While you may grasp the significance of a high-quality data scheme intellectually, applying this abstract concept to concrete business management endeavors is often overlooked.
Recent research indicates that a staggering 94% of businesses acknowledge inaccuracies in their customer databases. Astonishingly, many choose to dismiss this issue and take no action. This has a chilling real-world impact on B2B organizations, as poor-quality data consumes approximately 27% of their sales representatives’ valuable time.

Read on to delve into the intricacies of data correction and discover how you can effectively eliminate data inaccuracies.
Understanding Data Correction
Data correction involves rectifying inaccuracies and inconsistencies within a dataset, ensuring that all entries are accurate and truthful. It primarily focuses on rectifying specific errors identified in the data. This process differs from the more commonly known data correction , which involves the removal or addition of irrelevant, improperly formatted, or missing data to create a uniform and coherent dataset, suitable for efficient processing and analysis.
“Bad data” encompasses various data inaccuracies, ranging from initial errors to outdated information. Examples of bad data include corrupted files, obsolete phone numbers, misspelled client names, outdated business models, and errors stemming from services like Amazon Mechanical Turk.
Data correction involves identifying data errors and subsequently making necessary alterations. Often, this entails deleting unnecessary data or updating outdated information to ensure more precise intelligence and analytics.
The ultimate goal is to prepare datasets for business intelligence processes. After data correction, you gain the capability to employ accurate, up-to-date data analytics, enabling you to enhance your business operations and systems. This eliminates the risk of making ill-informed decisions based on low-quality data and saves money by avoiding futile attempts to reach leads with misspelled names or outdated contact information.
Advantages for Your Data Management System
Successful businesses rely on data for informed decision-making. When data is incomplete, inaccurate, or entirely incorrect, it leads to poor decision-making due to subpar data quality. Consequently, decisions regarding the allocation of sales and marketing efforts become challenging, potentially resulting in ineffective follow-ups with leads and vendors.
Data correction also has the potential to save your business significant time and money. Poor-quality data costs businesses in the United States over $3 trillion annually, making it imperative to minimize its impact on your enterprise.
Working with flawed data forces representatives to invest time in creating inaccurate visualizations and manually identifying and rectifying errors. This manual process can be costly, as employees meticulously inspect each data point.
Reducing errors in your data also alleviates employee frustration by eliminating tedious busywork from their daily routines.
Clients and customers also benefit from the removal of data inaccuracies. Clear and accurate data enables better communication and tailored content delivery, leading to improved customer satisfaction.
Many datasets serve as research on your target market, their values, and pain points. Accurate assessment allows you to fine-tune your business efforts to cater to your audience effectively, resulting in a more content target market and increased revenue.
Moreover, most industries adhere to data collection and storage standards. Failure to address bad data can lead to non-compliance with regulations and significant real-world consequences. For instance, a healthcare-related business could make incorrect treatment decisions and produce subpar pharmaceuticals, jeopardizing compliance.
A Step-By-Step Guide to Data Correction
Manual data correction presents several challenges, requiring your team to meticulously assess all data points. This research-intensive process can span weeks or even months, increasing the likelihood of human error and potentially exacerbating data issues.

This is where high-quality data management software becomes invaluable in simplifying the data correction process.
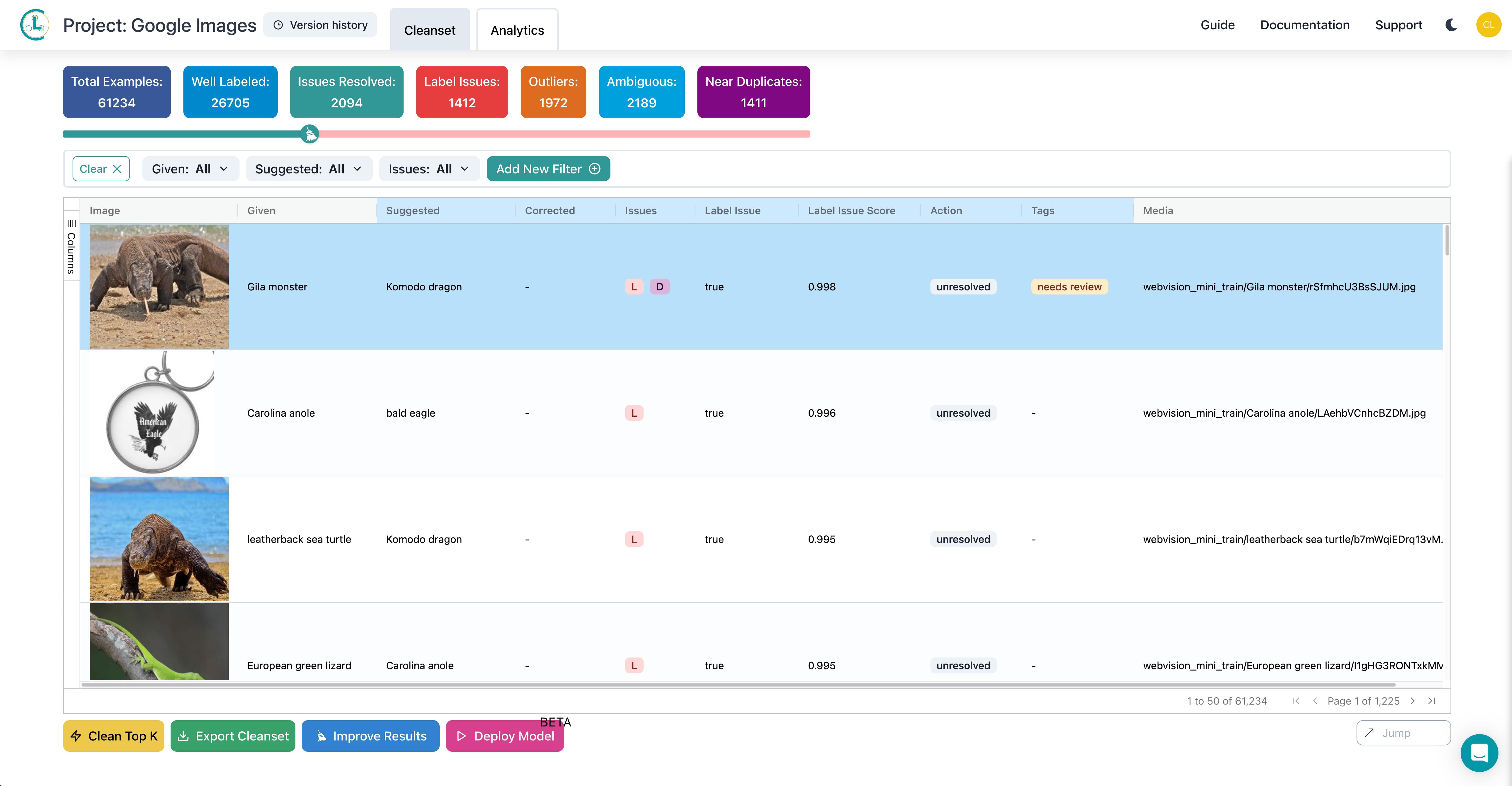
Cleanlab’s AI software swiftly scans your datasets, identifying all errors automatically. It detects incorrect data entries and flags them for your attention, streamlining error identification. Additionally, the software examines metadata linked to data points, such as image/video tags.
In addition to identifying errors, Cleanlab’s cutting-edge software rectifies them, providing a comprehensive data correction solution.
1. Addressing Incomplete Data
Incomplete data is a common issue. Suppose you have a client contact form with fields for lead names, business organization, phone numbers, addresses, and emails. You possess complete information for all leads except two. One lead lacks contact information entirely, rendering it useless and eligible for deletion. The other lead has all pertinent fields except an email address.
To maintain accuracy in your tracking system and email campaigns, you need to handle incomplete data appropriately. The lead with missing contact information should be deleted. For the lead missing only an email address, you may consider including them in a separate dataset focused on names and phone numbers if cold calling is part of your strategy. This ensures accurate client behavior assessment.
2. Eliminating Duplicate Data Points
Duplicate data points can significantly skew business insights. For example, tracking email open rates may inadvertently record a client as opening the same email multiple times, leading to inaccurate averages.
Cleanlab’s AI software identifies duplicate data points, enabling you to remove them efficiently and enhance the accuracy of your analytics.
3. Correcting Labeling Errors
Data labeling, also known as data annotation, is a crucial aspect of organizing datasets. It involves assigning contextual labels to raw data for categorization. Correct labeling is essential for developing machine learning (ML) models and enhancing data organization.
Cleanlab’s technology aids in correcting existing labeling errors, simplifying the management and organization of data according to best practices. This can be something like an image of a “dog” misclassified as a “cat” which would harm model performance and downstream analytics.
4. Harnessing Machine Learning Strategies
Machine learning models play a pivotal role in identifying errors and improving data quality. AI can automatically detect and rectify issues in datasets, ensuring that poor-quality data does not compromise the integrity of your analyses.
Machine learning also enables the generation of visual representations of data, such as charts, spreadsheets, and graphs, facilitating informed data-backed decisions in various aspects of your business operations.
Additionally, machine learning allows for the consolidation of disparate data sources, reducing redundancy and enhancing the efficiency of data analysis.
5. Standardizing Data
After addressing discrepancies and outliers, standardizing data in a uniform manner is essential. Standardization enhances data consistency, readability, and compatibility with AI and machine learning models that classify and contextualize data.
For instance, if you have American and British employees recording dates differently (e.g., MM/DD/YY vs. DD/MM/YYYY), standardizing the format ensures data uniformity, simplifying data analysis and storage.
The Right Way to Rectify Data Inaccuracies
Data correction is a straightforward process with the potential to save time, money, and reduce stress. Now that you understand how it can elevate both data quality and your business, it’s time to take action.
Cleanlab Studio is the fastest no-code Data-Centric AI platform to turn messy raw data into reliable AI/ML/Analytics. Try it to see why thousands of engineers, data scientists/analysts, and data annotation/management teams use Cleanlab software to algorithmically improve the quality of their image/text/tabular datasets.
- Get started with Cleanlab Studio for free!
- Join our Community Slack to discuss how you’re practicing Data-Centric AI and learn from others.
- Follow us on LinkedIn or Twitter to stay up-to-date on new techniques being invented in Data-Centric AI.