Data is the lifeblood of AI and analytics. There’s a modern-day arms race for data. Giants like OpenAI’s GPT-4, Anthropic’s Claude, and X.AI’s Grok are all vying for more data, the key ingredient for AI advancement.
Yet, it’s not just the quantity of data that matters, but its quality. High-quality, meticulously curated data is critical. Without it, even the most sophisticated AI algorithms can miss the mark in delivering meaningful insights.

Consider, for instance, Amazon’s scrapped recruiting algorithm that prioritized men, because women were less common in the training data. Or, Google’s image recognition blunder, which classified some black people as gorillas. In the worst case scenarios, healthcare algorithms tell patients damaging advice and self-driving cars fail to protect their drivers.
In each of these cases, a lack of data curation, and more broadly a lack of data-centric AI, led to poor outcomes.
As data volumes continue to explode across enterprises, robust data curation practices have become absolutely essential to realizing value from AI and analytics investments. This article explores modern techniques and leading practices for curating massive datasets to power cutting-edge analytics.
Preparing Data at Scale for AI Models
The latest breakthroughs in AI, particularly in natural language processing, have shown that model performance scales with dataset size. Models like GPT-4 have billions of parameters that require trillion-token datasets for training. Curating datasets of this size presents immense computational challenges. Tools like NVIDIA NeMo Data Curator, Lilac, and Lightly have been developed to build better data pipelines.
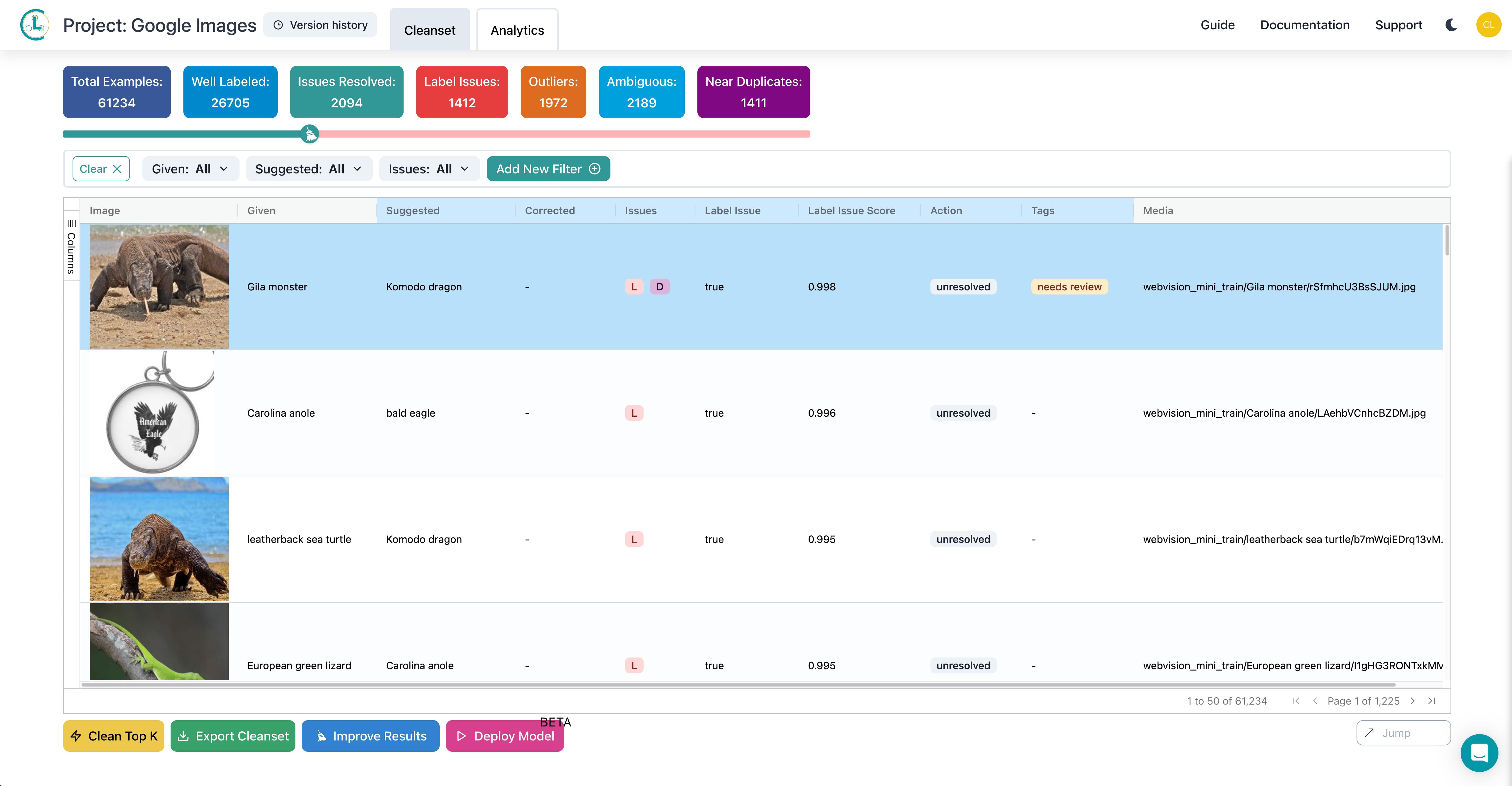
Cleanlab is another tool that helps businesses curate high-quality data. With minimal manual work, engineers can find and fix label issues, outliers, ambiguous labels, near duplicates, and more.

While scale matters, quality is equally important when curating data for AI. Datasets often contain biases and quality issues that are not obvious from aggregate statistics. This makes interactive visualization and exploration critical.
Taken together, these capabilities offer unprecedented visibility into AI training data. As more industries look to train gigantic foundation models, scalable data curation will only grow in importance.
Managing Data Like a Product
To maximize business impact from analytics, enterprises need to take a product-centric view towards data. This means proactively building reusable data assets that support diverse analytics use cases across the organization.
Concretely, this translates to creating standardized data products around key business entities like customers, products, stores etc. Each data product provides a 360 degree view of the entity delivered via APIs tailored to different consumption patterns. Security, governance and metadata standards ensure seamless access to trustworthy data.
Dedicated data producer teams are responsible for continuing improvement of data products based on user feedback. This product-centric operating model ends up being far more efficient than traditional approaches of custom-building data pipelines for every new analysis request.
Data products also enable advanced techniques like digital twins which are virtual replicas of real world systems. By simulating engineering systems like buildings or factories, digital twins drive innovations like reduced time-to-market for new products. None of this is possible without high-quality data products.
Curation Techniques for Diverse, Balanced Data
For many AI use cases, dataset diversity and balance are just as crucial as scale. Real world distributions tend to have long tails which can shortchange less frequent instances. Images used for autonomous vehicle training provide a prime example.
To ensure adequate coverage, data curation workflows need to draw data from a breadth of sources. For unstructured data varieties like images and text, AI can help select representative samples programmatically.
Techniques like data augmentation synthetically generate additional training examples by applying transformations like crops, brightness changes etc. Generative adversarial networks can produce entirely new realistic samples for domains like faces and landscapes.
Finally, algorithms like re-weighting and resampling can counter representation imbalances by boosting underrepresented instances. With the right curation toolkit, even multi-modal datasets with images, audio and text can be tuned for diversity.
Curation for Biases and Errors
In addition to overall quality and balance, curation practices need to focus on addressing biases that creep into real-world data. Societal biases present in the human labelling process often get amplified by AI models.
Data documentation that captures provenance and context is crucial for identifying such issues. Human-in-the-loop workflows then allow iterative data refinement based on model performance on different population groups.
As mentioned, tools like Lilac enable building custom bias detectors tailored to specific use cases. For example, a concept classifier trained to identify toxic language can help prune problematic training instances.
On the storage side, versioned data lakes keep track of data lineage and changes over time. When errors are discovered in a dataset, this allows tracing the root cause and retraining models with corrected data.
Continuous curation aligned with changing model requirements helps make business-critical AI more robust and fair.
The Role of Self-Supervised Learning
Traditional supervised learning depends heavily on large volumes of human-annotated data. For many real-world problems, procuring such labelled data can be prohibitively expensive. This has sparked great interest in self-supervised learning techniques which extract supervisory signals from the data itself.
By pre-training models to solve proxy tasks like image colorization and text infilling, self-supervision delivers high-quality feature representations.
And, automatically-generated labels can kickstart the training process without any manual data annotation. Combining self-supervised pre-training with small amounts of labelled fine-tuning data leads to dramatic reductions in human effort.
This semi-supervised paradigm makes deep learning viable for a much wider range of applications. The automated curation techniques also help scale up dataset sizes. Together these innovations expand the frontiers of applied AI.
Curation for Continuous Improvement
With data being generated at ever-increasing rates, curation can no longer be a one-time pre-processing step. All analytics systems need to incorporate continuous curation feedback loops for sustained value.
Automated workflow triggers can initiate curation pipelines in response to certain events. For instance, a drop in prediction accuracy for an e-commerce demand forecasting model could trigger additional data collection around the affected product categories.
Concept drift detectors can identify when training data characteristics start to mismatch deployed model requirements. This proactively flags the need for model retraining or fine-tuning.
Data quality dashboards make monitoring easier by displaying metadata like freshness, completeness and relevance scores. Tight integration between data infrastructure and ML platforms is key to enabling robust continuous curation.
Extending Curation to Edge Devices
As IoT and edge computing take off, an exponential number of sensors and devices are generating data outside the centralized cloud or data center. Much of this data will never make it to enterprise data warehouses because of connectivity, cost or privacy constraints. Yet this data holds tremendous potential for analytics use cases like predictive maintenance.
This presents a major challenge: how to effectively curate data at the edge before it is ingested into ML models? Edge compute offers a powerful solution for intermediate cleansing, aggregation, integration and compression. Small footprint data curation microservices can run on edge gateways or directly on connected devices with hardware acceleration.
Curated extracts are asynchronously synced upstream when connectivity allows. Federated learning techniques further help train ML models without transferring raw data. Together these innovations will expand the reach of data curation to the farthest edges of enterprise networks.
Conclusion
With data volumes and model complexity both soaring to unprecedented levels, rigorous data curation has become indispensable for impactful AI and analytics. Leading practices like distributed processing, interactive enrichment, self-supervision and continuous feedback are essential building blocks for successfully leveraging massive datasets.
Tools that democratize access to scalable, reliable and fair data products unblock wider business adoption. Looking ahead, the scope of curation will continue expanding to new modalities like video and audio while also addressing decentralized edge environments. With data as the raw material, curation delivers the necessary quality, consistency and trust for transformative AI.
Cleanlab Studio is an automated no-code Data Curation platform to turn messy raw data into reliable AI/ML/Analytics. Try it to see why thousands of engineers, data scientists/analysts, and data annotation/management teams use Cleanlab software to algorithmically improve the quality of their image/text/tabular datasets.
- Get started with Cleanlab Studio for free!
- Join our Community Slack to discuss how you’re practicing data curation and learn from others.
- Follow us on LinkedIn or Twitter to stay up-to-date on new techniques being invented for algorithmic data curation.