
In this article, I highlight the use of active learning to improve a fine-tuned Hugging Face Transformer for text classification, while keeping the total number of collected labels from human annotators low. When resource constraints prevent you from acquiring labels for the entirety of your data, active learning aims to save both time and money by selecting which examples data annotators should spend their effort labeling.
ActiveLab greatly reduces labeling costs and time spent to achieve a given model performance compared to standard data annotation. In the experiments demonstrated in this article, ActiveLab hits 90% model accuracy at only 35% of the label spend as standard training.

What is Active Learning?
Active Learning helps prioritize what data to label in order to maximize the performance of a supervised machine learning model trained on the labeled data. This process usually happens iteratively — at each round, active learning tells us which examples we should collect additional annotations for to improve our current model the most under a limited labeling budget. ActiveLab is an active learning algorithm that is particularly useful when the annotators are noisy because it helps decide when we should collect one more annotation for a previously annotated example (whose label seems suspect) vs. for a not-yet-annotated example. After collecting these new annotations for a batch of data to increase our training dataset, we re-train our model and evaluate its test accuracy.
Here I consider a binary text classification task: predicting whether a specific phrase is polite or impolite. Compared to random selection of which examples to collect an additional annotation for, active learning with ActiveLab consistently produces much better Transformer models at each round (around 50% of the error-rate), no matter the total labeling budget!
The rest of this article walks through the open-source code you can use to achieve these results. You can run all of the code to reproduce my active learning experiments here: Colab Notebook
Classifying the Politeness of Text
The dataset I consider here is a variant of the Stanford Politeness Corpus. It is structured as a binary text classification task, to classify whether each phrase is polite or impolite. Human annotators are given a selected text phrase and they provide an (imperfect) annotation regarding its politeness: 0 for impolite and 1 for polite.
Training a Transformer classifier on the annotated data, we measure model accuracy over a set of held-out test examples, where I feel confident about their ground truth labels because they are derived from a consensus amongst 5 annotators who labeled each of these examples.
As for the training data, we have:
X_labeled_full: our initial training set with just a small set of 100 text examples labeled with 2 annotations per example.X_unlabeled: large set of 1900 unlabeled text examples we can consider having annotators annotate.
Here are a few examples from X_labeled_full:
- Hi, nice article. What is meant by “speculative townhouses?” Ones that were built for prospective renters rather than for committed buyers?
- Annotation (by annotator #61): polite
- Annotation (by annotator #99): polite
- Congrats, or should I say good luck?
- Annotation (by annotator #16): polite
- Annotation (by annotator #22): impolite
- 4.5 million hits on Google turning up the non-Columbia campuses. What are you talking about?
- Annotation (by annotator #22): impolite
- Annotation (by annotator #61): impolite
Methodology
For each active learning round we:
- Compute ActiveLab consensus labels for each training example derived from all annotations collected thus far.
- Train our Transformer classification model on the current training set using these consensus labels.
- Evaluate test accuracy on the test set (which has high-quality ground truth labels).
- Run cross-validation to get out-of-sample predicted class probabilities from our model for the entire training set and unlabeled set.
- Get ActiveLab active learning scores for each example in the training set and unlabeled set. These scores estimate how informative it would be to collect another annotation for each example.
- Select a subset (n = batch_size) of examples with the lowest active learning scores.
- Collect one additional annotation for each of the n selected examples.
- Add the new annotations (and new previously non-annotated examples if selected) to our training set for the next iteration.
I subsequently compare models trained on data labeled via active learning vs. data labeled via random selection. For each random selection round, I use majority vote consensus instead of ActiveLab consensus (in Step 1) and then just randomly select the n examples to collect an additional label for instead of using ActiveLab scores (in Step 6).
Model Training and Evaluation
Here is the code we use for model training and evaluation.
I first tokenize my test and train sets, and then initialize a pre-trained DistilBert Transformer model. Fine-tuning DistilBert with 300 training steps produced a good balance between accuracy and training time for my data. This classifier outputs predicted class probabilities which I convert to class predictions before evaluating their accuracy.
Use Active Learning Scores to Decide what to Label Next
Here is the code we use to score each example via an active learning estimate of how informative collecting one more label for this example will be.
During each round of Active Learning, we fit our Transformer model via 3-fold cross-validation on the current training set. This allows us to get out-of-sample predicted class probabilities for each example in the training set and we can also use the trained Transformer to get out-of-sample predicted class probabilities for each example in the unlabeled pool. All of this is internally implemented in the get_pred_probs helper method. The use of out-of-sample predictions helps us avoid bias due to potential overfitting.
Once I have these probabilistic predictions, I pass them into the get_active_learning_scores method from the open-source cleanlab package, which implements the ActiveLab algorithm. This method provides us with scores for all of our labeled and unlabeled data. Lower scores indicate data points for which collecting one additional label should be most informative for our current model (scores are directly comparable between labeled and unlabeled data).
I form a batch of examples with the lowest scores as the examples to collect an annotation for (via the get_idx_to_label method). Here I always collect the exact same number of annotations in each round (under both the active learning and random selection approaches). For this application, I limit the maximum number of annotations per example to 5 (don’t want to spend effort labeling the same example over and over again).
Adding new Annotations
Here is the code used to add new annotations for the chosen examples to the current training dataset.
The combined_example_ids are the ids of the text examples we want to collect an annotation for. For each of these, we use the get_annotation helper method to collect a new annotation from an annotator. Here, we prioritize selecting annotations from annotators who have already annotated another example. If none of the annotators for the given example exist in the training set, we randomly select one. In this case, we add a new column to our training set which represents the new annotator. Finally, we add the newly collected annotation to the training set. If the corresponding example was previously non-annotated, we also add it to the training set and remove it from the unlabeled collection.
We’ve now completed one round of collecting new annotations and retrain the Transformer model on the updated training set. We repeat this process in multiple rounds to keep growing the training dataset and improving our model.
Results
I ran 25 rounds of active learning (labeling batches of data and retraining the Transformer model), collecting 25 annotations in each round. I repeated all of this, the next time using random selection to choose which examples to annotate in each round — as a baseline comparison. Before additional data are annotated, both approaches start with the same initial training set of 100 examples (hence achieving roughly the same Transformer accuracy in the first round). Because of inherent stochasticity in training Transformers, I ran this entire process five times (for each data labeling strategy) and report the standard deviation (shaded region) and mean (solid line) of test accuracies across the five replicate runs.
Takeaway: ActiveLab greatly reduces time and labeling costs to achieve a given model performance compared to standard data annotation. For example, ActiveLab hits 90% model accuracy at only 35% of the label spend as standard training.
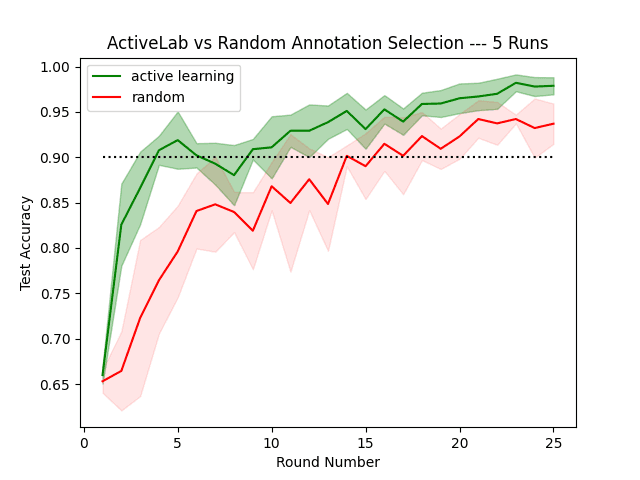
We see that choosing what data to annotate next has drastic effects on model performance. Active learning using ActiveLab consistently outperforms random selection by a significant margin at each round. For example, in round 4 with 275 total annotations in the training set, we obtain 91% accuracy via active learning vs. only 76% accuracy without a clever selection strategy of what to annotate. Overall, the resulting Transformer models fit on the dataset constructed via active learning have around 50% of the error-rate, no matter the total labeling budget!
When labeling data for text classification, you should consider active learning with the re-labeling option to better account for imperfect annotators.
Next Steps
- Check out our ActiveLab tutorial.
- Easily improve your data with Cleanlab Studio!
- Star our github repo to support open-source tools for Data-Centric AI.
- Join our Cleanlab Community Slack to discuss how you’re applying active learning.
- Follow us on LinkedIn or Twitter to stay up-to-date on algorithms for improving datasets.