Imagine constructing a state-of-the-art skyscraper, only to discover that its foundation is riddled with inconsistencies and errors. The potential for disaster becomes palpable. In the realm of Artificial Intelligence (AI), data serves as the bedrock upon which the efficacy of algorithms stands or crumbles.
Mislabeled data and flawed data annotation have emerged as silent saboteurs, relentlessly eroding the reliability and potential of AI systems. As businesses eagerly seek to harness the power of AI, the pitfalls of mislabeled data are creating ripples that could hinder progress and lead to unintended consequences.
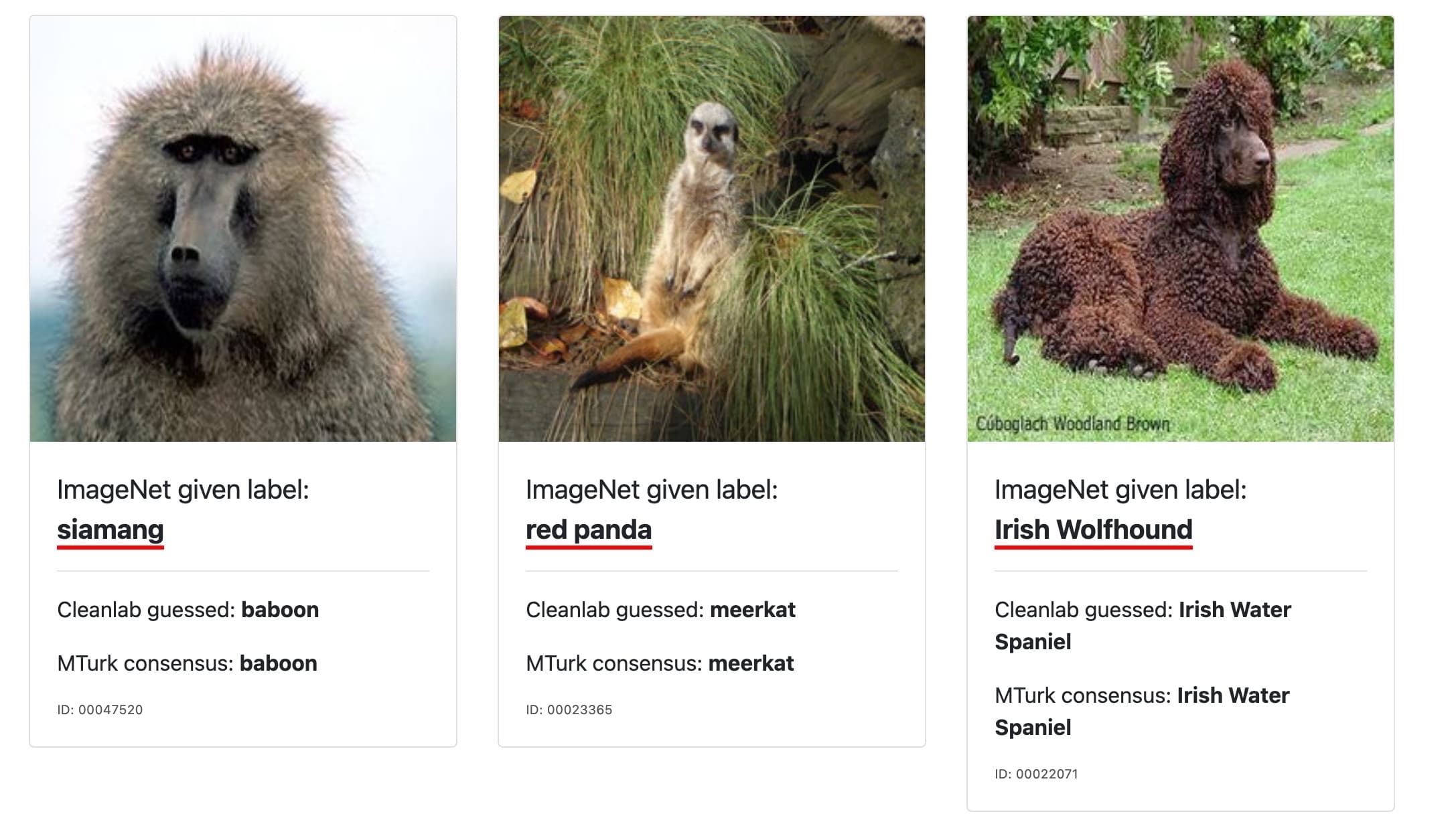
Let’s delve into the multitude of problems that these inaccuracies bring about and explore how to navigate this intricate terrain.
Unraveling the Impact of Mislabeled Data
In the intricate world of AI, data quality reigns supreme. Mislabeled data can trigger a cascade of challenges, ranging from financial burdens to eroding trust in AI systems. Here’s a closer look at the domino effect of poor data labeling.
Compromised Model Performance
Mislabeled data directly undermines the efficiency of AI systems. For instance, envision an e-commerce algorithm misjudging customer preferences due to flawed data or a legal AI tool making erroneous interpretations. These are not mere technical glitches; they have tangible repercussions in the real world, some of which can cost millions of dollars and thousands of working hours.
Increased Costs and Time Delays
Mislabeled data becomes a financial drain. Rectifying these errors requires substantial resources, and once identified, AI models often need to undergo retraining. This not only inflates budgets but also extends project timelines significantly.
Erosion of Trust
Beyond the tangible impacts, there is an intangible yet crucial cost: trust. When AI systems falter due to poor data, the confidence of end-users, clients, or stakeholders can quickly erode. Instances exist where a single data labeling mistake has cast long shadows of doubt over entire AI initiatives.
Ethical Implications
Mislabeled data transcends technical hiccups; it carries significant ethical implications. At the core of modern AI systems, the training data plays a pivotal role in shaping the system’s behavior. When this data is mislabeled, it can unintentionally introduce or amplify biases.
For example, if an AI model designed for hiring processes is trained on data containing gender or racial biases due to mislabeling, the resulting model might favor certain groups over others. This not only reflects poorly on the company using the AI but also perpetuates societal inequalities, making it harder for marginalized groups to access employment opportunities.
Consider, for instance, Amazon’s scrapped recruiting algorithm that prioritized men, because women were less common in the training data. Or, Google’s image recognition blunder, which classified some black people as gorillas. In the worst case scenarios, healthcare algorithms tell patients damaging advice and self-driving cars fail to protect their drivers.
Data Annotation: The Heartbeat of AI Training
Data annotation assumes a pivotal role in training artificial intelligence systems. It transforms raw, ambiguous data into a structured format that AI algorithms can comprehend and utilize. Just as a student requires precise instructions to grasp a concept, AI models need accurately labeled data to function optimally.
At its core, data annotation is about guiding AI through a sea of information. Properly annotated data enables AI to:
- Discern patterns
- Make accurate predictions
- Respond appropriately to new inputs
For example, an accurately labeled image of a cat ensures that AI recognizes similar images as cats in the future. If the labeling is inaccurate, the AI might misidentify a lion or a tiger as a cat. Such small errors can escalate quickly in real-world scenarios. For instance, in the medical field, a mislabeled X-ray could lead to incorrect diagnoses, jeopardizing patient health.
Common Pitfalls in Data Annotation
Mistakes in data annotation, often stemming from human error or oversight, can have significant repercussions. For example, annotators might sometimes label data based on their personal biases. A dataset intended to recognize faces might be heavily skewed toward a particular ethnicity, making the AI less accurate for faces outside that ethnic group.
Another common pitfall is inconsistency in labeling (examples shown here). If multiple people annotate a dataset without proper coordination or guidelines, the AI receives mixed signals, leading to reduced performance. The key is to maintain a rigorous, consistent, and unbiased approach to data annotation. This guarantees that AI models are both accurate and fair in their outcomes.
Best Practices for Data Annotation
In the age of Big Data and AI the significance of data annotation cannot be understated. Properly annotated data paves the way for accurate machine learning models. But how can we ensure that our data is annotated correctly? Let’s explore some best practices.
Setting Clear Guidelines
Setting clear guidelines lies at the heart of accurate data annotation. When annotators know precisely what’s expected, they are more likely to label data correctly. Guidelines serve as a road map: without a clear path, anyone can get lost. For instance, when labeling images of animals, guidelines should specify differences between similar species, like leopards and cheetahs, rather than providing vague instructions like “label the big cats.”
Iterative Feedback Loops
Feedback plays a crucial role in refining data annotation. Continuous feedback loops allow annotators to receive regular input on their work, enabling them to make immediate corrections. This process isn’t just about pointing out mistakes; it’s an opportunity for learning and growth. In the realm of AI, a data-centric approach emphasizes refining annotations over time, fostering a continuous learning and improvement cycle for both humans and machines.
Leveraging Automated Tools
Automation can be a game-changer in data labeling. Various tools are designed to expedite the annotation process. For example, some tools can auto-detect objects in images, allowing human annotators to review and refine the labels instead of starting from scratch. However, it’s crucial to strike a balance; while automation can handle vast amounts of data quickly, human judgment is essential to catch nuances and context that machines might miss. It’s like using a GPS; it can guide you most of the way, but sometimes you need to look out the window to ensure you’re on the right path.
Fixing Bad Data: Proactive and Reactive Measures
To address bad data, your team must employ several methods, including proactive and reactive measures. Here are some industry best practices.
Data Audits
In the fast-paced world of data analysis and machine learning, data accuracy underpins every decision. For sectors like legal firms, precision takes on heightened significance. A minor data oversight can lead to legal misjudgments, impacting a firm’s reputation and finances. Regular data audits become indispensable. These systematic checks and validations
help organizations sift through vast data repositories, identifying anomalies and inconsistencies. Scheduled audits not only maintain data quality but also act as a preventive measure against potential future errors.
Correction Frameworks
Identifying errors is only half the battle; the real challenge often lies in rectifying them efficiently. Correction frameworks prove invaluable in this regard. Equipped with advanced algorithms, these tools delve deep into the data, pinpointing mislabeled or inconsistent entries. They offer robust methods and protocols to correct these anomalies, ensuring data reliability is restored. With the growth of AI and machine learning, these tools continue to evolve, making them even more effective in maintaining data integrity.
Collaborative Effort
The complexity of today’s data ecosystem means that no single individual or specialized team can fully grasp all nuances. Addressing data inaccuracies requires a multi-disciplinary approach. Data scientists bring expertise in handling and analyzing large datasets, while machine learning engineers spot patterns and inconsistencies. Domain experts, with in-depth knowledge of specific fields, provide context and a deeper understanding of real-world data implications. Collaboration among these experts enhances the chances of spotting, understanding, and rectifying data errors.
Training and Quality Control for Data Annotators
In data annotation, humans play a pivotal role. The decisions annotators make while labeling data directly influence AI model outcomes. Equipping annotators with the necessary knowledge and skills is paramount. Structured training programs introduce annotators to the nuances of the specific data they will handle. For instance, if the task involves labeling images for a self-driving car’s AI, annotators must understand various road scenarios, signs, and potential obstacles. Training standardizes the annotation process, ensuring consistency among annotators and reducing disparities in data labeling.
Outsourcing Data Annotation: Pros and Cons
The demand for high-quality, accurately labeled data has surged in recent years, particularly with the proliferation of AI and machine learning applications. This demand has given rise to companies specializing in data annotation services. These firms, equipped with expertise and specialized tools, offer businesses the opportunity to offload the intricate task of data labeling, ensuring that AI models receive the best possible data.
Benefits of Outsourcing
When debating between outsourcing and in-house annotation, various facets come into play. Outsourcing offers several advantages. Firms often boast seasoned teams of experts adept at data annotation across diverse sectors. They provide scalability, a boon for projects demanding the processing of vast data volumes within tight deadlines. From a financial standpoint, outsourcing frequently emerges as the more economical choice in the long run. It eliminates the need for substantial investments in in-house infrastructure and continuous personnel training. Additionally, it allows businesses to focus on their core operations while entrusting data annotation to seasoned professionals.
Drawbacks of Outsourcing
However, outsourcing comes with its challenges. Companies might grapple with a perceived loss of control over the data annotation process. Entrusting sensitive data to third-party vendors can raise concerns regarding data security and privacy. While many annotation firms pledge top-notch quality, there’s an inherent risk of encountering variability in standards across different vendors.
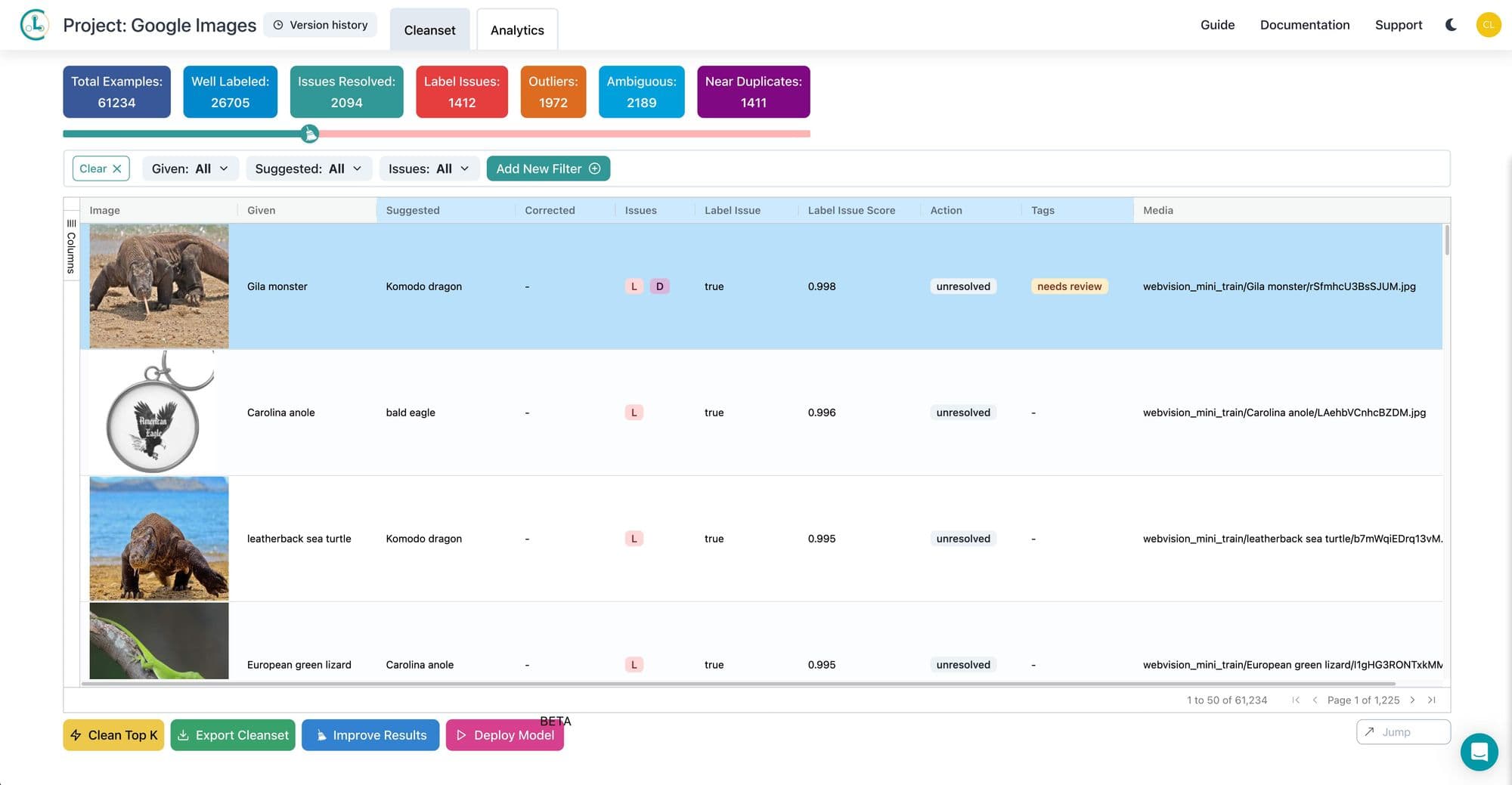
Cleanlab: Conquering Mislabeled Data
In the expansive realm of data-driven decision-making, Cleanlab stands as an innovative solution that saves teams time and money. Our automated data curation solution aims to enhance the value of every data point in enterprise AI, large language models (LLMs), and analytics solutions.
Here’s how Cleanlab addresses common challenges.
Automated Data Curation
Cleanlab’s platform is not merely about collecting data; it’s about curating it. Their solution adds smart metadata automatically, transforming messy real-world data into actionable insights for various models. This enhances the reliability of enterprise analytics and reduces the need for costly data quality and annotation processes for a significant portion of the data.
Diverse Clientele and Applications
Cleanlab’s versatility is evident in its clientele, ranging from tech giants like Google and Oracle to innovative startups like ByteDance and HuggingFace. Many rely on Cleanlab to identify and rectify issues in their structured and unstructured datasets. Whether it’s tagging chatbot text data or analyzing visual navigation data, Cleanlab enhances the value of every data point by automatically pinpointing and correcting outliers, ambiguous data, and mislabeled entries.
Real-World Impact
Cleanlab doesn’t merely offer technology; it delivers results. Their platform has demonstrated tangible benefits, including improvements in accuracy, reductions in labeled transactions required for training models, and significant cost savings for enterprises.
Navigating the Data Maze with Confidence
In the intricate dance of AI and machine learning, data quality takes center stage. Mislabeled data can be a silent saboteur, undermining the potential of even the most advanced algorithms. With the rise of dedicated data annotation services like Cleanlab, businesses have a trusted ally in their corner.
Cleanlab’s commitment to precision, innovation, and real-world impact ensures that enterprises can confidently navigate the challenges of data curation, turning potential pitfalls into opportunities for growth.
Cleanlab Studio is the fastest no-code Data-Centric AI platform to turn messy raw data into reliable AI/ML/Analytics. Try it to see why thousands of engineers, data scientists/analysts, and data annotation/management teams use Cleanlab software to algorithmically improve the quality of their image/text/tabular datasets.
- Get started with Cleanlab Studio for free!
- Join our Community Slack to discuss how you’re practicing Data-Centric AI and learn from others.
- Follow us on LinkedIn or Twitter to stay up-to-date on new techniques being invented in Data-Centric AI.