
Introduction
From fluctuations in the stock market to the rhythmic pulse of weather patterns and even the ebb and flow of website traffic - observable changes over time are ever present. While levels of available historic data utilized to forecast future outcomes continute to rise, available time in a day stays the same. AutoML for time series forecasting can lessen the burden of these increasing demands - and we’ll show you how to deploy a production-level model in 10 minutes with Cleanlab Studio in python or using our seamless no-code platform.
Here’s the code if you’d like to follow along with details for the project and benchmarking to other methods against Cleanlab Studio AutoML - Cleanlab Studio access is required, try here for free. Book a demo for a personalized tour - no code required. You can also download the popular PJM Energy Consumption Dataset we’re using.
Problem statement
Given a dataset of time stamps and energy consumption levels, can we develop a solution that will predict energy levels for the future?
Approach
Reframing the problem from time-series to classification, and applying Cleanlab Studio AutoML to streamline and optimize a multi-step time-consuming process.
Why transform a time-series dataset into a classification dataset?
Reframing the problem leverages classification strengths, enhancing performance, flexibility, and interpretability.
- Model Flexibility and Variety: Access a wider range of models like random forests and neural networks, capturing patterns more effectively.
- Handling Non-Stationary Data: Focus on classifying categories rather than predicting exact values, making it easier to handle data with changing statistical properties.
- Performance and Accuracy: Classification algorithms often provide superior performance for categorical outcomes, improving forecast accuracy.
- Simplified Problem Framing: Discretizing continuous variables into categories simplifies the problem and makes interpretation easier.
- Feature Engineering and Selection: Allows for tailored feature engineering, improving model performance by including lagged values, moving averages, and external variables.
- Robustness to Outliers: Classification models are more robust to outliers, focusing on predicting categories rather than exact values.
- Ease of Interpretation: Results are clearer and easier to communicate to stakeholders, with outputs as categories instead of numerical values.
Let’s examine our dataset, which includes a datetime column and a Megawatt Energy Consumption column. We aim to forecast daily energy consumption levels into one of four quartiles: low, below average, above average, or high. Initially, we apply time-series forecasting methods like Prophet but then reframe the problem into a multiclass classification task to leverage more versatile machine learning models for superior forecasts.
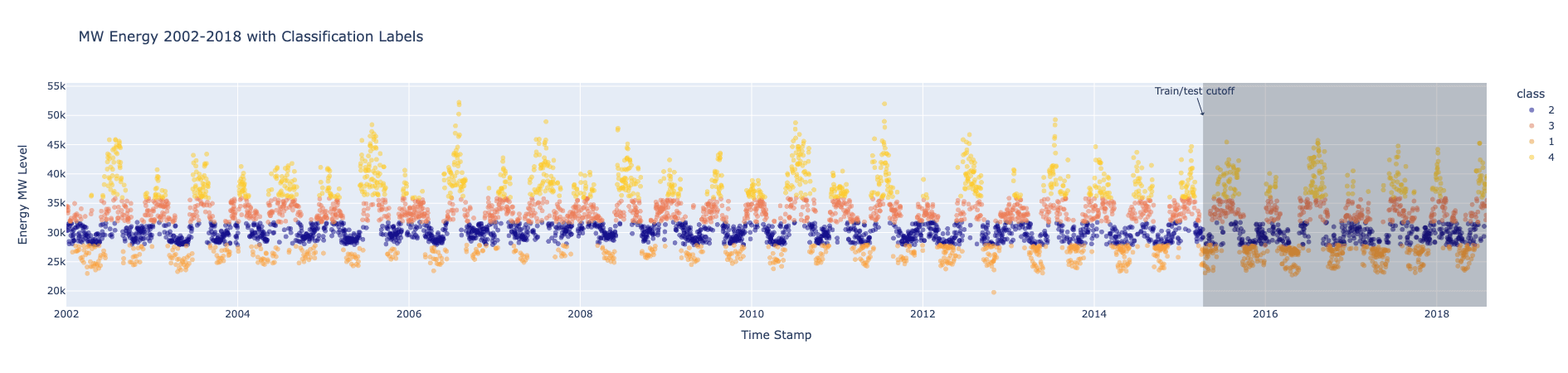
Train and evaluate Prophet forecasting model
In the images above, we set the training data cutoff at 2015-04-09 and begin our test data from 2015-04-10. Using only the training data, we compute quartile thresholds for daily energy consumption to prevent data leakage from future out-of-sample data.
In order to compare to later classification models, we then forecast daily PJME energy consumption levels (in MW) for the test period and categorize these forecasts into quartiles: 1 (low), 2 (below average), 3 (above average), or 4 (high).
Establishing a Prophet Baseline Code
The out-of-sample accuracy is low at 43%. Not only does using only time series forecasting models limit our approach, the solution doesn’t require on-the-meter predictions. If we transform the time series data into tabular, we can quickly spin up a Cleanlab Studio AutoML solution.
Convert time series data to tabular data through featurization
We convert the time series data into a tabular format and use libraries like sktime, tsfresh, and tsfel to extract a wide array of features. These features capture statistical, temporal, and spectral characteristics of the data, making it easier to understand how different aspects influence the target variable.
TSFreshFeatureExtractor from sktime utilizes tsfresh to automatically calculate many time series characteristics, helping us understand complex temporal dynamics. We use essential features from this extractor for our data.
tsfel provides tools to extract a rich set of features from time series data. Using a predefined config, we capture various characteristics relevant to our classification task from the energy consumption data.
Time Series Feature Extraction Code
Next, we clean our dataset by removing features with high correlation (above 0.8) to the target variable and null correlations to improve model generalizability, reduce chance of overfitting, and ensure predictions are based on meaningful data inputs.
Extract Features for Time Series > Tabular
We now have 73 features from the time series featurization libraries to predict the next day’s energy consumption level.
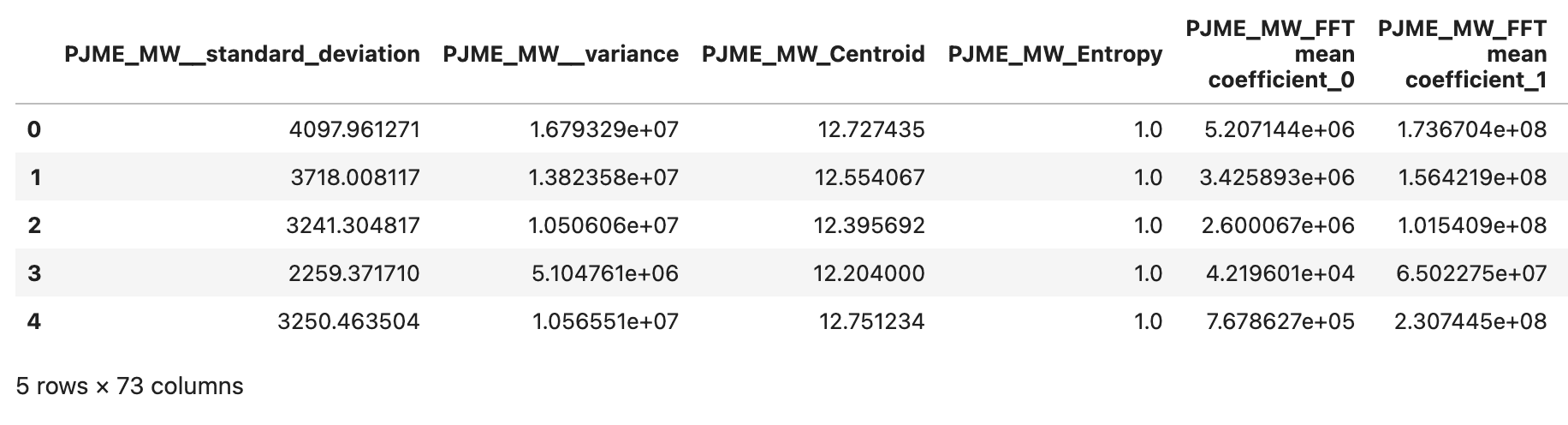
A quick note about avoiding data leakage
Data leakage occurs when information from outside the training dataset is used to create the model, leading to overly optimistic performance estimates and poor generalization to new, unseen data. To avoid data leakage, we applied the featurization process separately for training and test data. Additionally, we computed our discrete quartile values for energy labels using predefined quartiles for both train and test datasets.
Calculate Quartiles From Training Data, Apply to Train/Test
Train and evaluate GradientBoostingClassifier on featurized tabular data
Using our featurized tabular dataset, we can apply any supervised ML model to predict future energy consumption levels. Here we’ll use a Gradient Boosting Classifier (GBC) model, the weapon of choice for most data scientists operating on tabular data.
Our GBC model is instantiated from the sklearn.ensemble module and configured with specific hyperparameters to
optimize its performance and avoid overfitting.
Train and Test Gradient Boosting Classifier for Baseline
With a far simpler problem of classification that still meets our needs, this accuracy of 80.75% for all classes is a great start. However, placing this model in production would still require engineering time and certainty that this model is the best for this problem.
Solution: Streamline with Cleanlab Studio AutoML
Now that we’ve seen the benefits of featurizing a time-series problem and applying powerful ML models like Gradient Boosting, the next step is choosing the best model. Experimenting with various models and tuning their hyperparameters can be time-consuming. Instead, let AutoML handle this for you.
With Cleanlab Studio, you can leverage a simple, zero-configuration AutoML solution. Just provide your tabular dataset, and the platform will automatically train multiple supervised ML models, tune their hyperparameters, and combine the best models into a single predictor. For a quick start with your own data, refer to this guide.
Here’s all the code you need to train and deploy an AutoML supervised classifier:
Next load the dataset into Cleanlab Studio (more details/options can be found in this guide). This may take a while for big datasets.
Now you can create a project using this dataset.
Once the below cell completes execution, your project results are ready for review!
Just one of the ways Cleanlab Studio simplifies the process of training a model is automatically identifying and fixing data and label issues. Once your dataset is clean, a single click with AutoML trains and deploys a reliable model suitable for production.
In the Studio interface for this project, we first used Clean Top K and Auto-Fix to address Label Issues and Ambiguous datapoints. Then, we hit Improve Results for several iterations, creating multiple Cleansets of our original data to deploy separate models.
Deploying a model for this solution is simple - click the Deploy Model button and your model will be inference-ready on new data once it’s in the ‘Deployed’ status.
After the model is deployed we check the AutoML results in our Model Details tab:
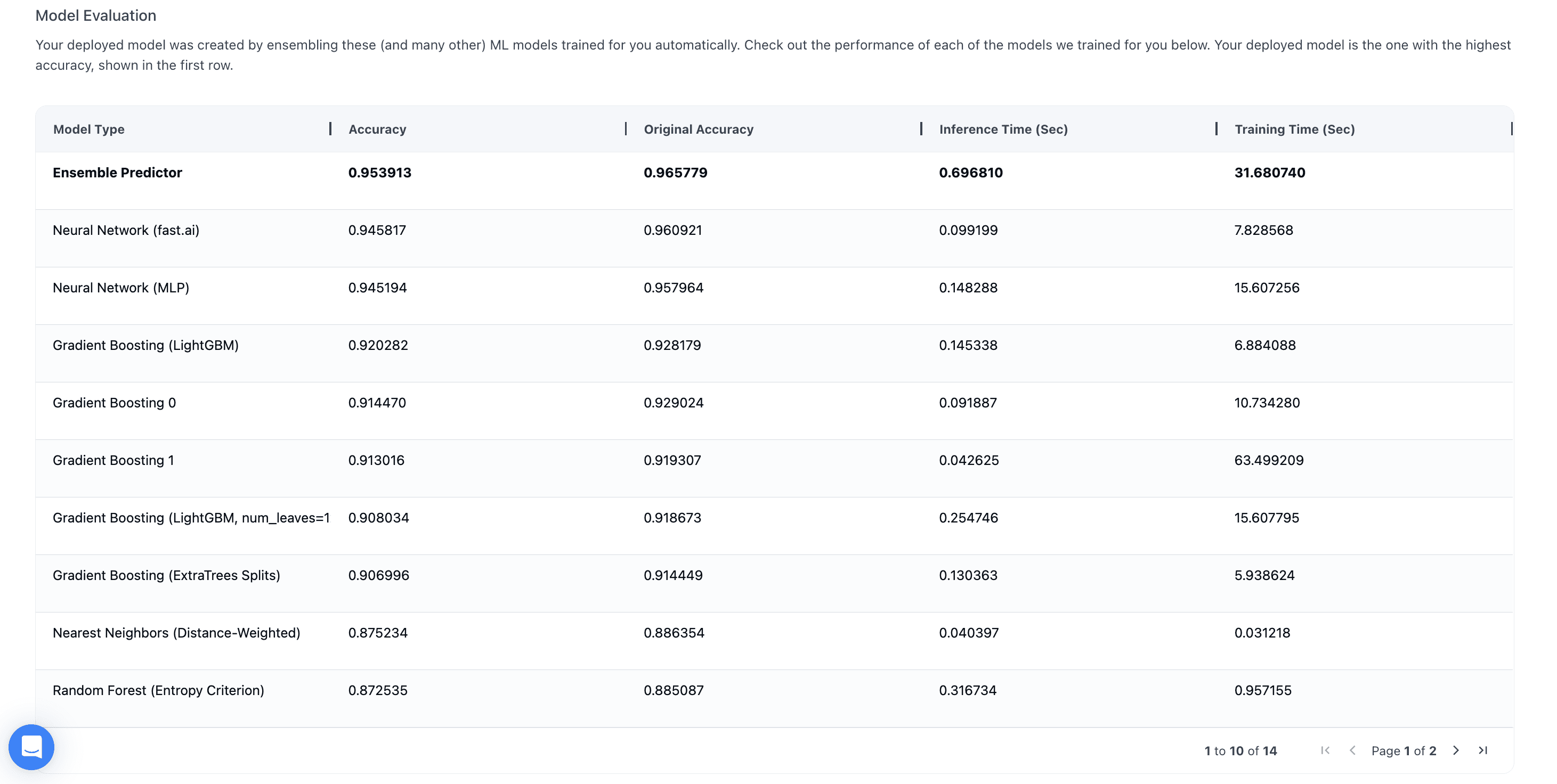
Then in our code we can fetch our model ID from the Studio Dashboard and feed it into our Python Studio object below:
Using our model trained on our cleaned training data, we can run inference on our test data now to get pred_probs:
And we can now compare our out-of-sample accuracy:
Results Recap
| Algorithm | Type | Out-Of-Sample Accuracy |
|---|---|---|
| Prophet | Time-Series | 0.43 |
| Gradient Boosting | Classification | 0.8075 |
| Cleanlab Studio AutoML | Classfication | 0.9461 |

Conclusion
Cleanlab Studio is an advanced AutoML solution that streamlines and enhances the machine learning workflow. For time series data, converting it to a tabular format and featurizing it before deploying to Cleanlab Studio can significantly reduce development time and effort through automated feature selection, model selection, and hyperparameter tuning.
For our PJM daily energy consumption data, transforming the data into a tabular format and using Cleanlab Studio achieved a 67% reduction in prediction error compared to our baseline Prophet model. Additionally, an easy AutoML approach for multiclass classification resulted in a 72% reduction in prediction error compared to our Gradient Boosting model and an 91% reduction in prediction error compared to the Prophet model.
Using Cleanlab Studio to model a time series dataset with general supervised ML techniques can yield better results than traditional forecasting methods.
Next Steps
Transforming a time series dataset into a tabular format allows the use of standard machine learning models, enriched with diverse feature sets through feature engineering. Leveraging Automated Machine Learning (AutoML) streamlines the entire ML lifecycle, from data preparation to model deployment. Cleanlab Studio automates this process with just a few clicks, training a baseline model, correcting data issues, identifying the best model, and deploying it for predictions—significantly reducing the effort and expertise needed.
Take AutoML for a test drive today, try Cleanlab Studio for free!