



The Trustworthy Language Model (TLM) scores the trustworthiness of responses from any LLM to catch hallucinations/errors in real-time. While other hallucination-detection methods exist, a true test of such capabilities is whether you can utilize them to automatically generate more accurate LLM responses.
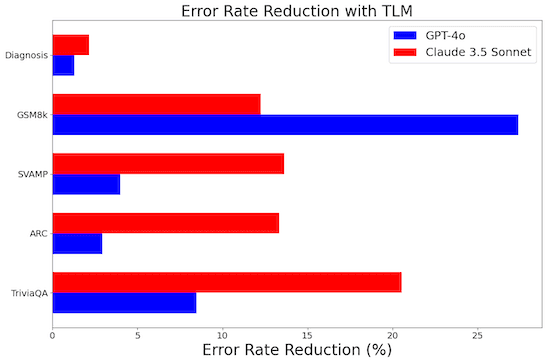
Built on top of any base LLM, the TLM system can boost response accuracy without introducing any additional LLM model. This article benchmarks TLM systems built on top of different base models, revealing that the TLM system can reduce the error rate (incorrect answers): of GPT-4o by up to 27%, of GPT-4o mini by up to 34%, of GPT-4 by up to 10%, of GPT-3.5 by up to 22%, of Claude 3 Haiku by up to 24%, and of Claude 3.5 Sonnet by up to 20%, and of o1-preview by up to 20%. In each case, TLM’s improved responses over the base model come without altering prompts or relying on any LLM besides the base model.
| Dataset | GPT-4o | TLM |
|---|---|---|
| TriviaQA | 88.2% | 89.2% |
| ARC | 96.6% | 96.7% |
| SVAMP | 95.0% | 95.2% |
| GSM8k | 74.1% | 81.2% |
| Diagnosis | 68.9% | 69.3% |
The table above reports the accuracy of responses from OpenAI’s GPT-4o vs. TLM utilizing GPT-4o as its base model. Here GPT-4o is the only LLM model utilized in producing all responses for each dataset. Details of each benchmark dataset are presented further below.
Similarly, the table below reports the accuracy of responses from Claude Sonnet 3.5 vs. TLM utilizing Sonnet 3.5 as its base model. Here Sonnet 3.5 is the only LLM model utilized in producing all responses for each dataset.
| Dataset | Claude 3.5 Sonnet | TLM |
|---|---|---|
| TriviaQA | 81.5% | 85.3% |
| ARC | 94% | 94.8% |
| SVAMP | 95.6% | 96.2% |
| GSM8k | 95.1% | 95.7% |
| Diagnosis | 67.6% | 68.3% |
Results comparing the accuracy of OpenAI’s o1-preview model vs. TLM based on this model are additionally available here.
Across all datasets, we see the accuracy of TLM responses is consistently higher than the accuracy of the corresponding base LLM model. In each comparison of TLM vs. its corresponding base model, the TLM system solely utilizes this base LLM model – no other LLM model is involved in producing responses or scoring their trustworthiness. The prompts used for the base LLM model and TLM are identical in all cases.
Examples
Here are examples of benchmark questions incorrectly answered by GPT-4o, but correctly answered by TLM utilizing GPT-4o as its base model:
Question: What is a female gerbil called?
GPT-4o Response: A female gerbil is simply called a “female gerbil.” Unlike some other animals, gerbils do not have specific names for males and females.
TLM Response: A female gerbil is simply called a “doe.”
Question: Jean is two years older than Mark. Two years ago Mark was 5 years older than half Jan’s age. If Jan is 30 how old is Jean?
GPT-4o Response:
TLM Response:
Here are examples of benchmark questions incorrectly answered by Claude 3.5 Sonnet, but correctly answered by TLM utilizing Claude 3.5 Sonnet as its base model:
Question: Which element below is found in the smallest quantity in most living things? (A) iron (B) carbon (C) nitrogen (D) hydrogen Please restrict your answer to one letter from A to D and nothing else.
Claude 3.5 Sonnet Response: C
TLM Response: A
Question: Matthew gave equal numbers of crackers and cakes to his 4 friends. If he had 32 crackers and 98 cakes initially how many crackers did each person eat?
Claude 3.5 Sonnet Response:
TLM Response:
Benchmark Details
Here’s the code used to run TLM in our benchmark, in this case using GPT 4o as the base LLM model:
Our benchmark considers popular Q&A datasets:
- TriviaQA: Open-domain trivia questions.
- ARC: Grade school multiple-choice questions (we consider the “Challenge Test” subset).
- SVAMP: Elementary-level math word problems.
- GSM8k: Grade school math problems.
- Diagnosis: Classifying medical conditions based on symptom descriptions from patients.
Benchmarking challenges include: the open-domain nature of many questions, and some errors in the listed ground-truth answers. Thus, our benchmark subsets certain datasets by filtering out examples whose ground-truth answer is wrong or could not be verified. Additional benchmarking details are listed here.
Discussion
Many folks know that TLM offers state-of-the-art real-time hallucination detection for responses from any LLM. However, fewer folks are aware that TLM can be used to produce more accurate responses than any LLM – all without relying on another model. Simply set quality_preset = "best" in your TLM code, and the system will automatically improve answers from its base LLM.
Internally, the TLM system works like this to improve responses: sample multiple candidate responses from the base LLM, score their trustworthiness, and then return the most trustworthy response. This simple approach can only be effective if the trustworthiness scores reliably separate correct vs. incorrect LLM responses. Unlike other hallucination detection models, TLM can actually improve arbitrary LLM responses in this fashion – strong evidence for the generalizability of TLM’s hallucination detection capabilities.
Of course, there’s no free lunch. The improved accuracy of TLM responses requires slightly longer runtimes than the base LLM model. TLM using the accuracy-improving "best" quality_preset is thus best-suited for applications like: data processing or LLM automation of your team’s manual work. For latency-sensitive chat applications, we recommend using a lower TLM quality_preset (like "medium" or "base"), which enables you to flag incorrect/hallucinated responses in real-time.
Next Steps
-
Get started with the TLM API and run through various tutorials. Specify which base LLM model to use via the TLMOptions argument – all of the models listed in this article (and more) are supported out-of-the-box. Specify TLM’s
bestquality_preset to maximally boost response accuracy. -
Refer to our original blogpost to learn more about TLM and see additional benchmarks.
-
This article showcased the generality of TLM across various base LLM models that our public API provides out-of-the-box. If you’d like a (private) version of TLM based on your own custom LLM, get in touch!