The cornerstone of any successful machine learning (ML) model deployment is the quality of the underlying data. Uncover how to refine and capitalize on even the most complex datasets to empower your ML deployment with actionable insights.
In the realm of machine learning, the phrase “garbage in, garbage out” rings particularly true. Data doesn’t merely occupy storage space; it forms the foundation upon which machine learning models are built and refined. By harnessing the full potential of high-quality data, businesses can transform their approach to analytics and decision-making.

Data storytelling transcends beyond mere numbers to weave narratives that drive strategic business decisions. It enriches communication, sharpens insights, facilitates customer segmentation, and propels business growth and scalability.
For those ready to elevate their machine learning deployment, the journey begins with securing reliable, well-curated datasets. Read on to learn how enhanced data strategies can revolutionize your machine learning initiatives.
Define Your Goals
Before diving into machine learning deployment, it’s essential to delineate your business objectives. Whether it’s to refine financial forecasting or to gain deeper insights into consumer behavior, knowing your end goal is paramount in guiding your machine learning journey.
Clear objectives set the stage for identifying the types of data labels that will train your AI to deliver the insights necessary to achieve your business targets.
For example, if discerning the most effective marketing channels is your goal, labels indicating different social media platforms could illuminate the sources driving your traffic. Conversely, if your focus is on sales data to guide financial decisions, labels could range from top-selling to low-demand products.
Effective Algorithm Training
The journey of machine learning begins with simple, human-crafted algorithms that prioritize straightforwardness and cost efficiency.
After these initial algorithms are in place, engineers can then devise more intricate algorithms. The complexity and sophistication of these algorithms are pivotal in enabling AI to process and utilize data with greater efficacy. Advanced machine learning capabilities include sentiment analysis, visual data representation, and strategic use of aggregated data to meet your business objectives.
Accessing reliable data is crucial for properly training machine learning algorithms. Developers are usually required to meticulously annotate and categorize each dataset during data labeling. This process educates machine learning models on how to classify and retrieve data, thereby enhancing their functional accuracy. A well-categorized dataset not only makes information readily accessible for human analysis but also empowers AI to tailor recommendations on data utilization.
Luckily, no-code platforms exist to curate high quality datasets with just a few clicks.
Implement High-Quality Deployment Tools
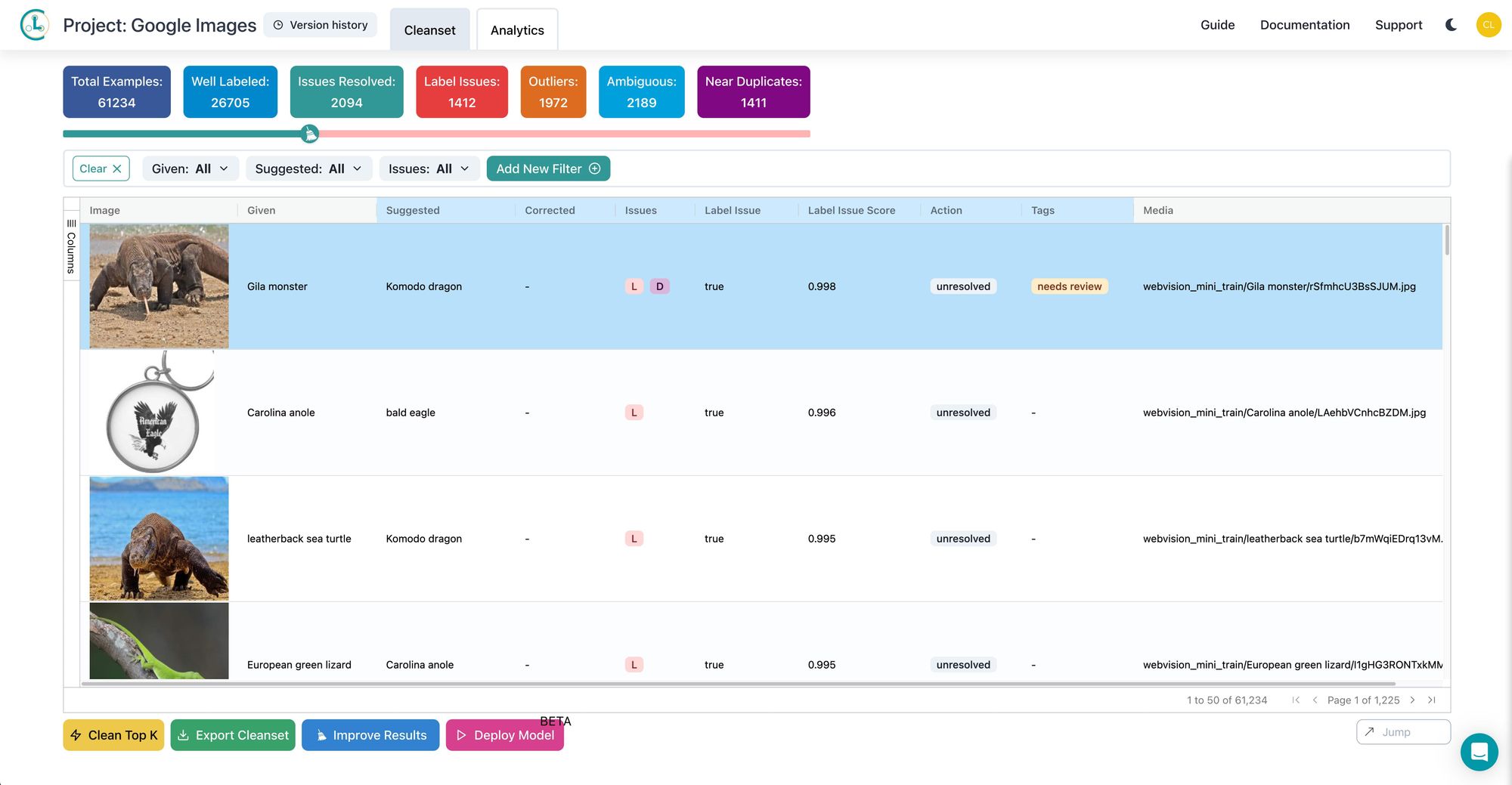
Choosing top-notch tools for model deployment is critical. Services like Cleanlab Studio enable swift and effective deployment of ML/AI models, simplifying the integration with your data systems.
Cleanlab’s technology can harness even the most unstructured datasets, with labeling software that autonomously categorizes data and predicts suggested labels. This approach is user-friendly, requiring no coding expertise, thus making it accessible to a broad range of businesses.
The integration is also accessible via Python API which means little to no overhead integrating it with your already existing pipelines. Cleanlab specializes in providing tailored solutions that align with industry-specific standards, compliance requirements, and best practices.
This strategy guarantees the delivery of real-time predictions that can be readily applied to daily operations, enhancing your capacity to meet the specific needs of your clientele.
Data Labeling and Anomaly Detection
In any dataset, data issues like label errors, outliers, and ambiguous examples are very common. Identifying these problems is crucial as they often do not reflect the underlying data trends.

Data labeling is a crucial step in machine learning deployment, involving the tagging of raw data with informative labels that add context and aid in categorization. This enables machine learning models to accurately interpret and analyze data, which is essential for training the AI to recognize and disregard outliers, thus ensuring more accurate and reliable metrics. Such labeling enhances your business’s quality assurance, delivering dependable insights into customer behaviors and preferences.
Unfortunately, data collected by humans is susceptible to a host of issues that can compromise the integrity of machine learning models. Human error, subjective judgments, and inconsistencies in data entry are common pitfalls that lead to label errors and ambiguous examples. These inaccuracies can stem from a variety of sources, such as misinterpretation of data, lack of standardization in the data collection process, and the inherent bias that individuals may bring to the task.
The goal is to curate a dataset that reflects the true signal within the data, free from the distortions that these common problems can cause. Achieving this level of data quality is not only about improving the performance of machine learning models but also about ensuring that the decisions based on these models are sound and reliable.
Gathering and Utilizing Feedback
Gathering customer feedback stands as a cornerstone practice for refining machine learning models, serving as a direct conduit to the user experience and expectations. This feedback, rich with insights, not only reflects the customers’ needs and preferences but also highlights the practical aspects where the model may underperform or excel.
By integrating this feedback into the training data, machine learning algorithms can be fine-tuned to better align with real-world usage, ensuring the models evolve in sync with dynamic customer behaviors and market trends. This continuous loop of feedback and enhancement is key to developing robust, responsive, and user-centric AI solutions that deliver tangible value to both the business and its clientele.
Periodic Model Evaluation
While ML/AI models are designed for autonomy, regular evaluations are paramount to ensure ongoing accuracy. Periodically reviewing the model’s performance ensures that data labeling is accurate and that the AI is improving its processes.
Correcting any inconsistencies by retraining the model allows it to learn from its errors, preventing future misclassifications and maintaining the integrity of your data.
This proactive oversight is crucial for preserving data reliability, which underpins informed business decisions.
Elevate Your Enterprise with Machine Learning
Substandard data can obstruct business progress, but strategic machine learning deployment unlocks valuable insights and fosters achievement of business aspirations.
With a clear understanding of AI’s potential and its impact, it’s time to harness data-centric algorithms and platforms to connect with your target audience more effectively.
Cleanlab Studio is the fastest Data-Centric AI platform to turn messy raw data into reliable AI/ML/Analytics with little to no code. Try it to see why thousands of engineers, data scientists/analysts, and data annotation/management teams use Cleanlab software to algorithmically improve the quality of their image/text/tabular datasets.
- Get started with Cleanlab Studio for free!
- Join our Community Slack to discuss how you’re practicing Data-Centric AI and learn from others.
- Follow us on LinkedIn or Twitter to stay up-to-date on new techniques being invented in Data-Centric AI.