely on to answer the query, a LLM-generated response, and a binary annotation whether this response was actually correct or not.
Unlike other RAG benchmarks that study finer-grained concerns like retrieval-quality, faithfulness, or context-utilization, we focus on the most important overall concern in RAG: how effectively does each detection method flag responses that turned out to be incorrect. This is quantified in terms of precision/recall using the Area under the Receiver Operating Characteristic curve (AUROC). A detector with high AUROC more consistently assigns lower scores to RAG responses that are incorrect than those which are correct. Note that none of our Evaluation models/techniques relies on the correctness-annotations, these are solely reserved for reporting the AUROC achieved by each scoring method.
We run all methods at default recommended settings from the corresponding libraries. Recall that both LLM-as-a-judge and TLM can be powered by any LLM model; our benchmarks run them with OpenAI’s gpt-4o-mini LLM, a low latency/cost solution. If a scoring method failed to run for one or more examples in any dataset (due to software failure), we indicate this by a dotted line in the graph of results.
We report results over 6 datasets, each representing different challenges in RAG applications. Four datasets stem from the HaluBench benchmark suite (we omitted the remaining datasets in this suite after discovering prevalent annotation errors within them). The other two datasets, FinQA and ELI5, cover more complex settings.
Benchmark Results
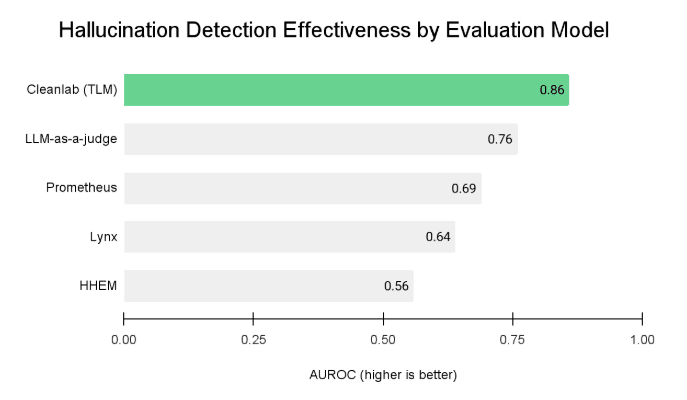
Here is an aggregated summary of the overall benchmark results. In the subsequent sections, we describe each benchmark dataset along with its corresponding results.
FinQA
FinQA is a dataset of complex questions from financial experts pertaining to public financial reports, where responses stem from OpenAI’s GPT-4o LLM in the version of this dataset considered here. The documents/questions in this dataset can be challenging even for humans to accurately answer, often requiring careful analysis of multiple pieces of information in the context and properly combining these pieces into a final answer (sometimes requiring basic arithmetic).
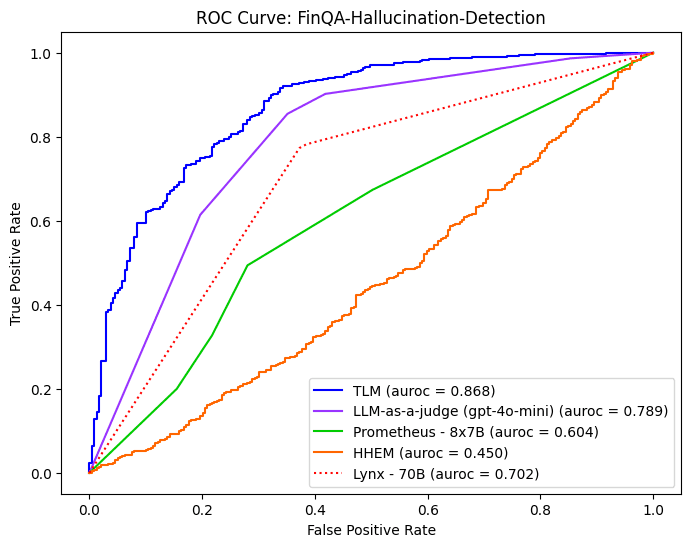
In this benchmark, almost all Evaluation models are reassuringly able to detect incorrect AI responses better than random chance (which would be AUROC = 0.5). Note that is far from guaranteed, given these methods must run in real-time without access to any annotations, ground-truth answers, or other extra information.
For FinQA, TLM and LLM-as-a-judge detect incorrect AI responses with the highest precision and recall. This may be due to the sophisticated nature of the questions/context, which custom trained models may not grasp as well as the OpenAI LLM we used to power TLM and LLM-as-a-judge in this benchmark.
ELI5
ELI5 is a dataset that captures the challenge of breaking down complicated concepts into understandable/simplified explanations without sacrificing accuracy. Here we use a subset of ELI5 dataset, where LLM responses were annotated as to their correctness. Responses that are annotated as incorrect exhibit issues such as: factual errors or misrepresentations, oversimplifying to the extent that inaccuracies are introduced, or making claims that are not supported by the retrieved context.
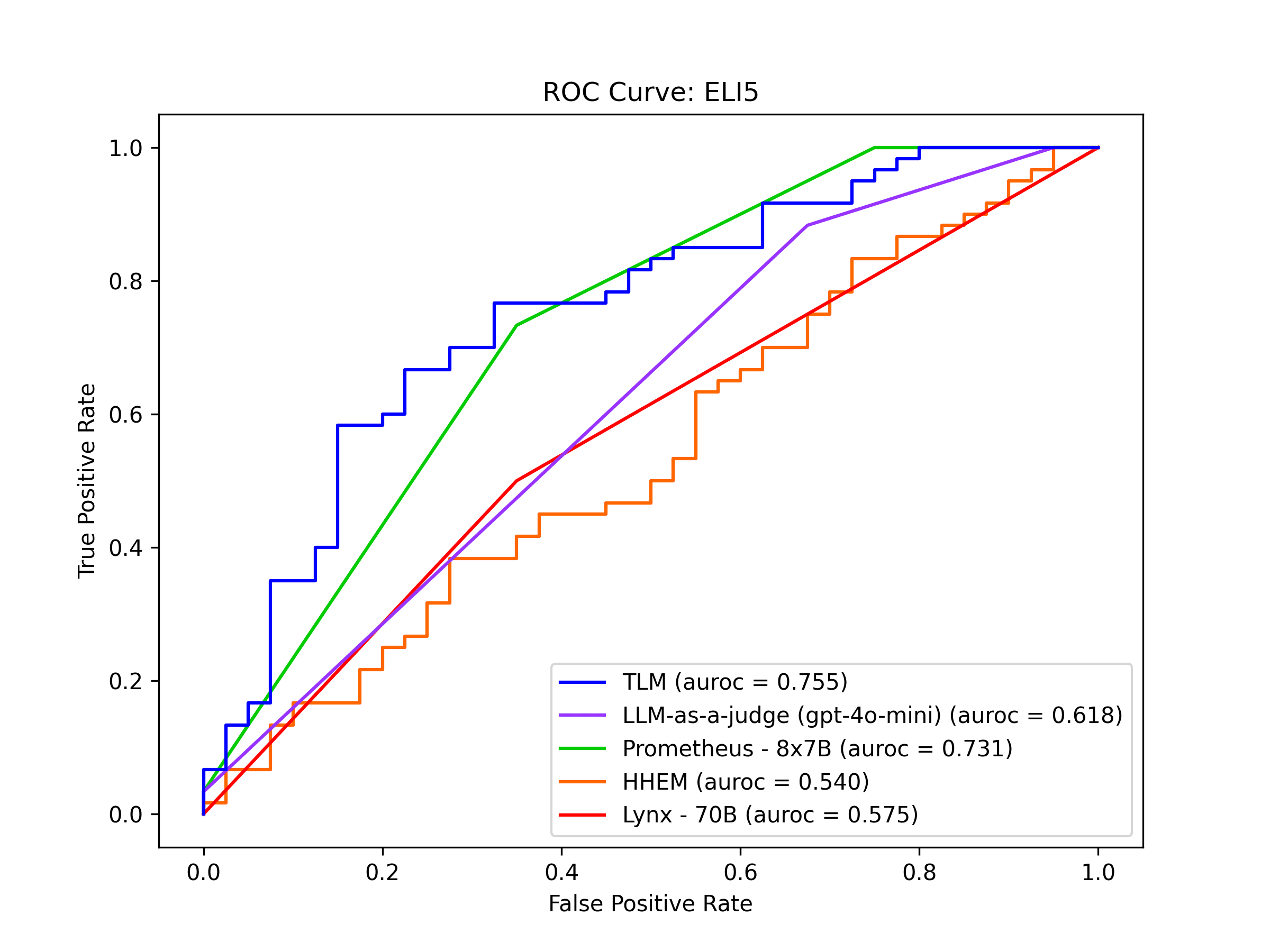
In this benchmark, no method manages to detect incorrect AI responses with very high precision/recall, but Prometheus and TLM are more effective than the other detectors.
FinanceBench
FinanceBench is a dataset reflecting the types of questions that financial analysts answer day-to-day, based on public filings from publicly traded companies including 10Ks, 10Qs, 8Ks, and Earnings Reports. Retrieved contexts contain financial documents of a company and the questions asked are clear-cut & straightforward to answer by reading relevant context (unlike FinQA where answers often require non trivial reasoning).
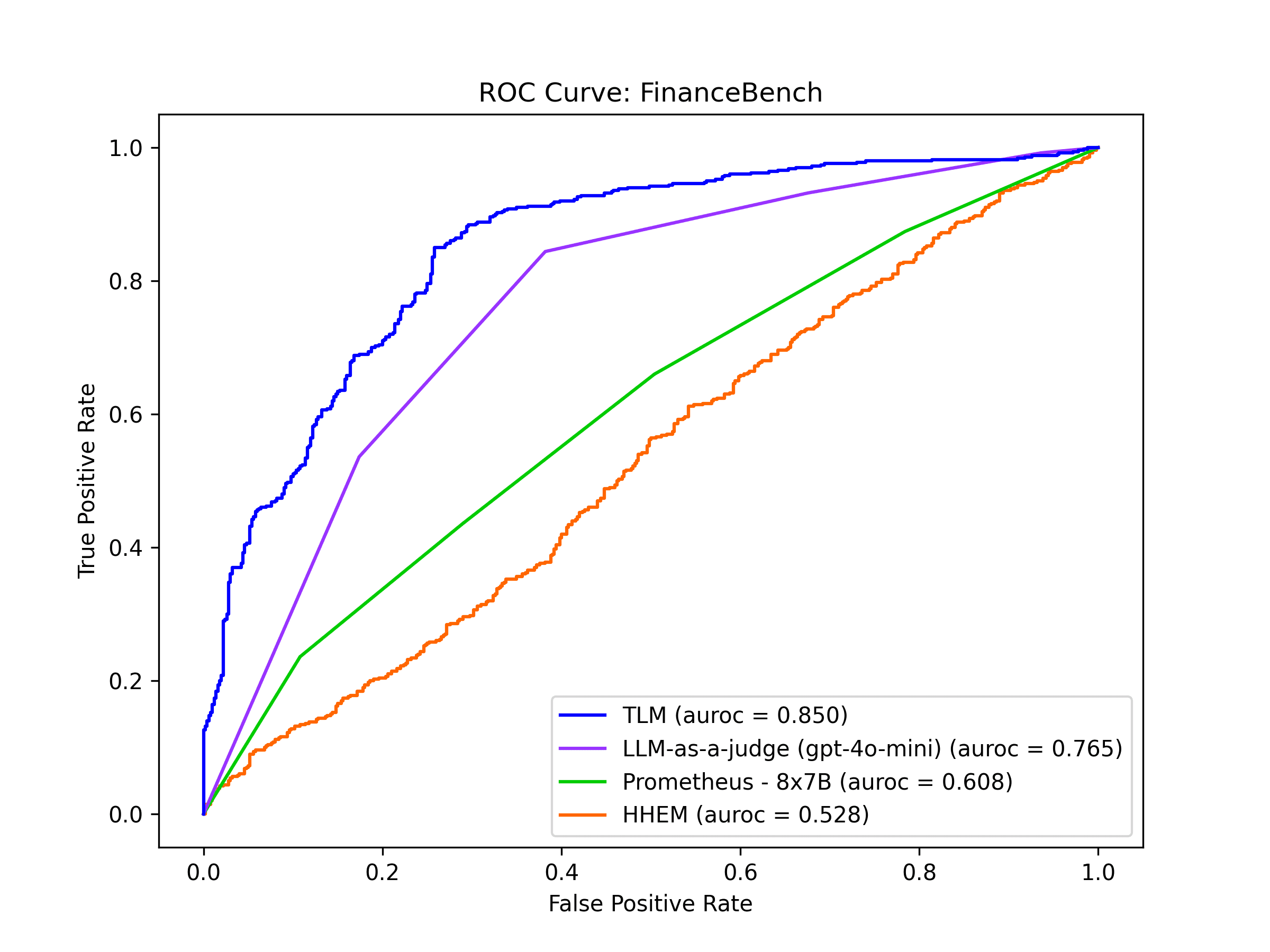
For FinanceBench, TLM and LLM-as-a-judge detect incorrect AI responses with the highest precision and recall. This matches the previous findings for FinQA, even though the two datasets contain different types of information and user queries.
PubmedQA
PubmedQA is a dataset where context comes from PubMed (medical research publication) abstracts that is used by the LLM to answer biomedical questions. Here’s an example query from this dataset that the LLM must answer based on relevant context from a medical publication:
A patient with myelomeningocele: is untethering necessary prior to scoliosis correction?
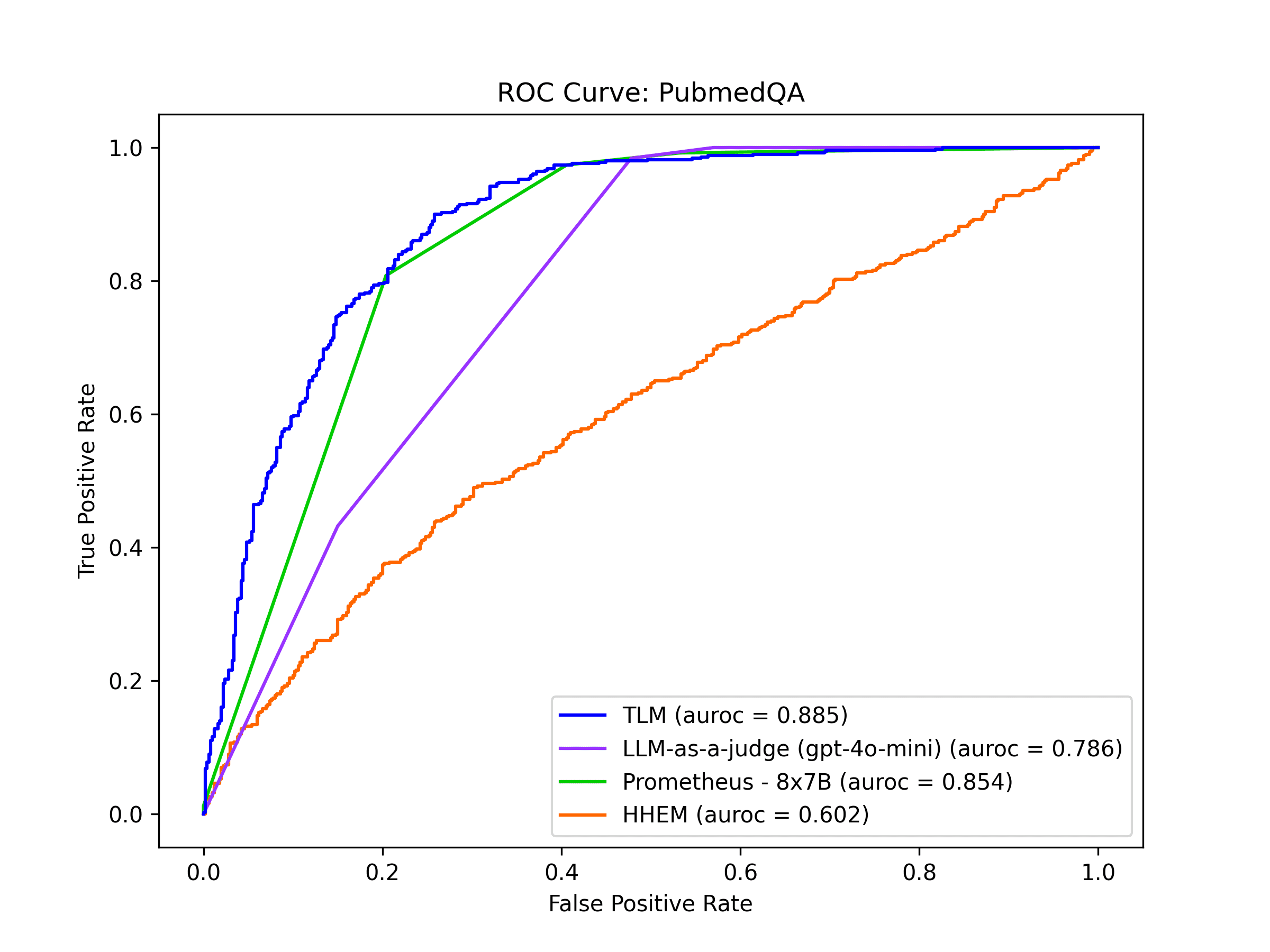
In this benchmark, Prometheus and TLM detect incorrect AI responses with the highest precision and recall. For this application, these Evaluation models are able to catch hallucinations very effectively.
CovidQA
CovidQA is a dataset to help experts answer questions related to the Covid-19 pandemic based on the medical research literature. The dataset contains scientific articles as retrieved context and queries such as:
What is the size of the PEDV genome?
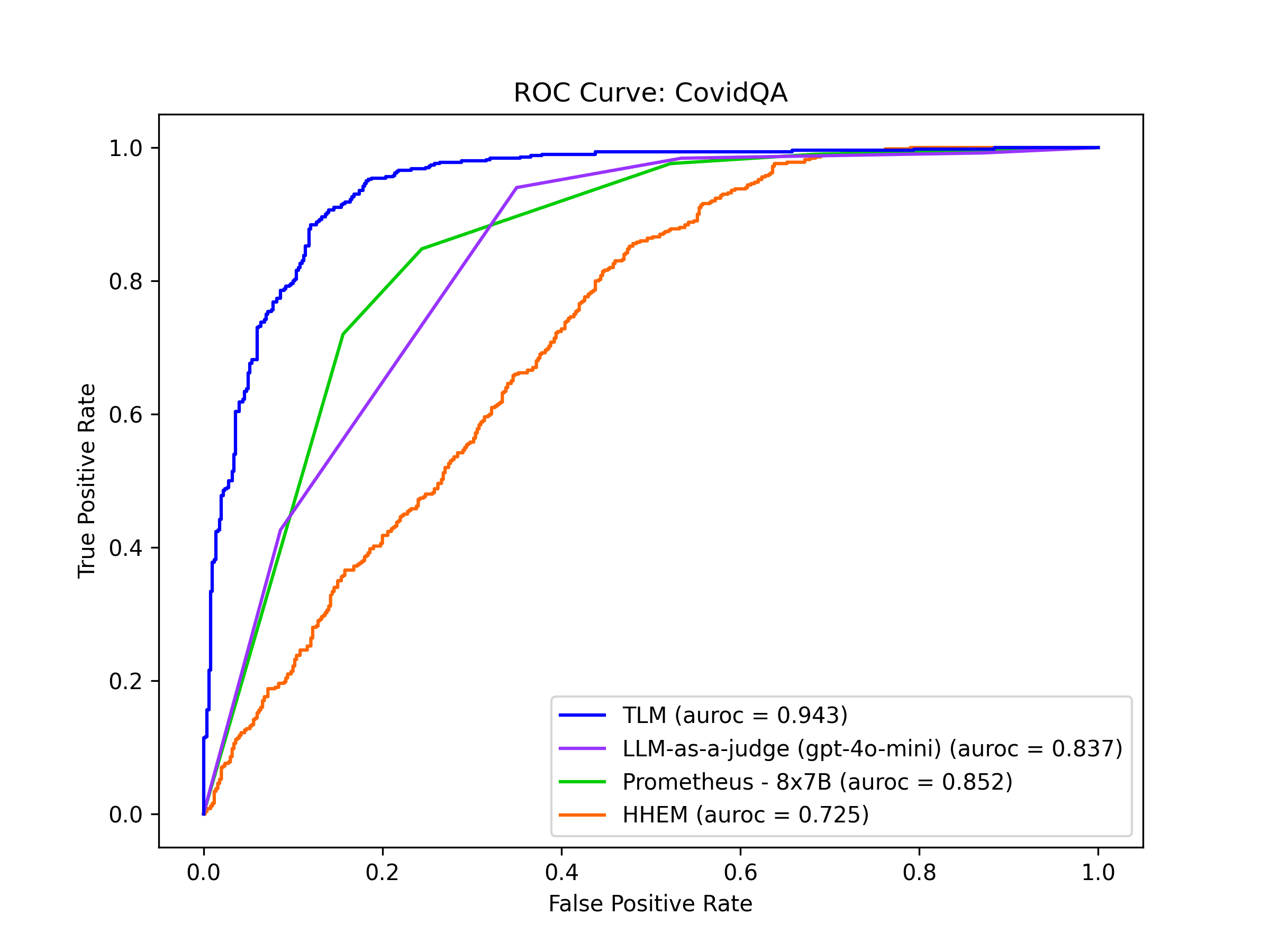
In this benchmark, TLM detects incorrect AI responses with the highest precision and recall, followed by Prometheus and LLM-as-a-judge. For this application, today’s top Evaluation models provide a reliable way to catch hallucinations.
DROP
Discrete reasoning over paragraphs (DROP) consists of passages retrieved from Wikipedia articles and questions that require discrete operations (counting, sorting, etc.) and mathematical reasoning to answer.
For example, given a passage about the game between the Cowboys and Jaguars, a question from the dataset is: Which team scored the least points in the first half?
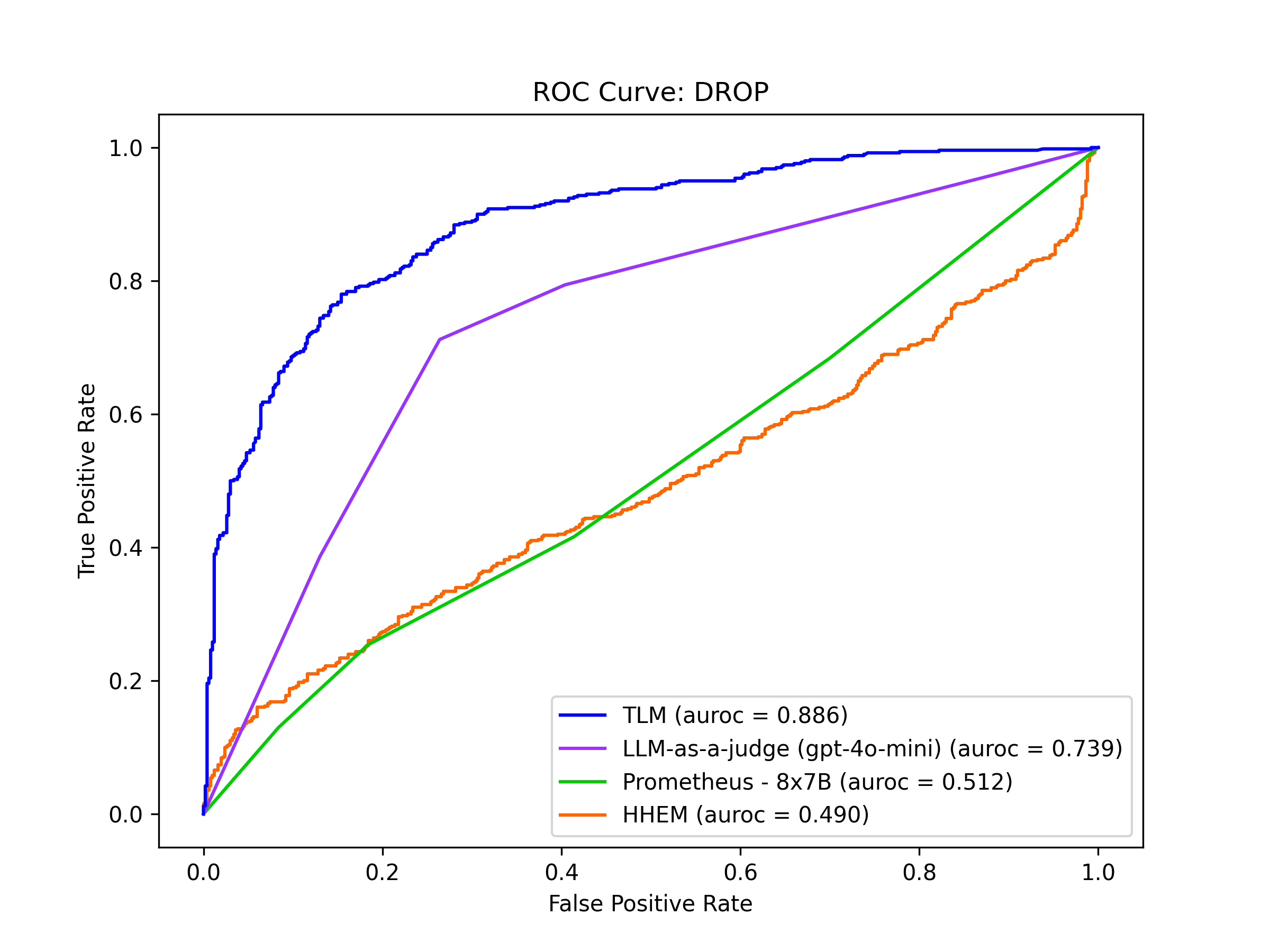
In this benchmark, TLM detects incorrect AI responses with the highest precision and recall, followed by LLM-as-a-judge. No other Evaluation model appears very useful in this more challenging application.
Discussion
Our study presented one of the first benchmarks of real-time Evaluation models in RAG. We observed that most of the Evaluation models could detect incorrect RAG responses significantly better than random chance on some of the datasets, but certain Evaluation models didn’t fare much better than random chance on other datasets. Thus carefully consider your domain when choosing an Evaluation model.
Some of the Evaluation models in this study are specially trained custom models. Since these custom models were trained on errors made by certain LLMs, their future performance remains unclear when future LLMs make different types of errors. In contrast, evaluation techniques like LLM-as-a-judge or TLM can be powered by any LLM and should remain relevant for future LLMs. These techniques require no data preparation/labeling, nor infrastructure to serve a custom model (assuming you have infrastructure to run pre-trained LLM models like AWS Bedrock, Azure/OpenAI, Gemini, Together.ai, etc).
Besides these Evaluation models, other techniques have been used for detecting hallucinations. One previous study benchmarked alternative techniques, including DeepEval, G-Eval, and RAGAS, finding that Evaluation models like TLM detect incorrect RAG responses with universally higher precision/recall. Another study found that TLM detects incorrect responses more effectively than techniques like LLM-as-a-judge or token probabilities (logprobs), across all major LLM models.
Resources to learn more
- Code to reproduce these benchmarks - Beyond reproducing the results of our study, you can also use this code to test your own hallucination detectors.
- Quickstart tutorial - Build your own trustworthy RAG application in a few minutes.