

Reliable model evaluation lies at the heart of MLops and LLMops, guiding crucial decisions like which model or prompt to deploy (and whether to deploy at all). In this article, we prompt the FLAN-T5 LLM from Google Research with various prompts in an effort to classify text as polite or impolite. Amongst the prompt candidates, we find the prompts that appear to perform best based on observed test accuracy are often actually worse than other prompt candidates. A closer review of the test data reveals this is due to unreliable annotations. In real-world applications, you may choose suboptimal prompts for your LLM (or make other suboptimal choices guided by model evaluation) unless you clean your test data to ensure it is reliable.
While the harms of noisy annotations are well-characterized in training data, this article demonstrates their often-overlooked consequences in test data.
Overview
This article studies a binary classification variant of the Stanford Politeness Dataset, which has text phrases labeled as polite or impolite. We evaluate models using a fixed test dataset containing 700 phrases. Here we consider two possible test sets constructed out of the same set of text examples which only differ in some (~30%) of the labels. Representing typical data you’d use to evaluate accuracy, one version has labels sourced from a single annotation (human rater) per example, and we report the accuracy of model predictions computed on this version as Observed Test Accuracy. A second cleaner version of this same test set has high-quality labels established via consensus amongst many agreeing annotations per example (derived from multiple human raters). We report accuracy measured on the cleaner version as Clean Test Accuracy. Thus, Clean Test Accuracy more closely reflects what you care about (actual model deployment performance), but the Observed Test Accuracy is all you get to observe in most applications — unless you first clean your test data!
You can download the data here.

Below are two test examples where the single human annotator mislabeled the example, but the group of many human annotators agreed on the correct label.
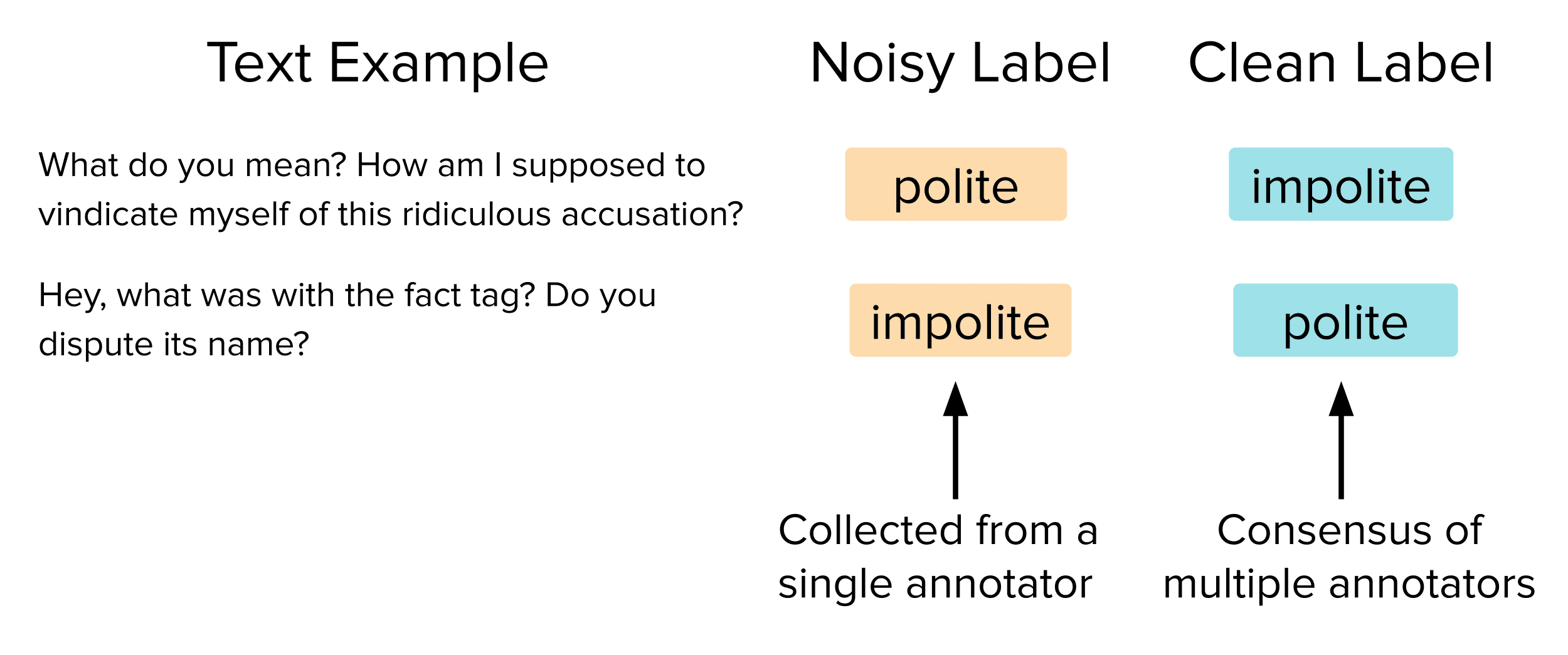
In real-world projects, you often don’t have access to such “clean” labels, so you can only measure Observed Test Accuracy. If you are making critical decisions such as which LLM or prompt to use based on this metric, be sure to first verify the labels are high-quality (via software like cleanlab). Otherwise, we find you may make the wrong decisions, as observed below when selecting prompts for politeness classification.
Impact of Noisy Evaluation Data
As a predictive model to classify the politeness of text, it is natural to employ a pretrained Large Language Model (LLM). Here, we specifically use data scientists’ favorite LLM — the open-source FLAN-T5 model. To get this LLM to accurately predict the politeness of text, we must feed it just the right prompts. Prompt engineering can be very sensitive with small changes greatly affecting accuracy!
Prompts A and B shown below (highlighted text) are two different examples of chain-of-thought prompts, that can be appended in front of any text sample in order to get the LLM to classify its politeness. These prompts combine few-shot and instruction prompts (details later) that provide examples, the correct response, and a justification that encourages the LLM to explain its reasoning. The only difference between these two prompts is the highlighted text that is actually eliciting a response from the LLM. The few-shot examples and reasoning remain the same.
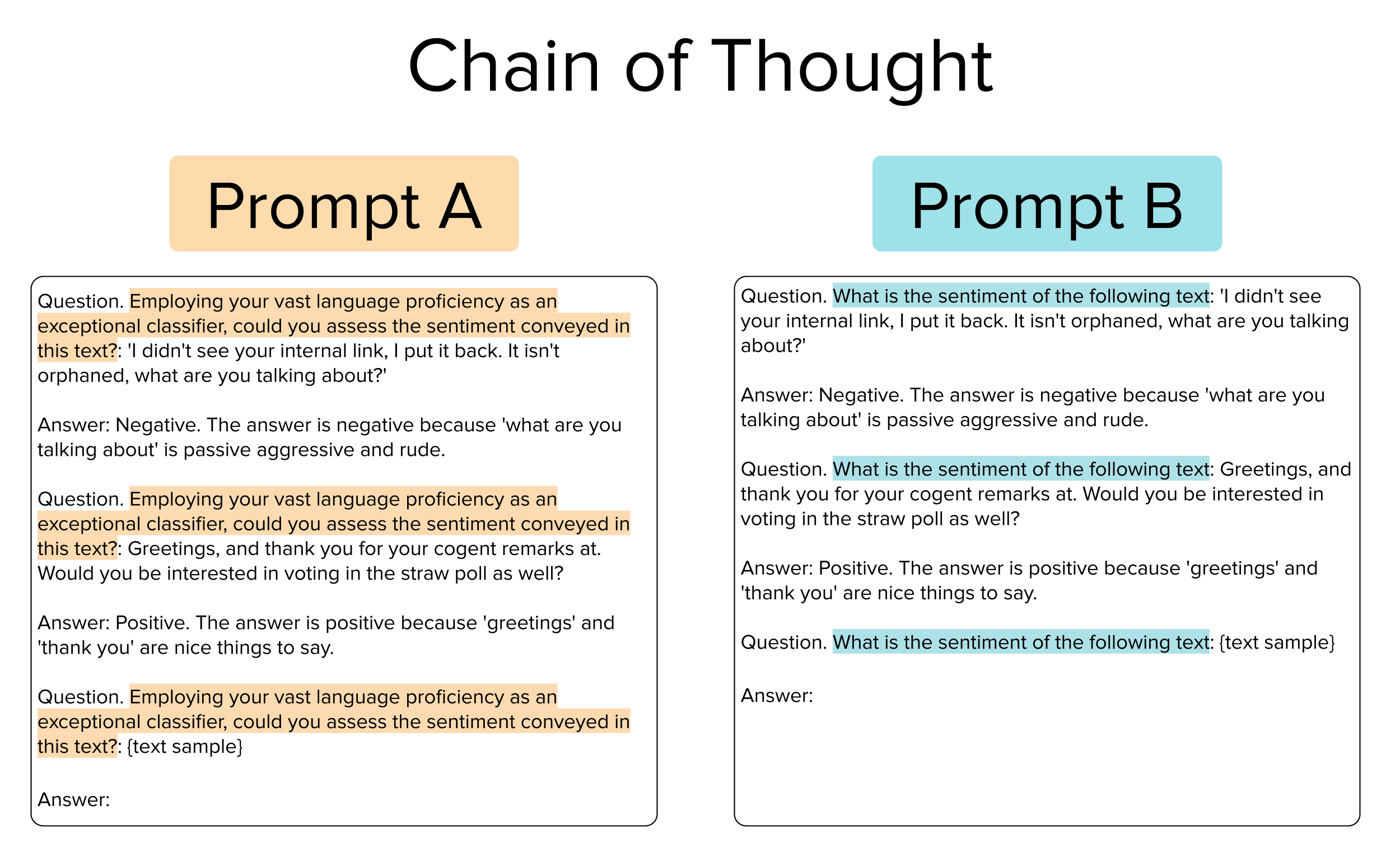
The natural way to decide which prompt is better is based on their Observed Test Accuracy. When used to prompt the FLAN-T5 LLM, we see below that the classifications produced by Prompt A have higher Observed Test Accuracy on the original test set than those from Prompt B. So obviously we should deploy our LLM with Prompt A, right? Not so fast!
When we assess the Clean Test Accuracy of each prompt, we find that Prompt B is actually much better than Prompt A (by 4.5 percentage points). Since Clean Test Accuracy more closely reflects the true performance we actually care about, we would’ve made the wrong decision if just relying on the original test data without examining its label quality!

Is this just statistical fluctuations?
McNemar’s test is a recommended way to assess the statistical significance of reported differences in ML accuracy. When we apply this test to assess the 4.5% difference in Clean Test Accuracy between Prompt A vs. B over our 700 text examples, the difference is highly statistically significant (p-value = 0.007, X² = 7.086). Thus all evidence suggests Prompt B is a meaningfully better choice, we should not have failed to select it by carefully auditing our original test data!
Is this a fluke result that just happened to be the case for these two prompts?
Let’s look at other types of prompts as well to see if the results were just coincidental for our pair of chain-of-thought prompts.
Instruction Prompts
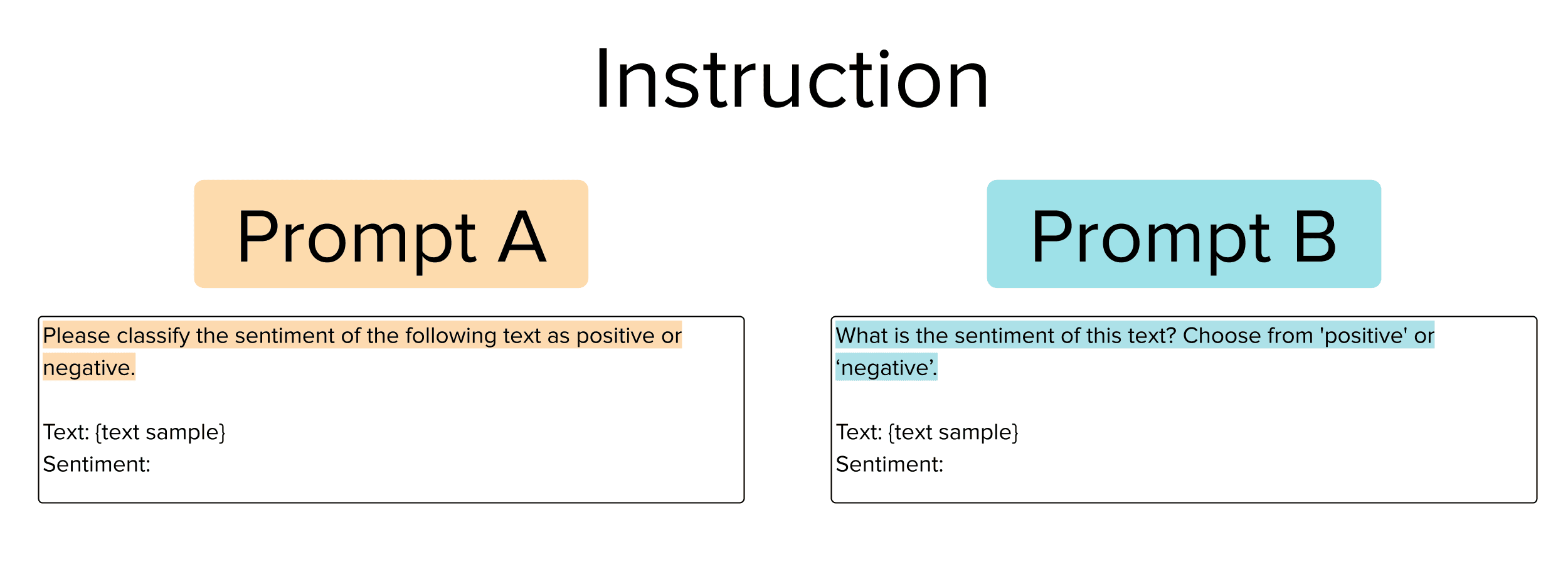
This type of prompt simply provides an instruction to the LLM on what it needs to do with the text example given. Consider the following pair of such prompts we might want to choose between.
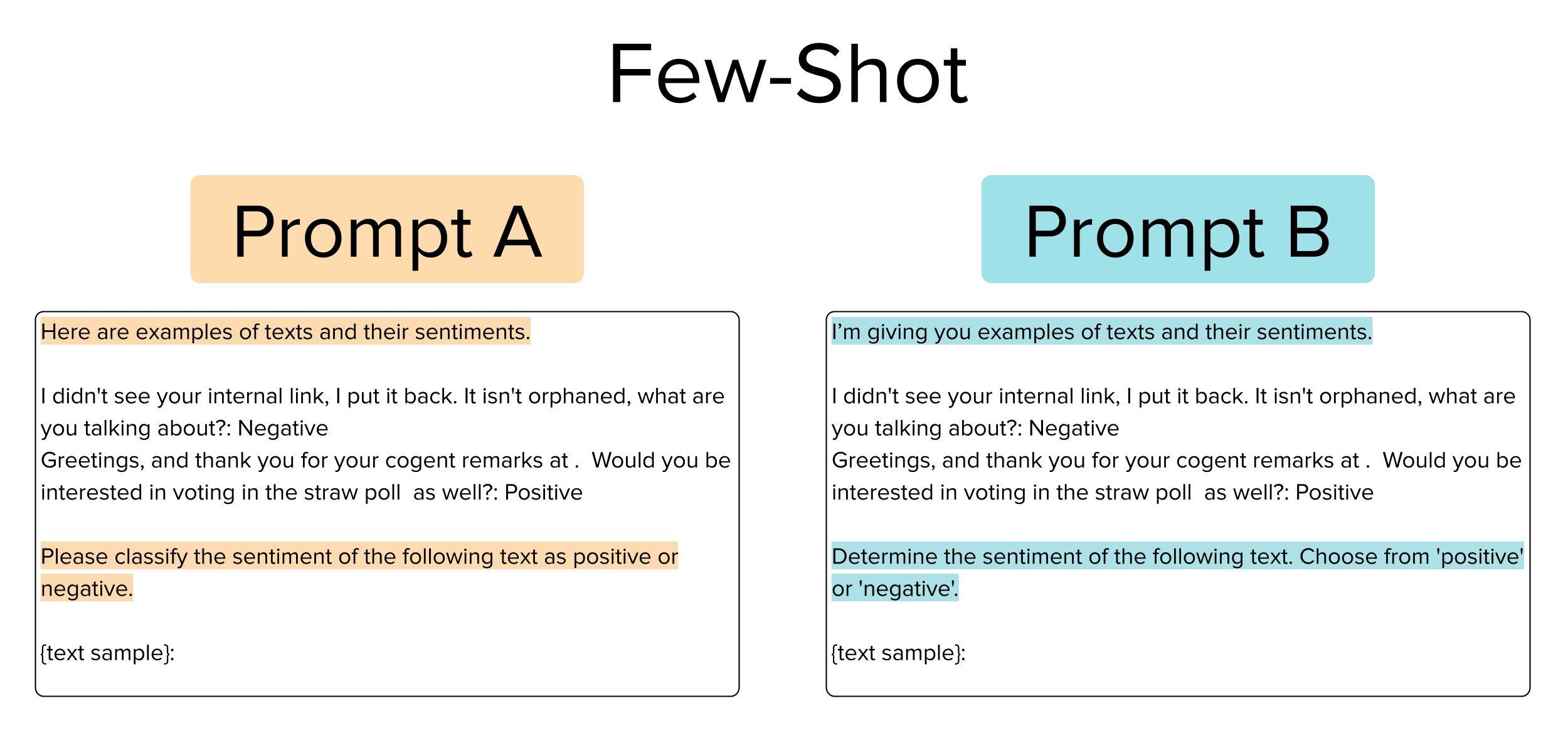
Few-Shot Prompts
This type of prompt uses two instructions*,* a prefix, and a suffix, and also includes two (pre-selected) examples from the text corpus to provide clear demonstrations to the LLM of the desired input-output mapping. Consider the following pair of such prompts we might want to choose between.
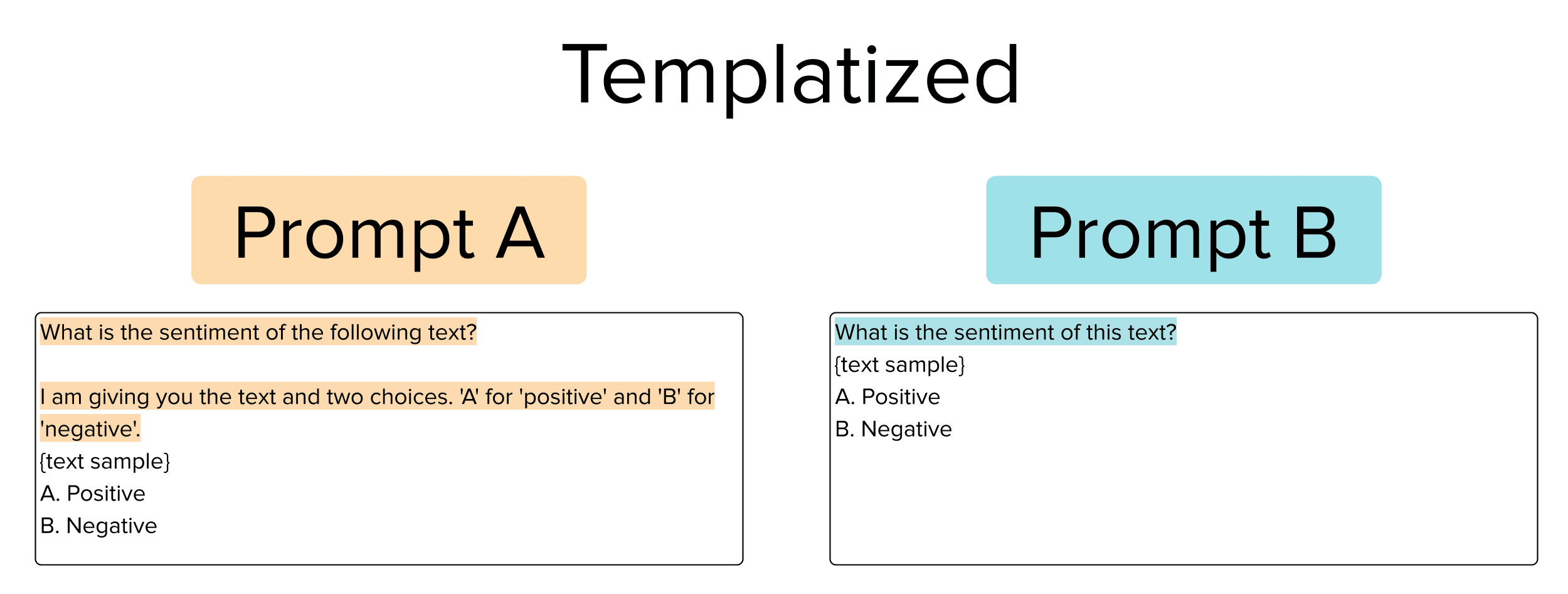
Templatized Prompts
This type of prompt uses two instructions*,* an optional prefix, and a suffix in addition to multiple-choice formatting so that the model performs classification as a multiple-choice answer rather than responding directly with a predicted class. Consider the following pair of such prompts we might want to choose between.
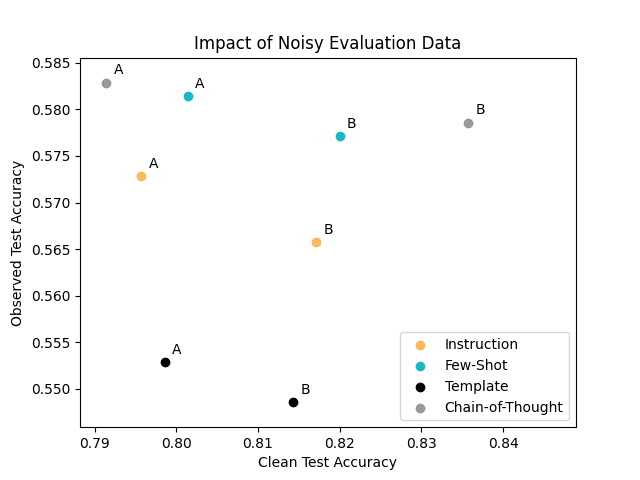
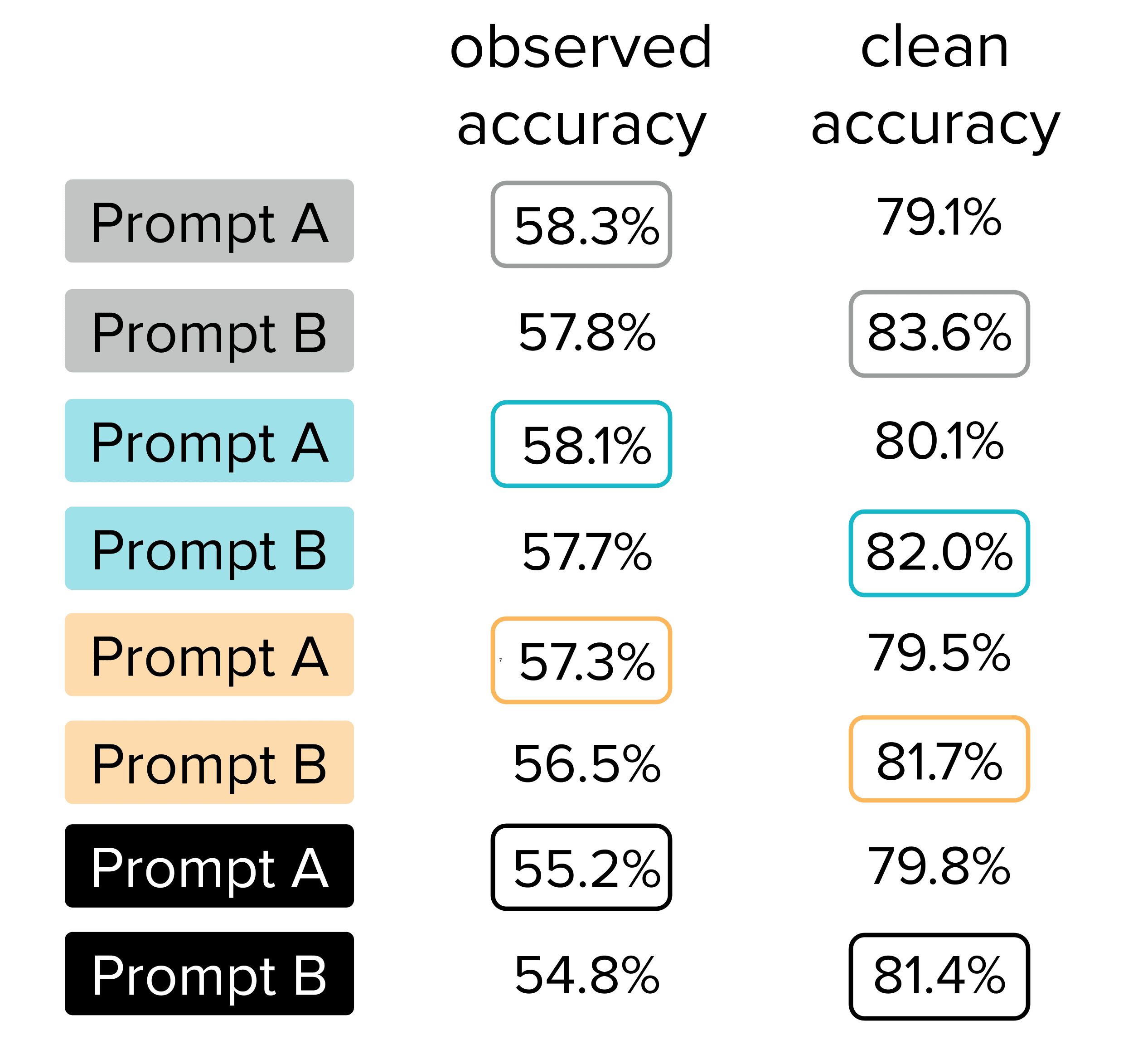
Results for various types of prompts
Beyond chain-of-thought, we also evaluated the classification performance of the same FLAN-T5 LLM with these three additional types of prompts. Plotting the Observed Test Accuracy vs. Clean Test Accuracy achieved with all of these prompts below, we see many pairs of prompts that suffer from the same aforementioned problem, where relying on Observed Test Accuracy leads to selecting the prompt that is actually worse.
Based on solely the Observed Test Accuracy, you would be inclined to select each of the “A” prompts over the “B” prompts amongst each type of prompt. However, the better prompt for each of the prompt types is actually prompt B (which has higher Clean Test Accuracy).
Each of these prompt pairs highlights the need to verify test data quality, otherwise, you can make suboptimal decisions due to data issues like noisy annotations.
Improving Available Test Data for More Reliable Evaluation
Hopefully the importance of high-quality evaluation data is clear. Let’s look at one way to algorithmically assess your available (possibly noisy) test set, in order to diagnose issues that can be fixed to obtain a more reliable version of the same dataset (without having to collect many additional human annotations). Here we use Cleanlab Studio, a no-code AI solution to assess data quality, to check our test data and automatically estimate which examples appear to be mislabeled. We then inspect only these auto-detected label issues and fix their labels via Cleanlab Studio’s interface as needed to produce a higher-quality version of our test dataset. We call model accuracy measurements made over this version of the test dataset, the Cleanlab Test Accuracy.
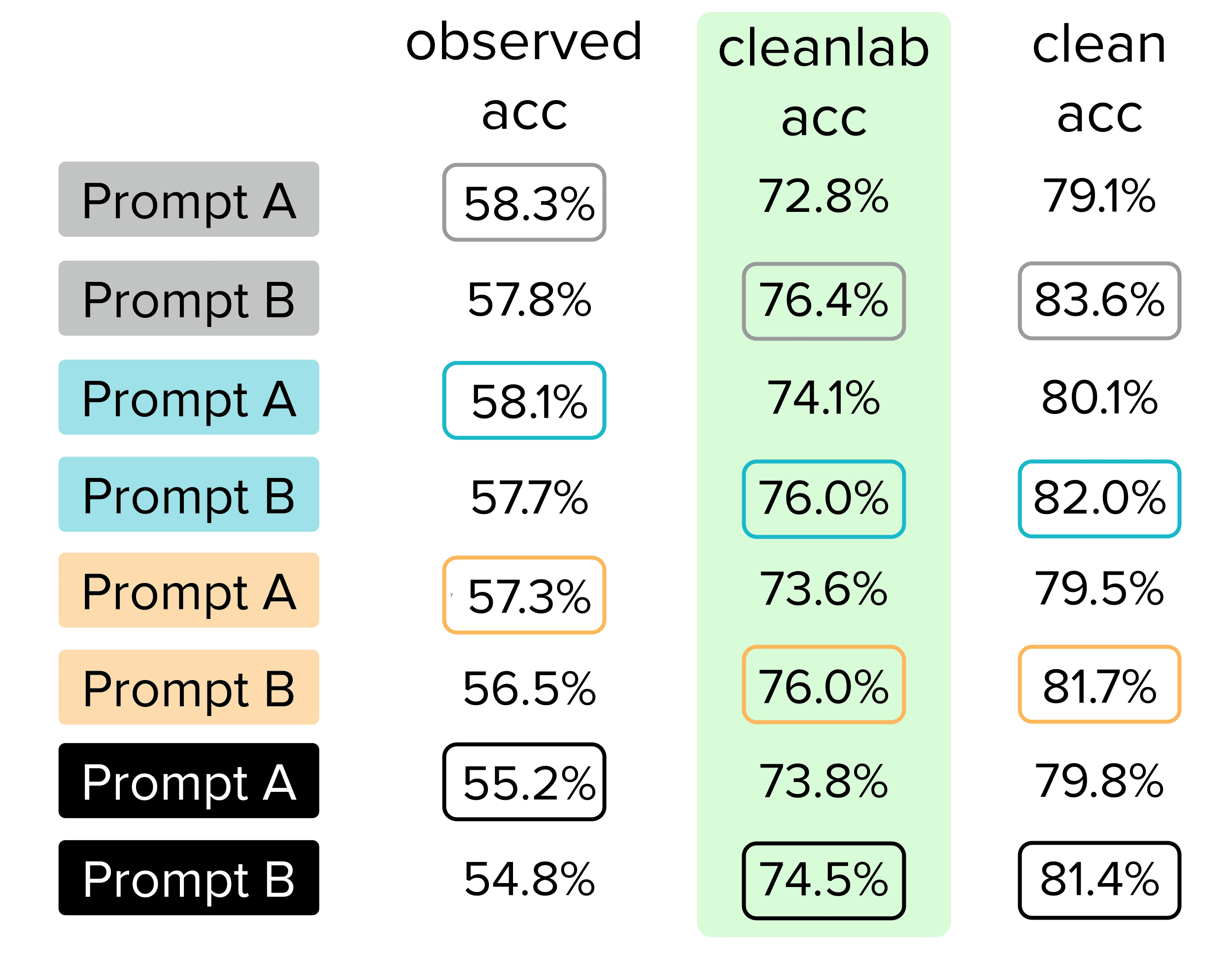
Using this new Cleanlab-corrected test set for model evaluation, we see that all of the B prompts from before now properly display higher accuracy than their A counterparts. This means we can trust our decisions made based on the Cleanlab-corrected test set to be more reliable than those made based on the noisy original test data.
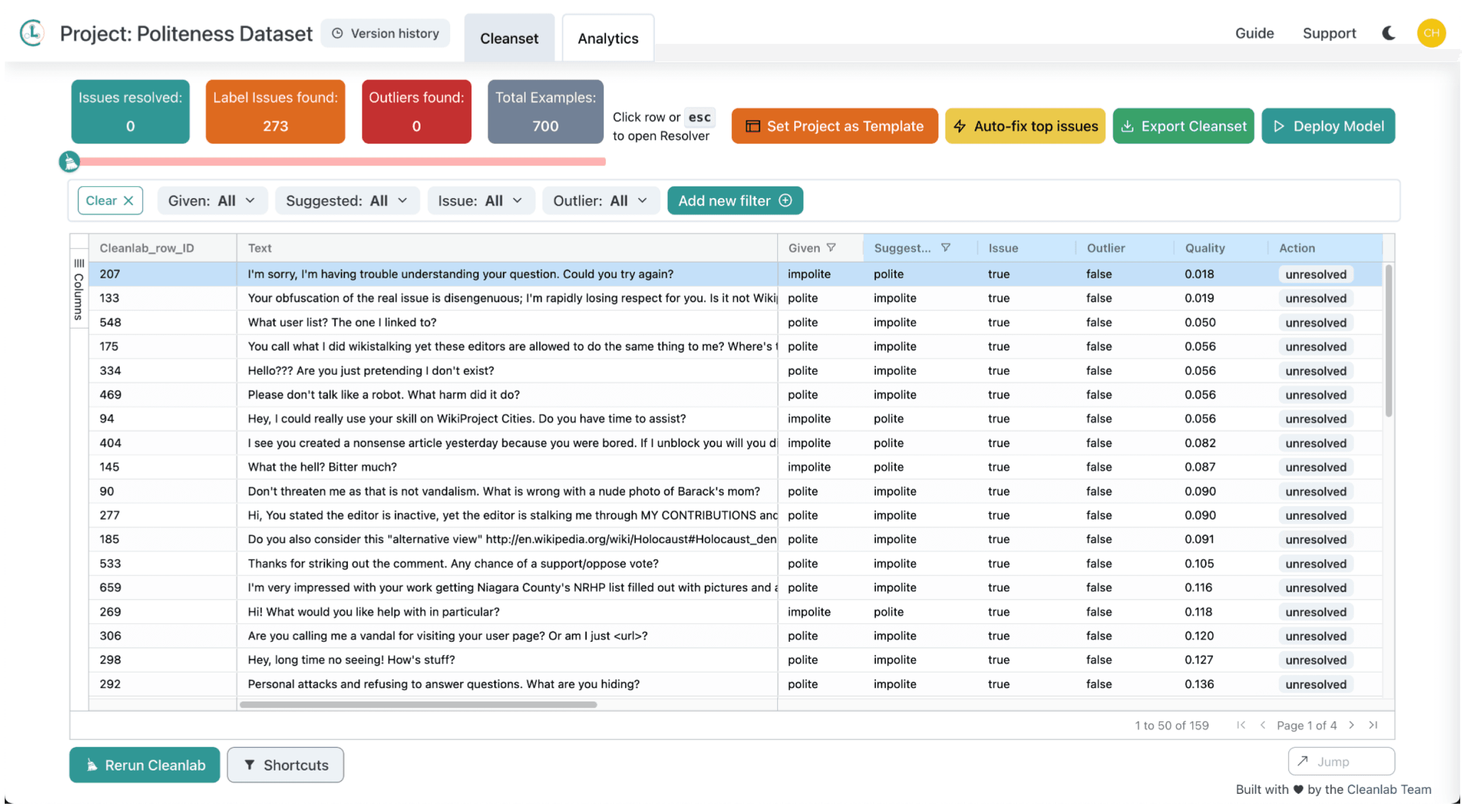
You don’t always need to spend the time/resources to curate a “perfect” evaluation set — using solutions like Cleanlab Studio to diagnose and correct possible issues in your available test set can provide high quality data to ensure optimal prompt and model selections.
Next Steps
- Easily ensure reliable test (and training) data with Cleanlab Studio!
- If you are interested in building AI Assistants connected to your company’s data sources and other Retrieval-Augmented Generation applications, reach out to learn how Cleanlab can help.
- Join our Community Slack to discuss using AI to assess the quality of your data.
- Follow us on LinkedIn or Twitter for updates on new data quality algorithms.