

This article demonstrates an agentic system to ensure reliable answers in Retrieval-Augmented Generation, while also ensuring that latency and compute costs do not exceed the processing needed to accurately respond to complex queries. Our system relies on trustworthiness scores for LLM outputs, in order to dynamically adjust retrieval strategies until sufficient context has been retrieved to generate a trustworthy RAG answer.
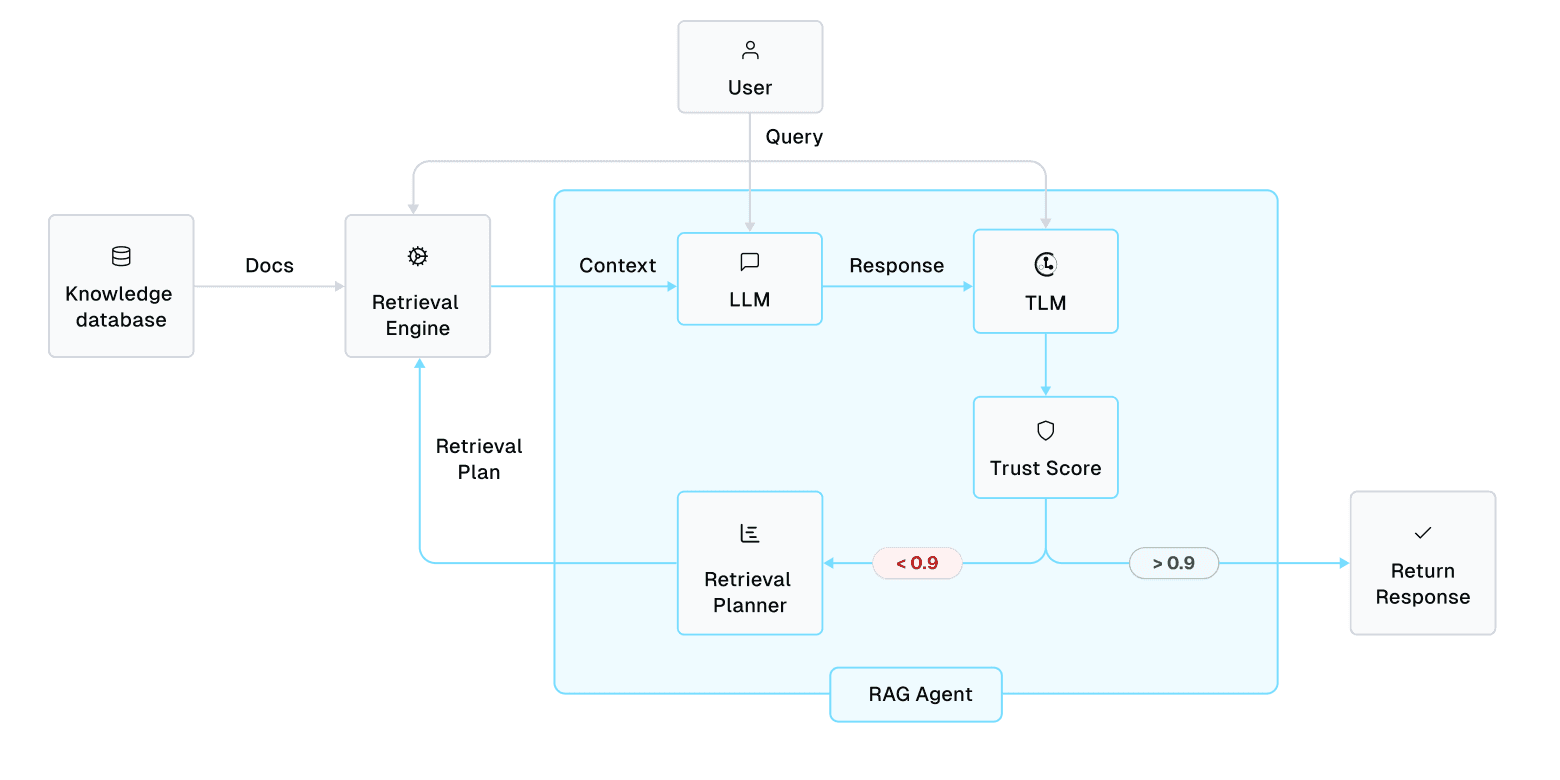
Based on the trustworthiness score for a candidate response, the RAG Agent can choose more complex retrieval plans or approve the response for production.
Introduction
Retrieval-Augmented Generation (RAG) combines the strengths of large language models (LLMs) with powerful retrieval systems to generate more accurate responses grounded in knowledge databases. Simple RAG systems retrieve relevant information to a query via semantic search based on vector embeddings of query and database contents, but this strategy fails for more complex queries.
Agentic RAG considers various Retrieval strategies as tools available to an LLM orchestrator that can iteratively decide which tools to call next based on what it’s seen thus far. This Agent can plan, execute, and refine multi-step retrieval processes, but it is critical to ensure latency and compute costs do not exceed what is required to produce a good answer for a user’s query. Despite advancements from LLMs → RAG → Agentic RAG with sophisticated Retrieval strategies, AI-generated responses still suffer from hallucinations today, producing incorrect or nonsensical information with unwarranted confidence.
This blog outlines an Agentic RAG system that can produce trustworthy answers even for complex queries, in a manner that keeps latency/costs in check. Our system relies on the Trustworthy Language Model to score the trustworthiness of a candidate response (based on the query and currently retrieved context). When the current response is deemed untrustworthy, the Agent is tasked with orchestrating a better Retrieval strategy to improve the context. This system starts with cheaper Retrieval strategies, and dynamically tries strategies with greater runtime/costs only for complex queries where they are necessary to produce a trustworthy RAG answer.
Trustworthy Language Model (TLM)
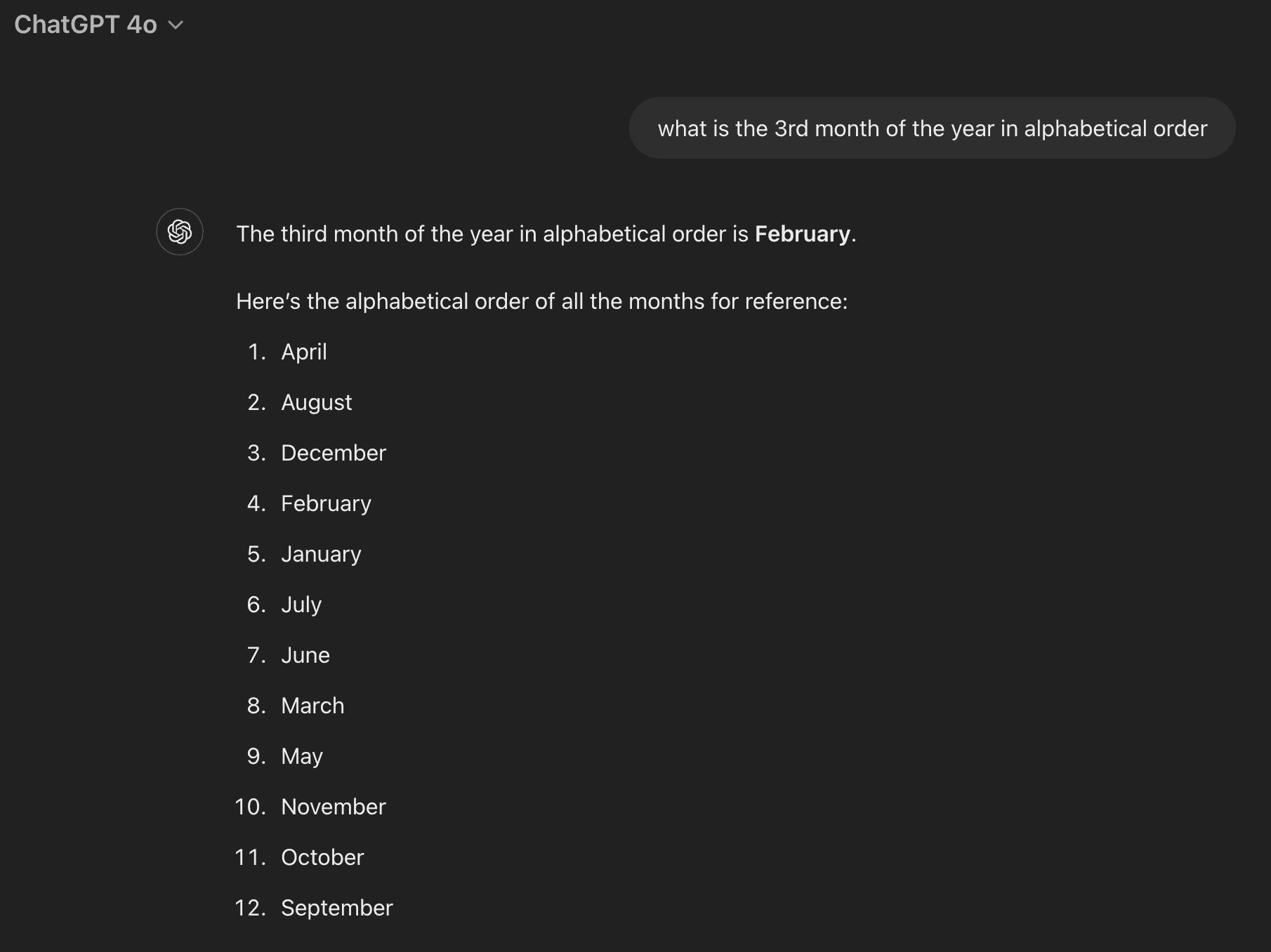
For a given user query, the RAG system will retrieve relevant context, which is then fed into a LLM to produce the response. But how do we know when the response is untrustworthy? For instance, here is question incorrectly answered by ChatGPT with no indication it should not be trusted.
TLM automates this determination, by producing a trustworthiness score (between 0-1) for responses from any LLM. For the above prompt & ChatGPT response:
indicating this response should not be trusted.
These scores have been found to detect hallucinations and LLM errors with greater precision/recall than alternative approaches like asking the LLM to evaluate its own output or relying on token-probabilities. TLM internally estimates aleatoric and epistemic uncertainty of the LLM by combining techniques including self-reflection, probabilistic prediction, and observed consistency. You can present TLM trustworthiness scores to users of your RAG system to automatically help them understand which responses warrant further scrutiny.
Utilizing the trustworthiness score in Agentic RAG
A user’s query is processed by our RAG system as follows: the Retrieval Planner Agent orchestrates a series of Retrieval strategies in order to discover relevant context, that when appended to the query, leads to an LLM response with sufficiently high trustworthiness score. The Agent is encouraged to start with faster/cheaper Retrieval strategies and only escalate to more complex Retrieval when a high trustworthiness score has not yet been achieved. As soon as a trustworthy LLM response is produced, it is returned to the user.
This high-level system can work with many types of Retrieval Planner Agent implementations (e.g. via frameworks like LangGraph and tool-use algorithms like OpenAI Function Calling), as well as all sorts of Retrieval strategies. The goal is to minimize the runtime and costs required to process most queries, while still being able to produce trustworthy responses for complex queries that necessitate more compute.
Potential Retrieval Strategies
As a concrete example, our Retrieval Planner Agent might choose from the following Retrieval strategies, increasing in time and compute complexity:
- No Retrieval
- Complexity: None
- The query is answerable with general knowledge the LLM already knows.
- Semantic Search (vector embedding similarity)
- Complexity: Low
- Vector database (Pinecone, Qdrant, Weaviate, etc.) is searched using top similarities in space of embeddings (Sentence Transformers, Voyage, etc.)
- Complexity: Low/Medium
- Knowledge database is searched via a combination of vector similarity and classical keyword search like BM25, with results rankings from different searches aggregated via the RRF method.
- Re-Ranking retrieved results
- Complexity: Medium
- A specialized re-ranker model is applied to the retrieved results from either vector or keyword search that more accurately estimates which ones are relevant to the query.
- Complexity: Medium/High
- User query is rewritten into possibly multiple queries before (possibly multiple steps of) Retrieval. This includes entity recognition, separate keyword searches, and methods like Hypothetical Document Embeddings (Hyde) or Step-Back Prompting.
- Chunk/Document Expansion (Multi-Hop RAG, GraphRAG)
- Complexity: Medium/High
- Returned chunks from the vector database search are expanded by referring to the original document from which they came and traversing related documents or Knowledge Graphs like Neo4j. This may be required to find additional information that is needed for the retrieved context to be useful.
Examples of our Trustworthy Agentic RAG in action
To make things more concrete, we consider a RAG application intended to answer questions based on Nvidia’s product documentation.
Simple Query
Let’s first consider a simple query that a user may pose:
Query: Which component of a computer is responsible for graphics rendering?
On the first pass, our RAG Agent chooses the least complex retrieval plan: do not retrieve anything. The response and associated trustworthiness score are:
Response: The component of a computer responsible for graphics rendering is the Graphics Processing Unit (GPU).
Trustworthiness Score: 0.986
In this case, the RAG Agent determines the response to be trustworthy and approves the response to be used downstream.
Complex Query
Now for a more complex query:
Query: How many NVIDIA CUDA Cores does the RTX 4090 have?
Our RAG Agent might again initially choose to not retrieve anything, yielding:
Response: As of my last update in October 2022, NVIDIA has not released an RTX 4090 graphics card. Therefore, there are no official specifications.
Trustworthiness Score: 0.725
It appears that the LLM used does not have access to this knowledge. This is quantified by the trustworthiness score, enabling our system to determine this is not a reliable response and then to automatically employ a more complex retrieval plan: vector embedding search. On the second pass, the context, response, and trustworthiness score are:
Retrieved Context:
GeForce RTX 4090 GPU Engine Specs: NVIDIA CUDA Cores 16384 Shader Cores Ada Lovelace 83 TFLOPS Ray Tracing Cores 3rd Generation 191 TFLOPS Tensor Cores (AI) 4th Generation 1321 AI TOPS Boost Clock (GHz) 2.52 Base Clock (GHz) 2.23
Response: The NVIDIA GeForce RTX 4090 features 16,384 CUDA cores.
Trustworthiness Score: 0.988
Nice! The RAG Agent was able to dynamically up the complexity of the retrieval plan and now has a satisfactory answer with a high trustworthiness score.
More Complex Query
Let’s consider a more complex query:
Query: What were the key design challenges faced by NVIDIA in developing the RTX 4090, and how were they overcome?
Our RAG Agent might again initially chooses to not retrieve anything, yielding:
Response: The NVIDIA RTX 4090 was developed to push the boundaries of GPU performance, requiring significant advancements in architecture, thermal management, and power efficiency.
Trustworthiness Score: 0.635
TLM identifies this response is generic and not confidently containing the right information. In the next pass, our RAG Agent might opt for vector similarity search again, yielding:
Retrieved Context: NVIDIA’s RTX 4090 was anticipated to be a major leap in GPU technology. There were discussions about improving overall architecture and enhancing ray tracing capabilities. However, specific details about the challenges during its development are scarce. Some sources suggest that NVIDIA focused on maximizing performance for gaming and AI applications, but there is little concrete information on the exact hurdles faced.
Response: The NVIDIA RTX 4090 focused on improving performance and ray tracing capabilities, but specific details about the challenges encountered during development are not well-documented. It is believed that NVIDIA prioritized enhancements in gaming and AI, but the exact difficulties they faced remain unclear.
Trustworthiness Score: 0.805
In this pass, our RAG Agent retrieved unsatisfactory information. The corresponding moderate trustworthiness score reflects the lack of specific context. Our RAG Agent thus considers another Retrieval pass with a more complex Hybrid search strategy, yielding:
Retrieved Context: The RTX 4090’s development saw NVIDIA addressing several engineering hurdles. The thermal challenges were exacerbated by the sheer density of the CUDA cores, necessitating an innovative cooling solution. NVIDIA introduced a new fan design and a larger vapor chamber to dissipate heat more effectively. On the power side, the 4090 required a new power connector standard, the PCIe Gen 5 16-pin, which allowed for higher wattage delivery, ensuring stable operation under load. For AI integration, NVIDIA refined its Tensor Core technology to balance power and performance, ensuring that the 4090 could handle advanced AI workloads without bottlenecking other processes.
Response: NVIDIA’s RTX 4090 development involved overcoming several key challenges, particularly around thermal management and power delivery. The GPU’s high density of 16,384 CUDA cores required an innovative cooling system, leading to the introduction of a new fan design and larger vapor chamber. Additionally, the need for higher power delivery led to the adoption of the PCIe Gen 5 16-pin connector. To integrate AI features effectively, NVIDIA refined its Tensor Core technology, balancing power and performance to handle advanced AI workloads efficiently.
Trustworthiness Score: 0.975
With the expanded context, the RAG Agent produces a highly detailed and specific response that earns a high enough trustworthiness score to return to the user. That said, this higher quality answer did require additional time/costs to produce.
The same process continues for queries with greater levels of complexity. Our RAG Agent continues escalating Retrieval strategies until the trustworthiness score indicates a reliable response, or the maximum time limit is reached. If no Retrieval strategy yields a trustworthy LLM response, then our system responds that it cannot handle this question without additional clarifications/information.
Wrap Up
Integrating the Trustworthy Language Model enables Agentic RAG systems that can ensure accurate answers to complex queries while bounding latency/costs for regular queries. You can adopt this approach to navigate the delicate balance between speed, cost, and accuracy across diverse RAG applications—from customer service to specialized fields like finance, law, and medicine.
While traditional RAG systems generate responses of unknown quality based on predefined steps to process every query, the future of AI lies in systems that assess response trustworthiness and adapt processing plans to each query’s complexity. Agentic RAG with the TLM offers a promising step toward this future of reliable AI.
Next Steps
- Get started with the TLM tutorials.
- Read benchmarks measuring the effectiveness of LLM trustworthiness scores.