What are the most common data quality issues? This guide looks at data quality issues, how they arise, and how you can fix bad data today.
The average company’s data volume will grow by 63% monthly. As this expansion happens, it’s easy to make errors and succumb to potentially disastrous data quality issues. Luckily, knowing about these common problems can help you improve data quality and stay on track.

Here, we’re going to talk about some common problems that companies face when collecting, storing, and analyzing data. Read on to learn about the impact of these problems and how data centric AI software can help.
1. Inaccurate Data
Gartner states that low-quality data costs the average enterprise about $12.9 million annually.
Inaccurate data is often caused by human error. People manually enter data into the system such as misspelled customer names and addresses with incorrect zip codes. They may also enter bad analytical data such as conversion percentages for ad campaigns, sales figures, expense reports, and lead conversions.
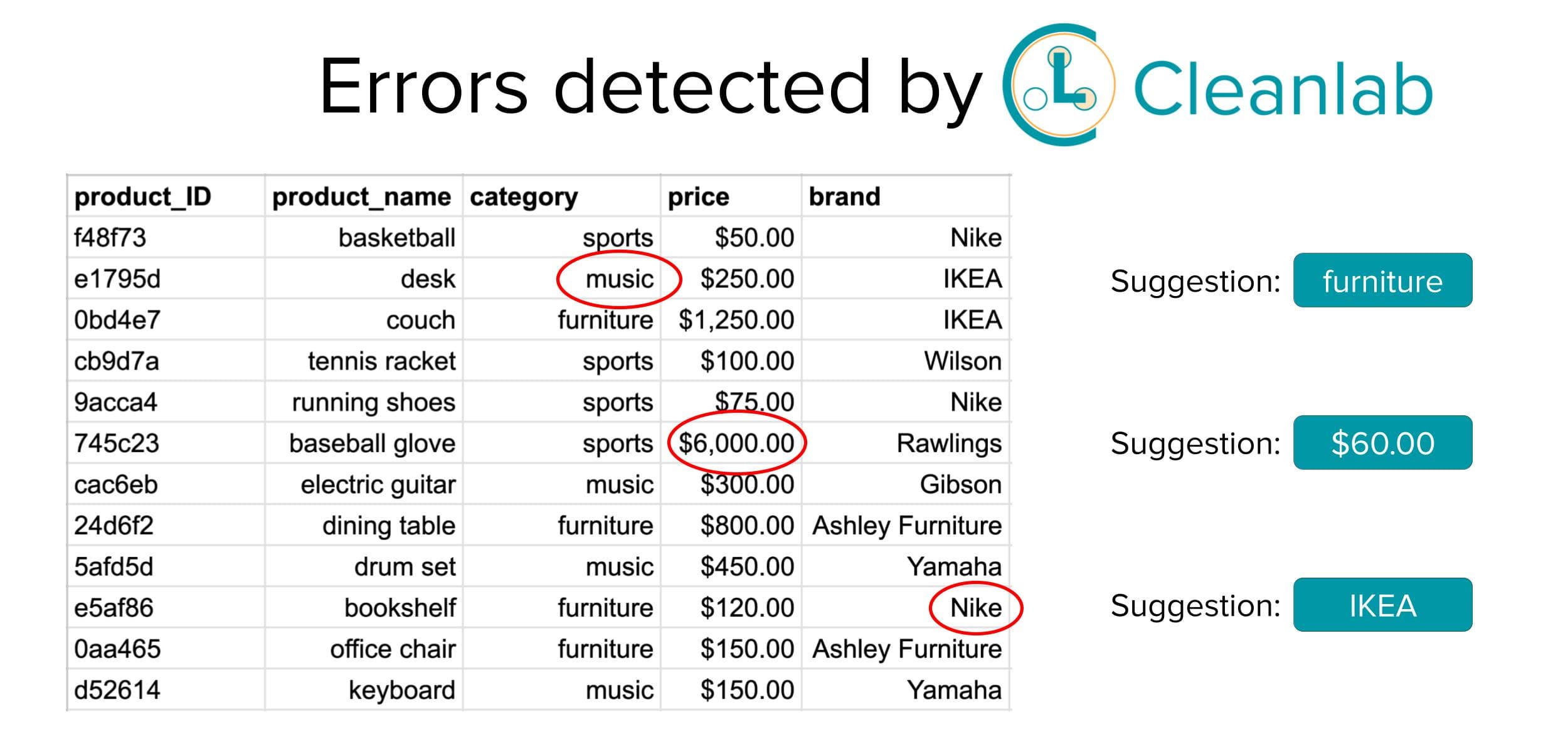
Your organization will have useless information that makes it impossible to contact clients or leads. Even worse, you’ll be constructing marketing campaigns and planning future projects based on incorrect data. This costly waste of time means poorly constructed business plans and ill-defined future company objectives.
Label Issues
Data labeling is important because it helps to categorize and contextualize raw data. This data can be text files, images, videos, table data, audio, etc.
Labeling makes it easier for users to find specific data they’re looking for. The process is also important for machine learning because the models can learn from labels. When the model makes a judgment about labeled data, it can perfect its tagging system and help you stay organized.
Unfortunately, many enterprises struggle with label issues. Some common ones include:
- Incorrect labels (e.g. tagging a picture of a dog as ‘cat’)
- Non-specific labels (e.g. tagging a picture of a dog as ‘animal’ rather than ‘dog’)
- Outdated labels that no longer describe updated data points

Luckily, Cleanlab Studio, a no-code AI data correction tool, works to find label issues in machine learning data. It will alert you to problems so that you can make necessary corrections. Better yet, it can also automatically fix issues on its own so you don’t need to spend time and money on manually fixing poorly-labeled data. While other data quality tools only work for structured tabular datasets, Cleanlab Studio can analyze structured tabular data as well as unstructured image and text data.
Low Quality Data
Low-quality data refers to information that is incorrect, outdated, or irrelevant, which can lead to significant issues in decision-making and operational efficiency. This type of data can arise from various sources including human error during data entry, poor data collection methods, or even due to technical errors in data processing systems.
Examples of low-quality data include inaccurate measurements, outdated records, and data that does not accurately reflect the current state or behavior of the subject it represents.
To combat low-quality data, companies can implement rigorous data validation processes, use data correction tools, and regularly update their datasets to ensure relevance. It’s also critical to have a well-defined data governance policy that outlines the procedures and responsibilities for maintaining data quality across the organization. Furthermore, employing machine learning and AI algorithms can help in identifying and rectifying anomalies or patterns that indicate low-quality data.
2. Incomplete Data
Incomplete data is also an issue. Sometimes, there will be data records that are mostly accurate but missing key pieces. This might mean an address with no zip code or a client’s first name with no last name.
When this happens, it will be impossible to contact clients. If errors then extend to incomplete datasets about conversions, products, developing projects, or marketing campaigns, you might wind up with a flawed business analysis, too.
Luckily, all of these problems are easily preventable with an AI-driven data management strategy. AI software can help keep your data sets error-free by showing you auto-detected incorrect values. You’ll be able to change this information and the metadata associated with it including annotations and image tags.
3. Duplicates and Near Duplicate Information
Most companies gather and use data from multiple channels. Corporate databases, social media, payment logs, ad campaign metrics, and more merge together for a holistic picture. When people manually integrate this data, it’s only natural that there will be some duplicate information or near-duplicate fields.

This is problematic because there will be several different variations of the same record. People assessing it will get incorrect insights. Skewed analytical outcomes also mean a more difficult time optimizing business plans, processes and workflows, and customer outreach.
Duplicate information also slows down the process of data analysis. Those assessing it manually will take longer to sort through information to find relevant data. Automated analysis will go slower when tools are bogged down with duplicated data.
Luckily, Cleanlab provides AI solutions that identify (near) duplicate information and keep data sets brief and reliable. There won’t be any unnecessary figures bringing down averages or incorrect assessments when looking at information as a holistic unit.
4. Outliers
Any data set will naturally have unusual values called ‘outliers.’ While they’re technically correct data, they can massively distort datasets and skew them in an odd direction. Statistical analyses will be incorrect when one-time anomalies are included in full-set analyses.

Outliers aren’t all bad. You should take note of them because they can give you information about the subject area sometimes. You just need to understand if they exist in your data so that you can deal with them accordingly. Cleanlab Scientists have spent years researching and designing the best outlier detection algorithms that outperform common SOTA methods.
Using these algorithms, AI solutions like Cleanlab Studio can sift through your data and alert you to the presence of outliers. You can then remove them and get a more accurate overall picture. This will ensure that your assessments are spot-on so you can make the right data-backed decisions.
5. Formatting Inconsistencies
Almost every piece of data can be formatted in several different ways. Consider, for example, a form with employees’ basic personal information on it. They may need to add their name, birthday, gender, and social security number to the sheet.
It’s important that these facts are displayed in a consistent order. The name should always be first, then the birthday, then the gender, then the SSN. There should be no variation between the employees.
This ensures that data is easy to read and access. Of course, this is a very simple example; when working with larger data sets or more technical information, consistent formatting is even more critical.
You also need to standardize all units of measurement. If you’re using the metric system, you can’t randomly start measuring one thing in inches and feet. If you’re using Fahrenheit, there shouldn’t be any Celsius information in your database.
Top-notch data centric AI can help you identify inconsistencies and rectify them in moments.
In many cases, integrating data from two or more different systems is the reason that formatting becomes wonky. It’s important to choose one format and convert everything into that format.
AI technologies can do this easily and save time on manual data conversion. This reduces the likelihood of mistakes and makes formatting and organization smoother.
6. Storing Useless Data
Many enterprises store useless data on their servers. This doesn’t just mean that there are unnecessary data sets in your bases. It also might mean that you have data that isn’t being used or has been sitting there so long that it’s irrelevant to today’s operations.
Dark data is information that a business collects but doesn’t actively use. About 80% of all data in existence is dark data, and most companies that are holding onto it don’t even know that it’s there. But it is, and it’s taking up storage space and costs for your company.
Many businesses also don’t erase old data in a timely manner, and it sits on servers until it’s inaccurate. When this information doesn’t age well and organizations attempt to use it after it’s gone stale, they operate on outdated insights. This means that these enterprises are marketing to the wrong audiences, contacting leads incorrectly, and creating marketing plans that don’t work for 2023 consumers.
A good data centric AI software can help you identify dark and stale data. You’ll be able to erase it and save on storage costs. You also may not need to run as many servers, which can save energy and lower your utility bills.
Orphaned data is just as big a problem as dark data and stale data. However, it’s not hidden or outdated. It’s just not usable in its current form even if your business knows where it’s held.
Generally, this happens because it’s not compatible with existing systems and applications. It’s unable to be converted into a usable format easily and run on computers and databases.
Data management software finds orphaned data, figures out why the formatting is inconsistent, and tells you how you can turn it into usable information.
7. Data Drift
Data drift is the change in model input data that leads to deterioration in model performance over time. It is a common challenge in machine learning and analytics where the statistical properties of the model inputs shift away from the training set distributions due to changes in the real-world environment.
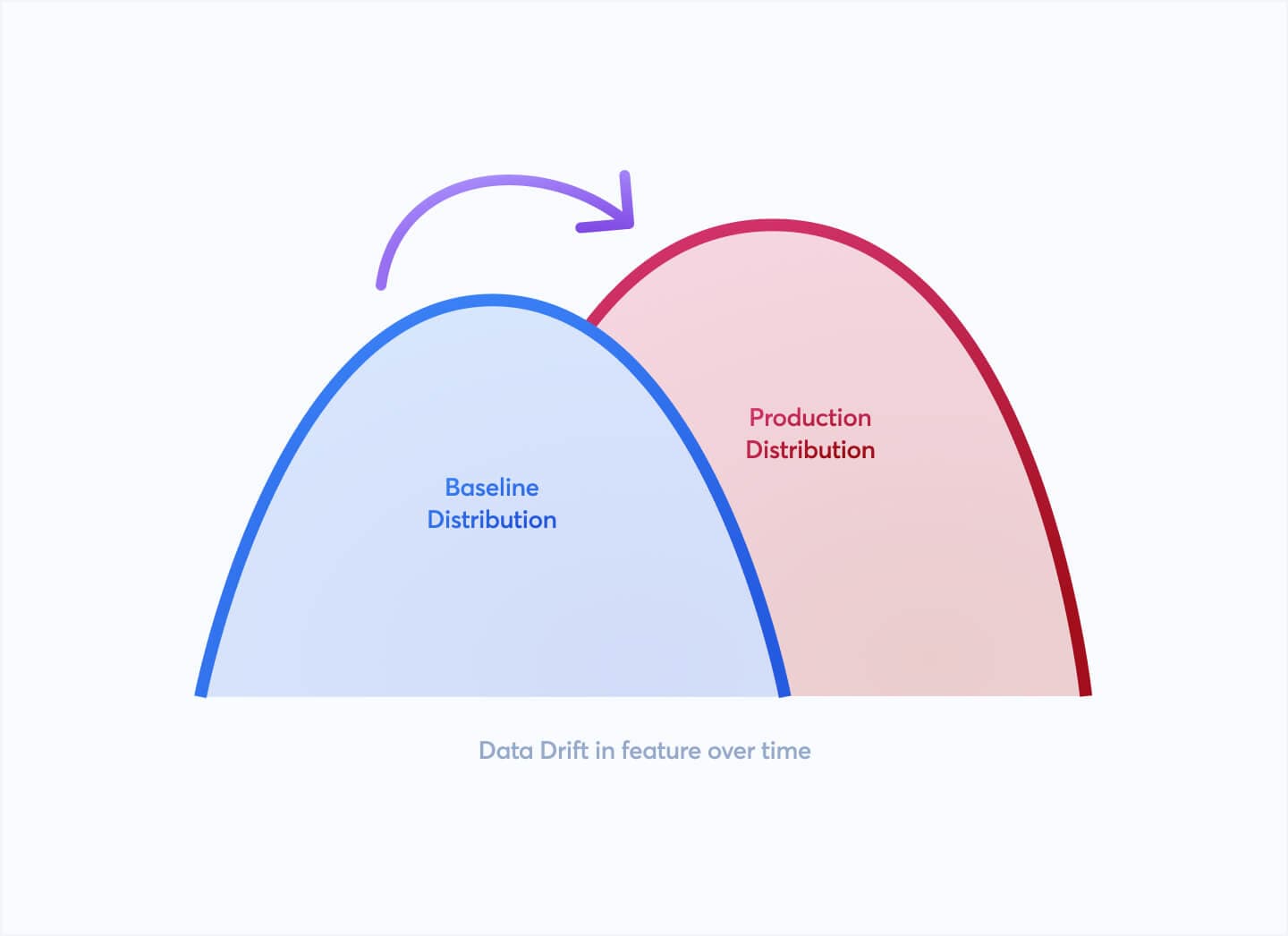
For instance, consumer behavior might evolve, economic conditions may change, or sensors collecting data might degrade, leading to data that no longer reflects the conditions under which the model was originally trained.
To detect and mitigate data drift, dedicated tools must be in place to continuously evaluate the performance of data-driven models and the characteristics of the input data. Once drift is detected, models may need to be retrained with new data that reflects current conditions, or a model updating strategy might need to be employed to adapt to the changes.
Data centric AI tools can facilitate this by providing insights into how data is shifting and suggesting the necessary adjustments to maintain model accuracy and reliability.
8. Unsafe Data (toxic language, NSFW images)
Unsafe data includes any type of information that is inappropriate, offensive, or harmful, such as toxic language in text or not-safe-for-work (NSFW) images. This category of data can have serious implications for companies, from creating a hostile work environment to damaging a brand’s reputation if such content is inadvertently used or exposed.
Machine learning models, particularly those involved in social media monitoring, content moderation, and user-generated content platforms, need to be trained to detect and filter out such data effectively.
To address unsafe data, companies can deploy content moderation tools that utilize advanced image and text recognition technologies to identify and remove inappropriate content. AI-driven solutions can be trained on vast datasets of harmful content to understand the nuances of language and visual cues that distinguish safe from unsafe content.
Implementing these tools helps to ensure a safe user experience, maintain regulatory compliance, and uphold company standards of decency and professionalism.
Next Steps
Cleanlab Studio is the fastest Data-Centric AI platform to turn messy raw data into reliable AI/ML/Analytics with little to no code. Try it to see why thousands of engineers, data scientists/analysts, and data annotation/management teams use Cleanlab software to algorithmically improve the quality of their image/text/tabular datasets.

- Get started with Cleanlab Studio for free!
- Join our Community Slack to discuss how you’re practicing Data-Centric AI and learn from others.
- Follow us on LinkedIn or Twitter to stay up-to-date on new techniques being invented in Data-Centric AI.